[논문리뷰] MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ruijie Zhou, Fanxu Meng, Yufei Xu, Tongxuan Liu, Guangming Lu, Muhan Zhang, Wenjie Pei
1. Key Terms & Definitions (핵심 용어 및 정의)
- DSA (DeepSeek Sparse Attention): 고성능 fine-grained sparse attention 방식으로, learned token-wise indexer를 사용하여 매 쿼리마다 prefix token 중 관련성이 높은 top-k 토큰을 선택하는 기술.
- Indexer: 입력된 prefix 토큰들의 관련성을 점수화하여 main attention 연산에 참여할 토큰 후보군을 선별하는 모듈.
- Router: block-level 통계를 활용하여 복잡한 전체 토큰 스캔 대신 쿼리에 적합한 소수의 active head만을 선택적으로 활성화하는 MISA의 핵심 컴포넌트.
- MISA (Mixture of Indexer Sparse Attention): DSA의 indexer를 MoE(Mixture of Experts) 방식으로 최적화하여, head-axis 라우팅을 통해 연산 효율성을 극대화한 기법.
- Sparse MLA (Multi-Head Latent Attention): 선택된 token set에 대해서만 attention을 수행하여 연산 비용을 𝒪(L²)에서 𝒪(Lk)로 줄이는 연산 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Long-context LLM Inference에서 indexer 연산이 전체 비용의 지배적인 비중을 차지하는 문제를 해결하기 위해 MISA를 제안한다. 기존 DSA 방식은 높은 성능을 위해 64개와 같은 많은 수의 indexer head를 사용하며, 매 쿼리마다 모든 prefix token을 모든 head로 스캔해야 하므로 긴 문맥에서 막대한 연산 비용이 발생한다 [Figure 1]. 기존 연구들인 HISA나 IndexCache는 token-axis에 집중하여 연산을 효율화하려 했으나, head-axis의 복잡도는 여전히 해결하지 못했다. 따라서 본 연구는 head-axis 라우팅을 통해 특정 쿼리에 필요한 핵심적인 head만을 선택적으로 연산함으로써 효율성을 달성하고자 한다.
