[논문리뷰] MatryoshkaLoRA: Learning Accurate Hierarchical Low-Rank Representations for LLM Fine-Tuning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ionut-Vlad Modoranu, Mher Safaryan, Dan Alistarh
1. Key Terms & Definitions (핵심 용어 및 정의)
- MatryoshkaLoRA: 사전에 정의된 최대 rank $R$ 내에서 모든 하위 rank(sub-rank)에 대해 독립적으로 사용 가능한 계층적(hierarchical) 저차원 표현을 학습하는 프레임워크입니다.
- AURAC (Area Under the Rank Accuracy Curve): 계층적 저차원 어댑터의 성능을 여러 rank에 걸쳐 종합적으로 평가하기 위해 저자들이 제안한 정량적 평가지표입니다.
- Diagonal Matrix $P$: 어댑터 $A$와 $B$ 사이에 삽입되어 각 rank에 대한 gradient 정보를 효율적으로 내재화(embed)하고, 훈련 시 하위 rank를 스케일링하는 핵심 구조체입니다.
- $S$: 훈련 및 추론 시 사용하는 rank들의 집합으로, 효율성을 위해 일반적으로 2의 거듭제곱(powers of two)으로 구성됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 LoRA 방식이 고정된 rank $R$에 의존하여 최적의 성능을 찾기 위해 반복적인 grid search가 필요하다는 점을 해결하고자 합니다. 기존 rank-adaptive 방법론인 DyLoRA는 훈련 과정에서 무작위로 rank를 샘플링하지만, 전체 rank 계층에 걸쳐 일관된 gradient signal을 전달하지 못해 높은 rank에서 성능이 저하되는 data-inefficient 문제를 보입니다 [Figure 1]. 이러한 문제로 인해 다수의 독립적인 adapter를 학습하거나 비효율적인 탐색 과정을 거쳐야 하는 한계가 존재합니다. 따라서 저자들은 단일 체크포인트에서 다양한 rank를 효과적으로 추출할 수 있는, 계층적 구조를 명시적으로 학습하는 새로운 프레임워크가 필요하다고 판단하였습니다.
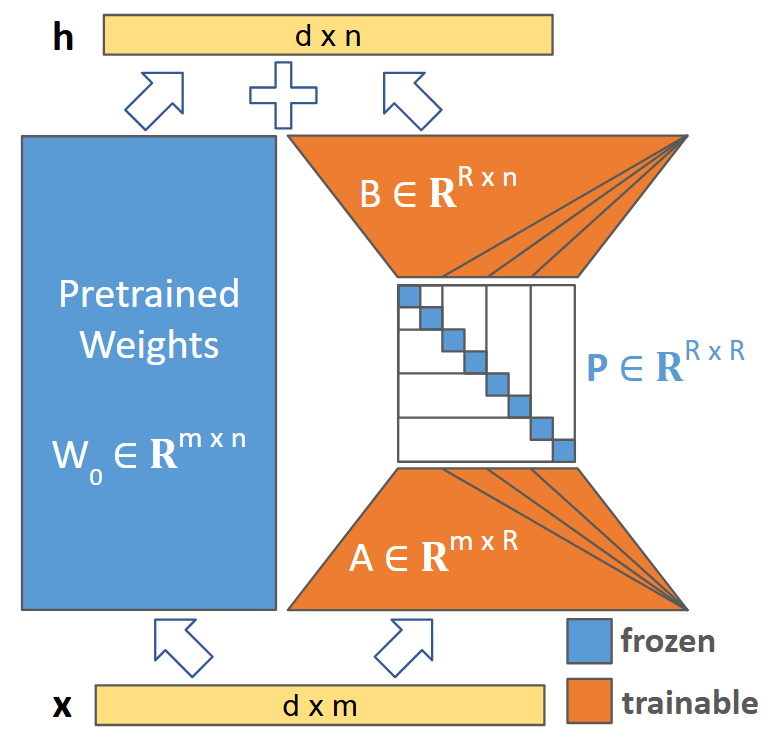
Figure 1 — MatryoshkaLoRA 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Matryoshka Representation Learning에서 영감을 받아, 고정된 대각 행렬(diagonal matrix) $P$를 LoRA 어댑터 $A$와 $B$ 사이에 도입함으로써 계층적 특징을 학습하는 MatryoshkaLoRA를 제안합니다 [Figure 1]. 이 방법은 행렬 $P$를 통해 훈련 중 모든 rank $r \in S$의 기여도를 통합하여 gradient를 계산하며, 이를 통해 하위 rank가 상위 rank 내에 독립적으로 존재하는 내포된(nested) 계층 구조를 형성합니다. 실험 결과, Llama-3.2-1B-Instruct를 GSM-8K 데이터셋에서 훈련했을 때 MatryoshkaLoRA는 기존 LoRA 및 DyLoRA 대비 높은 rank에서 최대 39%의 정확도를 기록하며 기존 baseline(약 35%)을 크게 상회하였습니다 [Table 1]. 또한, Llama-3.1-8B-Instruct 대상 Open Platypus 데이터셋 학습 실험에서도 HellaSwag 지표 기준 62.8%의 정확도를 달성하여, baseline 대비 3% 이상의 우수한 성능을 입증하였습니다 [Table 2]. 추가적으로 AURAC 지표에서도 지속적으로 높은 성능을 보이며, 다양한 computational constraint 환경에서 효율적인 성능-비용 trade-off를 제공함을 증명하였습니다 [Table 1, Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 MatryoshkaLoRA를 통해 LoRA 어댑터 내에서 효율적인 계층적 저차원 표현을 학습하는 일반화된 프레임워크를 제시하였습니다. 이 방법은 추가적인 훈련 반복 없이 단일 체크포인트에서 다양한 rank를 실시간으로 선택하여 최적의 정확도-성능 균형을 맞출 수 있게 합니다. 향후 LLM의 배포 시 하드웨어 제약에 맞춰 동적으로 rank를 조절해야 하는 생산 환경에서 큰 유연성과 비용 절감 효과를 가져올 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
- [논문리뷰] The Path Not Taken: RLVR Provably Learns Off the Principals
- [논문리뷰] Omni-AVSR: Towards Unified Multimodal Speech Recognition with Large Language Models
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
Review 의 다른글
- 이전글 [논문리뷰] MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
- 현재글 : [논문리뷰] MatryoshkaLoRA: Learning Accurate Hierarchical Low-Rank Representations for LLM Fine-Tuning
- 다음글 [논문리뷰] Mean Mode Screaming: Mean--Variance Split Residuals for 1000-Layer Diffusion Transformers
댓글