[논문리뷰] F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
링크: 논문 PDF로 바로 열기
Now I have the content. Let's extract the information systematically.
Authors: Ziyin Zhang, Zihan Liao, Hang Yu, Peng Di, Rui Wang et al. (Based on the author list provided on the paper and the "et al." instruction)
Keywords: I'll look for 5-8 relevant academic terms from the abstract and introduction.
- Multilingual Embedding
- Large Language Models (LLM)
- Matryoshka Representation Learning (MRL)
- Knowledge Distillation
- Model Pruning
- MTEB Benchmark
- Low-resource Languages
- Open-source
Part 1: Summary Body
## 1. Key Terms & Definitions
- Multilingual Embedding Models : 200개 이상의 다양한 언어에 대한 텍스트를 고차원 벡터 공간으로 매핑하여 의미적 관계를 포착하는 모델.
- Matryoshka Representation Learning (MRL) : 단일 임베딩 벡터가 여러 Granularity의 정보를 포함하도록 학습되어, 다양한 차원의 임베딩을 효율적으로 사용할 수 있게 하는 기법.
- Knowledge Distillation : 더 크고 복잡한 "Teacher" 모델의 지식을 더 작고 효율적인 "Student" 모델로 전이하는 훈련 기법.
- Model Pruning : 모델의 불필요한 파라미터를 제거하여 모델 크기를 줄이고 Inference 효율성을 높이는 기법.
- MTEB Benchmark : Text embedding 모델의 성능을 평가하기 위한 광범위한 다국어 벤치마크 (Massive Text Embedding Benchmark).
## 2. Motivation & Problem Statement 최근 Encoder-based 아키텍처에서 Decoder-based LLM embeddings로의 전환은 성능 향상을 가져왔지만, 현재 연구는 두 가지 주요 한계를 가지고 있습니다. 첫째, English-centric bias 가 만연하여, MTEB와 같은 벤치마크에서도 영어 및 중국어와 같은 High-resource languages에만 disproportionately 많은 관심이 집중되어 글로벌 유틸리티를 제공하지 못하는 모델이 많습니다. 둘째, Transparency gap 이 존재하여, Gemini-Embedding이나 Qwen3-Embedding과 같은 Top-performing 모델들이 Closed-source API로 제공되거나, Open-weight 모델이더라도 Underlying training data나 Methodology를 공개하지 않아 Reproducibility를 저해하고 Inclusive한 임베딩 시스템 구축에 대한 이해를 제한합니다. 저자들은 이러한 문제들을 해결하기 위해 F2LLM-v2를 제안하며, 특히 Underserved mid- and low-resource languages 에 대한 지원과 Computational inclusivity를 강조합니다.
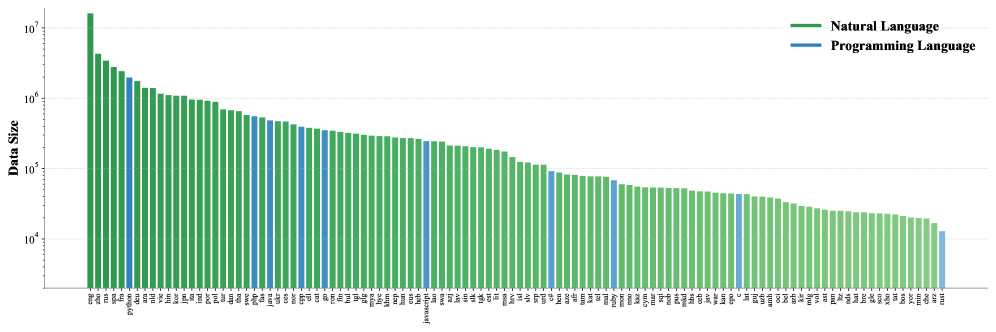
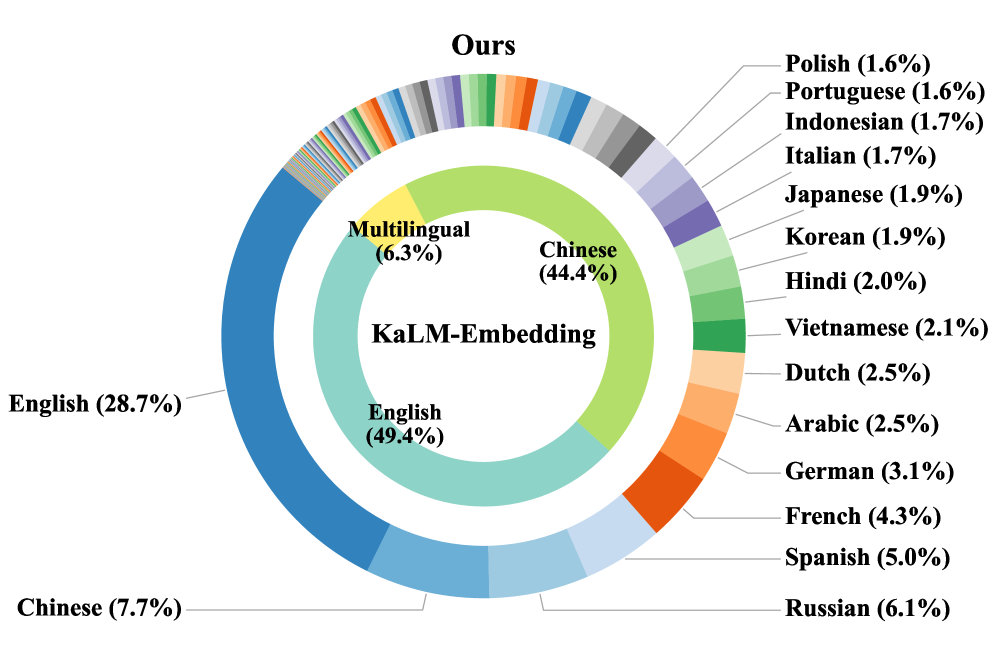