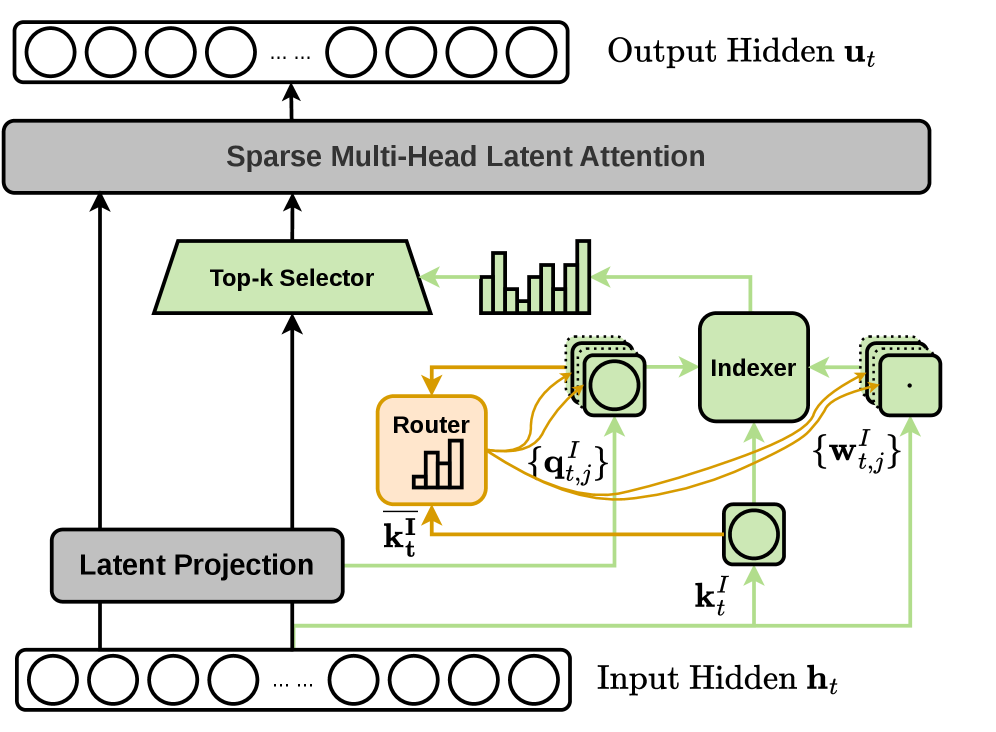
Figure 1 — DSA와 MISA 인덱서 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 indexer의 head들을 MoE 전문가처럼 취급하고, 가벼운 Router를 통해 query-dependent한 소수의 active head만 활성화하는 MISA 기법을 제안한다 [Figure 1]. 이 Router는 block-pooled 통계를 사용하여 계산 비용이 거의 들지 않으며, 이를 통해 기존 𝒪(HᴵL)의 복잡도를 𝒪(hL + HᴵM)으로 크게 개선하였다. 추가적으로 제안된 **MISA†**는 2단계 coarse-to-fine 방식을 사용하여, 라우팅된 후보군을 다시 original DSA indexer로 재평가함으로써 Dense 모델 수준의 정밀도를 복구한다. 실험 결과, MISA는 DeepSeek-V3.2 및 GLM-5 모델에서 추가적인 학습 없이도 기존 DSA 대비 4~8배 적은 indexer head만을 사용하면서 LongBench 지표에서 거의 동등한 성능(DeepSeek-V3.2 기준 50.85 vs 51.05)을 기록하였다 [Table 1]. 또한, NVIDIA H200 GPU 환경에서 TileLang 커널을 통해 DSA 대비 약 3.82배의 실질적인 latency 단축을 달성하였다 [Figure 3].
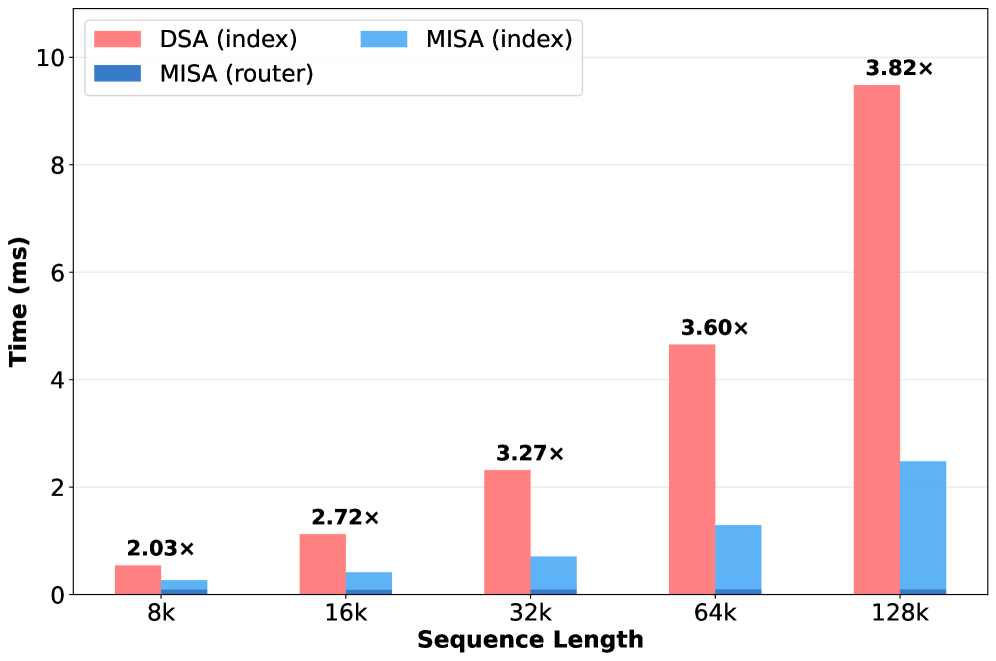
Figure 3 — 인덱서 커널 레이턴시 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 head-axis 라우팅이 fine-grained sparse attention을 위한 매우 실용적이고 효과적인 효율화 축임을 입증하였다. MISA는 추가적인 학습 없이도 기존 long-context LLM의 indexer를 드롭인(drop-in) 방식으로 대체하여 추론 성능 저하 없이 연산 속도를 대폭 개선할 수 있다. 이 연구는 대규모 long-context 환경에서 LLM의 효율적인 서비스 가능성을 높이는 데 기여하며, 향후 다양한 sparse attention 구조의 경량화 연구에 중요한 방법론적 토대를 제공할 것으로 기대된다.
