[논문리뷰] FASTER: Rethinking Real-Time Flow VLAs
링크: 논문 PDF로 바로 열기
The paper "FASTER: Rethinking Real-Time Flow VLAs" by Yuxiang Lu, Zhe Liu, Xianzhe Fan, et al., addresses the critical issue of reaction latency in Vision-Language-Action (VLA) models for real-time robotic deployment.
Part 1: 요약 본문
저자: Yuxiang Lu, Zhe Liu, Xianzhe Fan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision-Language-Action (VLA) Models : Vision-Language Models (VLMs)의 개념을 로봇 행동 학습으로 확장하여, 다양한 멀티모달 관측 및 언어 지시를 저수준(low-level) 모터 명령으로 직접 매핑하는 모델입니다.
- Action Chunking : VLA 정책에서 미래 행동 시퀀스(action chunk)를 예측하고, 이 중 일부(execution horizon)만 실행한 후 새로운 추론을 트리거하는 표준 방법입니다.
- Flow Matching : Gaussian noise 샘플을 Conditional Flow Matching을 사용하여 목표 행동 청크(action chunk)로 변환하는 속도장(velocity field)을 학습하는 VLA 모델의 핵심 메커니즘입니다.
- Time to First Action (TTFA) : 로봇이 예측된 행동 청크에서 첫 번째 행동을 시작할 수 있는 가장 빠른 순간을 측정하는 새로운 지표로, 반응 속도의 진정한 병목(bottleneck)을 나타냅니다.
- Horizon-Aware Schedule (HAS) : FASTER에서 제안하는 스케줄링 메커니즘으로, 행동 청크 내에서 근시점(near-term) 행동의 샘플링을 우선순위화하여 즉각적인 반응을 위한 디노이징(denoising) 단계를 압축합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Vision-Language-Action (VLA) 모델의 실제 로봇 배포에서 실시간 실행(real-time execution)은 매우 중요합니다. 기존 비동기(asynchronous) 추론 방법들은 주로 궤적(trajectory)의 부드러움(smoothness)을 최적화하지만, 환경 변화에 반응하는 데 필수적인 반응 지연 시간(reaction latency)을 간과하는 한계가 있습니다. 저자들은 행동 청킹(action chunking) 정책에서 반응 시간(reaction time)이 추론 지연 시간(inference latency)에 의해 결정되는 단순한 상수가 아니라, Time to First Action (TTFA)과 실행 Horizon에 의해 결정되는 균일 분포(uniform distribution)를 따른다는 점을 밝힙니다. 특히, Flow-based VLA에서 모든 샘플링 단계(sampling steps)가 완료되어야만 행동이 시작될 수 있도록 하는 기존의 일정한 시간표(constant schedule) 방식이 반응 지연의 병목을 형성한다고 지적합니다.
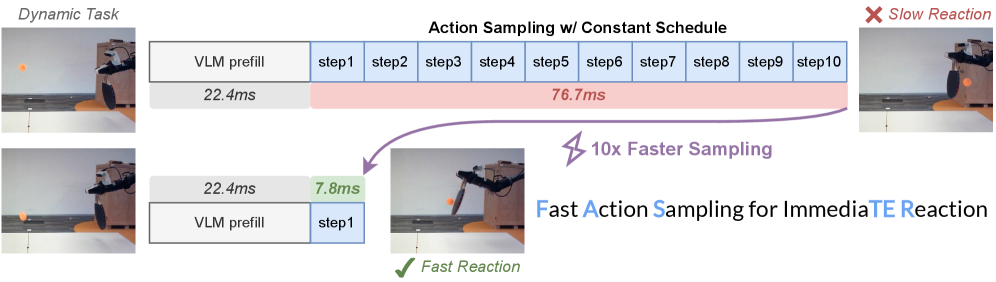
은 기존 방식과 FASTER의 차이를 시각적으로 보여줍니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 FASTER (Fast Action Sampling for ImmediaTE Reaction) 를 제안합니다. FASTER는 Horizon-Aware Schedule (HAS) 을 도입하여 Flow Sampling 과정에서 근시점(near-term) 행동에 우선순위를 부여합니다. 이는 즉각적인 반응을 위한 디노이징을 단일 단계로 압축하면서도 장기(long-horizon) 궤적의 품질을 유지합니다.