## 3. Method & Key Results F2LLM-v2는 60 million 개의 High-quality training samples로 구성된 광범위한 데이터를 활용하며, 이는 282개 의 자연어와 40개 이상의 프로그래밍 언어를 포함합니다. 데이터 큐레이션은 특정 벤치마크 최적화보다는 Real-world data availability 에 초점을 맞추어, 스페인어, 아랍어, 이탈리아어 등 MTEB에 전용 벤치마크가 없는 언어에도 상당한 양의 데이터를 포함합니다 [Figure 2, 3]. 모든 데이터는 Retrieval, Clustering, Two-way Classification의 세 가지 Canonical formats으로 통합되어 Contrastive learning framework 내에서 모델이 Versatile embedding space를 학습하도록 합니다.
제안 방법론은 Two-stage training strategy를 채택하며, 첫 번째 Stage는 Robust semantic foundation 구축에 중점을 두며 7개 의 Retrieval datasets를 사용합니다. 두 번째 Stage는 Classification, Reranking, Paraphrase detection과 같은 Downstream applications의 Nuances를 처리하는 능력을 향상시키기 위해 Task-specific instructions를 적용합니다. 또한, Qwen3 기반의 표준 Dense Transformer decoder 아키텍처를 사용하여 80M부터 14B까지 8가지 Distinct model sizes 를 제공합니다 [Table 1]. 특히, 0.6B 모델을 Pruning 하여 80M, 160M, 330M의 더 작은 모델을 생성하고, Naive training 시 발생하는 성능 저하를 완화하기 위해 Knowledge Distillation loss 를 적용합니다. 이 Knowledge Distillation 은 Student 모델의 Sequence embedding과 Teacher 모델의 Sequence embedding 간의 MSE 를 계산하여 이루어지며, Matryoshka Representation Learning (MRL) 도 두 Training stages에 모두 적용되어 최소 Matryoshka dimension은 8 입니다 [Table 1].
평가 결과, F2LLM-v2-14B는 11개의 MTEB benchmarks 에서 First rank를 달성하며 SOTA 성능을 기록했습니다. 또한, Smaller models도 Resource-constrained applications에서 이전 Frontier models 대비 뛰어난 성능을 보였습니다.
## 4. Conclusion & Impact F2LLM-v2는 Multilingual embedding 모델 연구의 중요한 진전을 나타내며, 특히 기존의 English-centric bias와 Transparency gap 문제를 해결하고자 합니다. 이 연구는 Comprehensive training data 큐레이션, Two-stage training pipeline, 그리고 Matryoshka learning, Model pruning, Knowledge distillation을 통합함으로써 Inclusive, Performant, and Efficient embedding models 를 성공적으로 제시합니다. F2LLM-v2-14B 모델이 11개 MTEB 벤치마크에서 1위를 차지 하고, 더 작은 모델들도 Resource-constrained 환경에서 뛰어난 성능을 보이는 것은 이 방법론의 Effective함을 입증합니다. 이 연구는 모든 모델, 데이터, 코드, 중간 체크포인트를 오픈 소스로 공개함으로써 재현성을 높이고 Multilingual embedding model 연구 분야의 발전을 촉진하여, 궁극적으로 보다 Inclusive한 AI 기술 미래를 위한 기반을 마련합니다.