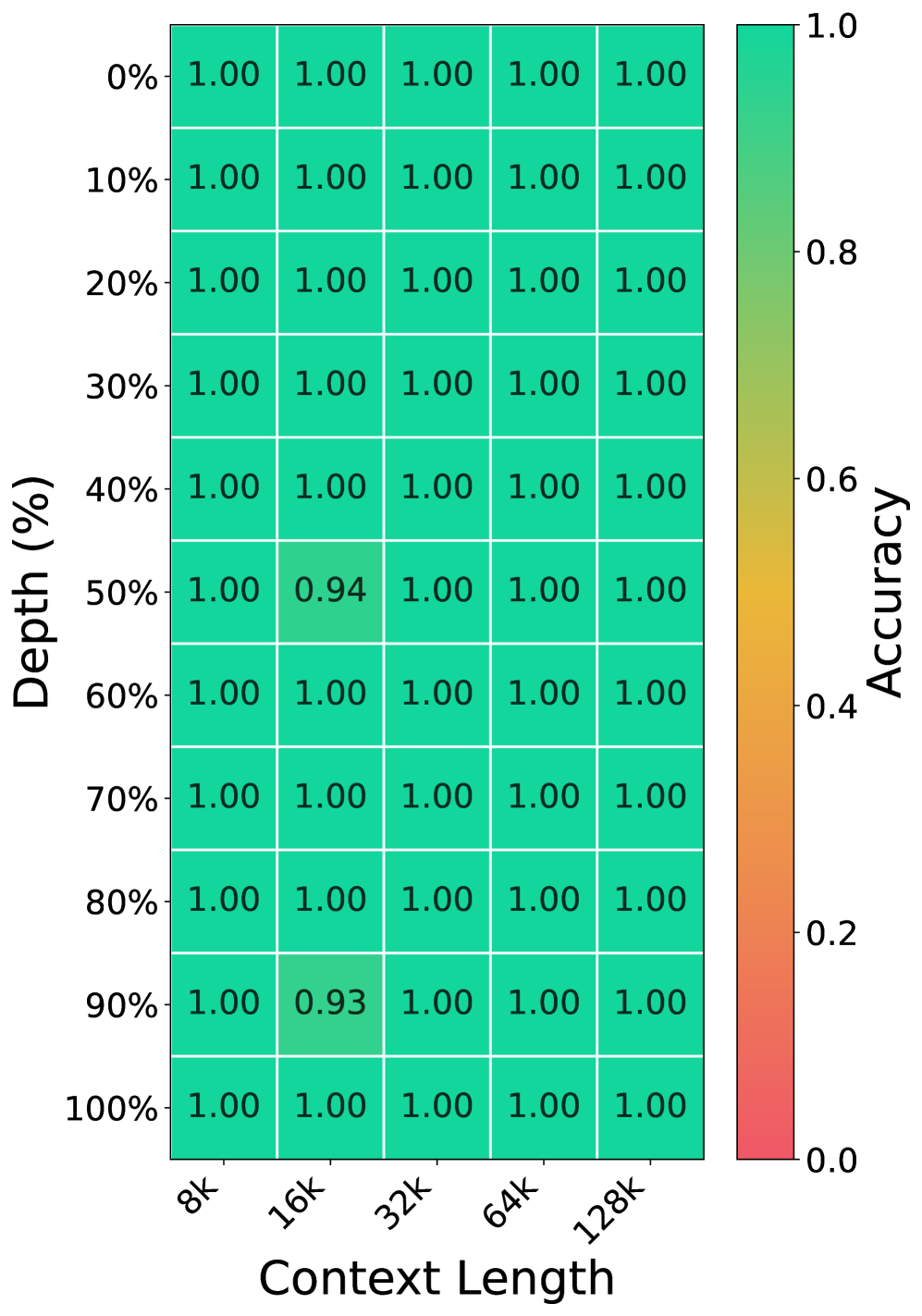
Figure 2 — NIAH 정확도 비교 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] KVpop -- Key-Value Cache Compression with Predictive Online Pruning
- [논문리뷰] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling
- [논문리뷰] ReFreeKV: Towards Threshold-Free KV Cache Compression
- [논문리뷰] FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
Review 의 다른글
- 이전글 [논문리뷰] MDN: Parallelizing Stepwise Momentum for Delta Linear Attention
- 현재글 : [논문리뷰] MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
- 다음글 [논문리뷰] MatryoshkaLoRA: Learning Accurate Hierarchical Low-Rank Representations for LLM Fine-Tuning
댓글