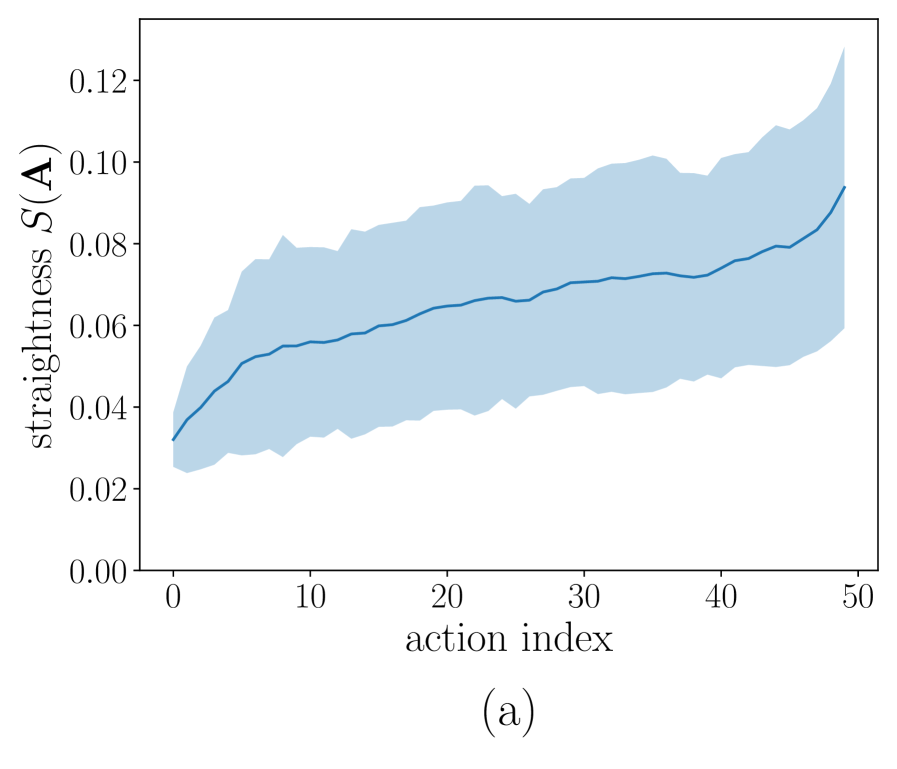
에서 알 수 있듯이, 초기 행동(early actions)은 적은 샘플링 단계(sampling steps)만으로도 정확한 예측이 가능함을 파일럿 연구를 통해 검증했습니다. 기존의 Constant Timestep Schedule은 모든 행동에 동일한 수의 디노이징 단계를 할당하여, 특히 즉각적인 반응이 필요한 첫 번째 행동의 지연을 야기합니다. 반면,
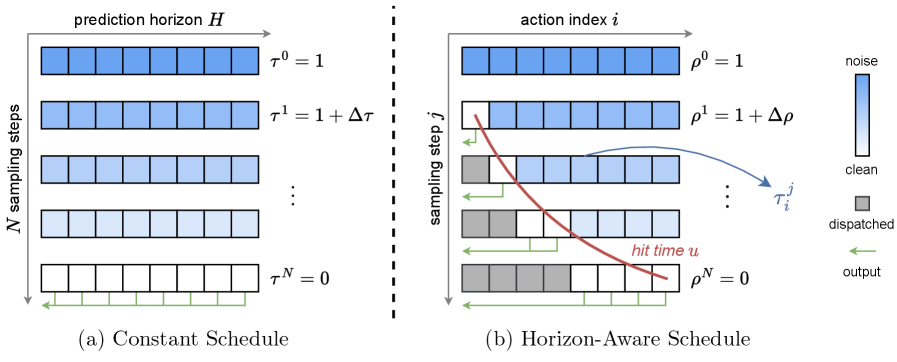
에 나타난 HAS는 각 Action Index에 대해 적응적으로 Hit Time을 할당하여, 즉각적인 행동은 빠르게 완료되고 이후의 행동은 점진적으로 개선될 수 있도록 합니다.
FASTER는 또한 스트리밍 클라이언트-서버(streaming client-server) 파이프라인과 결합되어, 초기 행동이 완료되는 즉시 로봇 컨트롤러(robot controller)로 전송될 수 있도록 합니다. 로봇이 초기 움직임을 실행하는 동안, VLA 모델은 나머지 행동들을 병렬로 계속해서 개선하여 클라이언트의 Action Buffer를 점진적으로 보충합니다. 실험 결과, RTX 4060 GPU에서 π0.5 모델의 경우 Async 대비 TTFA를 1.27배 , X-VLA 모델의 경우 TTFA를 3.09배 단축시키는 성능 향상을 보였습니다. 또한, 예상 반응 시간(expected reaction time) 측면에서도 π0.5에서 1.26배 , X-VLA에서 2.62배 향상된 결과를 기록했습니다 [cite: 1, Table 2]. 특히 X-VLA의 경우, [Table 3]에서 FASTER가 baseline보다 짧은 반응 시간을 가질 확률이 RTX 4090 및 RTX 4060 모두에서 100% 로 나타나, 확실한 성능 우위를 입증했습니다. 실세계 탁구 태스크 실험([Figure 5])에서는 FASTER가 모든 Baseline 대비 현저히 빠른 반응 속도를 보였으며, 이는 로봇이 공과 접촉하는 순간의 라켓 각도(racket angle)를 통해 직관적으로 확인할 수 있습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 행동 청킹 VLA 정책에서 실시간 반응 능력(reaction capability)을 재고하고, Flow-based VLA의 Constant Timestep Schedule이 실시간 반응성의 주요 병목(bottleneck)임을 규명했습니다. 저자들은 Horizon-Aware Schedule을 활용하여 행동 샘플링을 적응적으로 가속화하는 FASTER를 제안하여, 전체 궤적 품질을 저해하지 않으면서 즉각적인 행동을 단일 단계(single-step)로 생성할 수 있도록 합니다. 스트리밍 클라이언트-서버 인터페이스와 조기 종료(early stopping) 전략을 통해 FASTER는 TTFA를 줄이고 폐쇄 루프 제어(closed-loop control) 속도를 높이는 효과를 동시에 달성했습니다. 실세계 로봇 실험은 FASTER가 특히 Edge Device 환경에서 실시간 로봇 지능을 위한 강력하고 범용적인 Plug-and-Play 솔루션임을 입증했습니다. 이 연구는 로봇 조작(robotic manipulation) 분야에서 반응성과 정확도(accuracy) 간의 더 나은 균형점을 제시하며, 실시간 로봇 시스템 개발에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SimVLA: A Simple VLA Baseline for Robotic Manipulation
- [논문리뷰] Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
- [논문리뷰] X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
- [논문리뷰] RynnWorld-4D: 4D Embodied World Models for Robotic Manipulation
- [논문리뷰] Perceptual Flow Matching for Few-Step Generative Modeling
Review 의 다른글
- 이전글 [논문리뷰] F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
- 현재글 : [논문리뷰] FASTER: Rethinking Real-Time Flow VLAs
- 다음글 [논문리뷰] Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
댓글