Part 2: Important Figure Information
I need to select up to 3 figures.
- Figure 1: MTEB leaderboards performance. This shows key results.
- Figure 2: Top-100 natural languages and top-10 programming languages in training data. This explains the inclusivity of data.
- Figure 3: Language distribution comparison with KaLM-Embedding. This highlights a key motivation/improvement.
- Figure 4: Task type distribution. This is also important for the data explanation.
- Table 1: Model and training configurations. This explains the architecture and training.
I'll pick Figure 1 (overall results), Figure 2 (data inclusivity), and Table 1 (model config). Actually, the prompt says "Figure/Table", and it should be an image. Table 1 is an HTML table, not an image. So I cannot pick Table 1. I need to pick tags.
Let's recheck the figures.
- Figure 1:
2603.19223v1/x1.png- Key results. Good. - Figure 2:
2603.19223v1/x2.png- Training data language distribution. Good. - Figure 3:
2603.19223v1/x3.png- Comparison of language distribution. Good.
I'll choose Figure 1, Figure 2, and Figure 3. They are all images and highlight key aspects of the paper (results, data, comparison).
Figure 1: https://arxiv.org/html/2603.19223v1/x1.png, "MTEB 벤치마크 성능"
Figure 2: https://arxiv.org/html/2603.19223v1/x2.png, "훈련 데이터 언어 분포"
Figure 3: https://arxiv.org/html/2603.19223v1/x3.png, "데이터셋 언어 분포 비교"
Looks good. 저자: Ziyin Zhang, Zihan Liao, Hang Yu, Peng Di, Rui Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multilingual Embedding Models : 200개 이상의 다양한 언어에 대한 텍스트를 고차원 벡터 공간으로 매핑하여 의미적 관계를 포착하는 모델.
- Matryoshka Representation Learning (MRL) : 단일 임베딩 벡터가 여러 Granularity의 정보를 포함하도록 학습되어, 다양한 차원의 임베딩을 효율적으로 사용할 수 있게 하는 기법.
- Knowledge Distillation : 더 크고 복잡한 "Teacher" 모델의 지식을 더 작고 효율적인 "Student" 모델로 전이하는 훈련 기법.
- Model Pruning : 모델의 불필요한 파라미터를 제거하여 모델 크기를 줄이고 Inference 효율성을 높이는 기법.
- MTEB Benchmark : Text embedding 모델의 성능을 평가하기 위한 광범위한 다국어 벤치마크 (Massive Text Embedding Benchmark).
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Encoder-based 아키텍처에서 Decoder-based LLM embeddings로의 전환은 성능 향상을 가져왔지만, 현재 연구는 두 가지 주요 한계를 가지고 있습니다. 첫째, English-centric bias 가 만연하여, MTEB와 같은 벤치마크에서도 영어 및 중국어와 같은 High-resource languages에 disproportionately 많은 관심이 집중되어 글로벌 유틸리티를 제공하지 못하는 모델이 많습니다. 둘째, Transparency gap 이 존재하여, Gemini-Embedding이나 Qwen3-Embedding과 같은 Top-performing 모델들이 Closed-source API로 제공되거나, Open-weight 모델이더라도 Underlying training data나 Methodology를 공개하지 않아 Reproducibility를 저해하고 Inclusive한 임베딩 시스템 구축에 대한 이해를 제한합니다. 저자들은 이러한 문제들을 해결하기 위해 F2LLM-v2를 제안하며, 특히 Underserved mid- and low-resource languages 에 대한 지원과 Computational inclusivity를 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
F2LLM-v2는 60 million 개의 High-quality training samples로 구성된 광범위한 데이터를 활용하며, 이는 282개 의 자연어와 40개 이상의 프로그래밍 언어를 포함합니다. 데이터 큐레이션은 특정 벤치마크 최적화보다는 Real-world data availability 에 초점을 맞추어, 스페인어, 아랍어, 이탈리아어 등 MTEB에 전용 벤치마크가 없는 언어에도 상당한 양의 데이터를 포함합니다 [Figure 2, 3]. 모든 데이터는 Retrieval, Clustering, Two-way Classification의 세 가지 Canonical formats으로 통합되어 Contrastive learning framework 내에서 모델이 Versatile embedding space를 학습하도록 합니다.
