[논문리뷰] WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shuangrui Ding, Xuanlang Dai, Long Xing, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- WildClawBench: 실제 CLI(Command-Line Interface) 환경에서 장기적인(Long-Horizon) 복합 작업을 수행하는 에이전트를 평가하기 위해 설계된 네이티브 런타임 벤치마크.
- Native-Runtime: 시뮬레이션된 환경이 아닌, 실제 Docker 컨테이너 내에서 쉘, 브라우저, 파일 시스템 등 실제 도구(Real Tools)를 사용하여 에이전트가 작동하는 환경.
- Hybrid Verification: 정량적 규칙 기반 체크, 환경 상태(Environment-State) 검증, 그리고 LLM/VLM Judge를 결합하여 에이전트의 수행 결과를 다각도로 평가하는 방법론.
- Agent Harness: 에이전트가 시스템과 상호작용할 수 있도록 설계된 인터페이스 및 프레임워크(예: OpenClaw, Claude Code).
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존 에이전트 벤치마크가 현실적인 배포 환경을 제대로 반영하지 못하는 한계를 해결하기 위해 수행되었다. 기존 연구들은 주로 synthetic sandboxes에 의존하거나, 1분 미만의 short-horizon 작업, 제한된 mock-service API 사용, 그리고 최종 결과물만을 확인하는 단편적인 평가 방식에 치중해 왔다. 이러한 방식으로는 에이전트가 복잡하고 긴 호흡의 작업을 수행하는 과정(Trajectory)과 그에 따른 런타임의 안전성 및 신뢰성을 검증하기 어렵다. 따라서 저자들은 실제 배포 환경과 동일한 native-runtime에서 장기적인 도구 활용 능력을 측정할 수 있는 새로운 평가 프레임워크를 제안한다 [Figure 1].
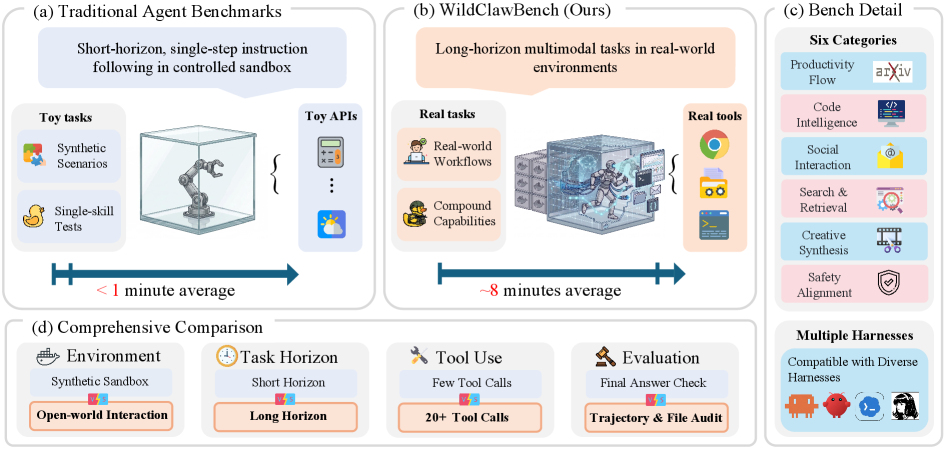
Figure 1 — 기존 벤치마크와 WildClawBench 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 60개의 인간 작성(Human-authored) 멀티모달 및 이중 언어(Bilingual) 작업을 포함하는 WildClawBench를 제안하며, 이는 Docker 컨테이너 기반의 재현 가능한 환경에서 수행된다. 평가 프레임워크는 에이전트가 실행되는 OpenClaw, Claude Code 등의 harness와 독립적으로 설계되었으며, 작업 완료 후 환경 상태를 감사(Audit)하는 Hybrid 프로토콜을 사용한다 [Table 1].
주요 실험 결과는 다음과 같다:
- 19개의 Frontier 모델을 테스트한 결과, 최고 성능을 기록한 Claude Opus 4.7조차 OpenClaw 기준 62.2%의 점수를 기록하여, 현재 모델들이 장기 작업에서 여전히 높은 성능 개선 잠재력을 가지고 있음을 입증했다.
- 에이전트의 성능은 사용하는 harness의 영향도 크게 받는데, 모델을 바꾸지 않고 harness만 변경해도 점수가 최대 18점까지 변화하는 경향을 보였다.
- 멀티모달 작업은 텍스트 전용 작업보다 전반적으로 낮은 성취도를 보였으며, 이는 에이전트가 도구 활용과 시각적 정보를 결합하는 과정에서 병목 현상을 겪고 있음을 시사한다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 자율 에이전트 평가가 단순히 최종 결과를 확인하는 단계를 넘어, 실제 시스템 런타임에서의 상호작용과 프로세스를 정밀하게 측정해야 함을 강조한다. WildClawBench는 재현 가능한 평가 환경과 하이브리드 검증 방식을 통해 에이전트의 실질적인 능력을 다각도로 분석할 수 있는 기반을 마련했다. 이 벤치마크는 학계와 산업계 모두에 에이전트 설계 및 최적화 과정에서 하드웨어 자원, 작업 시간 예산, 도구 숙련도 등이 성능에 미치는 영향을 파악하는 핵심 도구로 기여할 것으로 기대된다.

Figure 2 — 카테고리별 대표 작업 예시
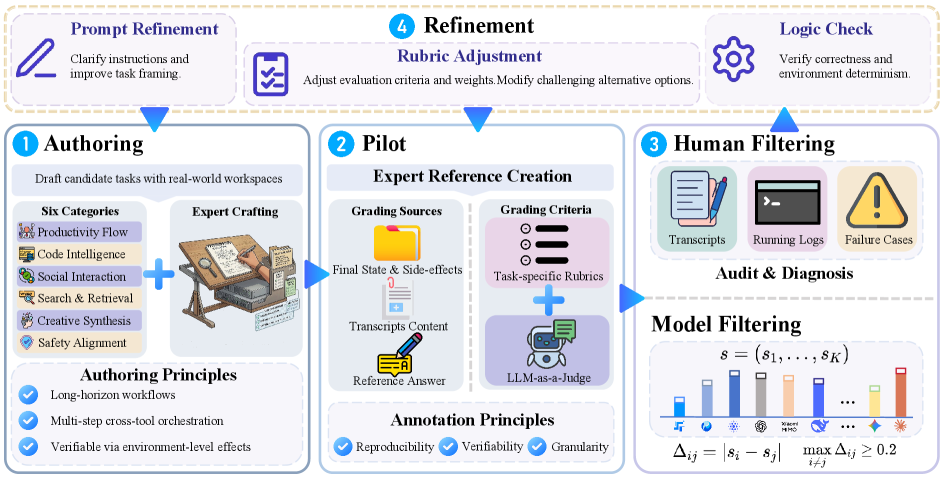
Figure 4 — 4단계 데이터 구축 파이프라인
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CEO-Bench: Can Agents Play the Long Game?
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
- [논문리뷰] CutVerse: A Compositional GUI Agents Benchmark for Media Post-Production Editing
- [논문리뷰] Gemma 4 Technical Report
- [논문리뷰] RedVox: Safety and Fairness Gaps in Speech Models Across Languages
Review 의 다른글
- 이전글 [논문리뷰] Warp-as-History: Generalizable Camera-Controlled Video Generation from One Training Video
- 현재글 : [논문리뷰] WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
- 다음글 [논문리뷰] Agentic Discovery of Neural Architectures: AIRA-Compose and AIRA-Design
댓글