제안 방법론은 Two-stage training strategy를 채택하며, 첫 번째 Stage는 Robust semantic foundation 구축에 중점을 두며 7개 의 Retrieval datasets를 사용합니다. 두 번째 Stage는 Classification, Reranking, Paraphrase detection과 같은 Downstream applications의 Nuances를 처리하는 능력을 향상시키기 위해 Task-specific instructions를 적용합니다. 또한, Qwen3 기반의 표준 Dense Transformer decoder 아키텍처를 사용하여 80M부터 14B까지 8가지 Distinct model sizes 를 제공합니다. 특히, 0.6B 모델을 Pruning 하여 80M, 160M, 330M의 더 작은 모델을 생성하고, Naive training 시 발생하는 성능 저하를 완화하기 위해 Knowledge Distillation loss 를 적용합니다. 이 Knowledge Distillation 은 Student 모델의 Sequence embedding과 Teacher 모델의 Sequence embedding 간의 MSE 를 계산하여 이루어지며, Matryoshka Representation Learning (MRL) 도 두 Training stages에 모두 적용되어 최소 Matryoshka dimension은 8 입니다.
평가 결과, F2LLM-v2-14B는 11개의 MTEB benchmarks 에서 First rank를 달성하며 State-of-the-Art 성능을 기록했습니다
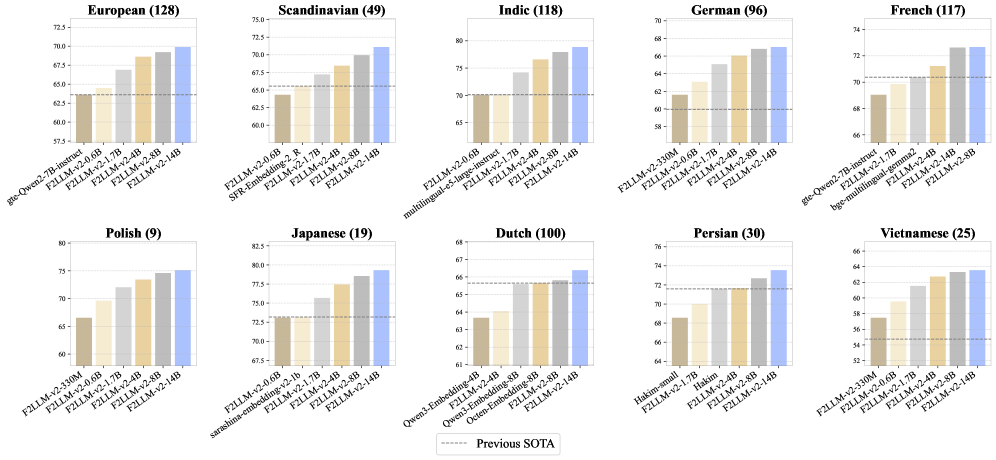
또한, Smaller models도 Resource-constrained applications에서 이전 Frontier models 대비 뛰어난 성능을 보였습니다.
4. Conclusion & Impact (결론 및 시사점)
F2LLM-v2는 Multilingual embedding 모델 연구의 중요한 진전을 나타내며, 특히 기존의 English-centric bias와 Transparency gap 문제를 해결하고자 합니다. 이 연구는 Comprehensive training data 큐레이션, Two-stage training pipeline, 그리고 Matryoshka learning, Model pruning, Knowledge distillation을 통합함으로써 Inclusive, Performant, and Efficient embedding models 를 성공적으로 제시합니다. F2LLM-v2-14B 모델이 11개 MTEB 벤치마크에서 1위를 차지 하고, 더 작은 모델들도 Resource-constrained 환경에서 뛰어난 성능을 보이는 것은 이 방법론의 Effective함을 입증합니다. 이 연구는 모든 모델, 데이터, 코드, 중간 체크포인트를 오픈 소스로 공개함으로써 재현성을 높이고 Multilingual embedding model 연구 분야의 발전을 촉진하여, 궁극적으로 보다 Inclusive한 AI 기술 미래를 위한 기반을 마련합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
- [논문리뷰] Pruning and Distilling Mixture-of-Experts into Dense Language Models
- [논문리뷰] ETCHR: Editing To Clarify and Harness Reasoning
- [논문리뷰] MatryoshkaLoRA: Learning Accurate Hierarchical Low-Rank Representations for LLM Fine-Tuning
- [논문리뷰] Cross-Tokenizer LLM Distillation through a Byte-Level Interface
Review 의 다른글
- 이전글 [논문리뷰] EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing
- 현재글 : [논문리뷰] F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
- 다음글 [논문리뷰] FASTER: Rethinking Real-Time Flow VLAs
댓글