[논문리뷰] Lance: Unified Multimodal Modeling by Multi-Task Synergy
링크: 논문 PDF로 바로 열기
메타데이터
저자: Fengyi Fu, Mengqi Huang, Shaojin Wu, Yunsheng Jiang, Yufei Huo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Unified Multimodal Modeling: 이미지와 비디오의 이해(Understanding), 생성(Generation), 편집(Editing)을 단일 프레임워크 내에서 통합하여 수행하는 패러다임입니다.
- Dual-Stream Mixture-of-Experts (MoE): 이해와 생성이라는 상이한 요구사항을 가진 작업들에 전문화된 Expert 경로를 분리하여 할당함으로써, 단일 백본 내에서 병목 현상 없이 효율적인 처리를 가능하게 하는 아키텍처입니다.
- Modality-Aware Rotary Positional Encoding (MaPE): 공유된 인터리브 멀티모달 시퀀스 내에서 heterogeneous한 토큰들(ViT semantic, VAE latents)의 역할을 구분하고 위치적 모호성을 완화하는 인코딩 기법입니다.
- Cross-Task Synergy: 서로 다른 작업 간의 데이터를 공동 학습함으로써 각 작업의 성능을 상호 보완하고, 미학습 작업에 대한 일반화(Emergent Generalization)를 유도하는 학습 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 멀티모달 모델들이 이해와 생성이라는 두 가지 이질적인 목적을 통합할 때 발생하는 성능 저하와 작업 범위의 한계를 해결하기 위해 제안되었습니다. 현재의 unified 모델들은 의미론적 추론(Understanding)을 위한 높은 수준의 특징과 시공간적 역동성(Generation)을 보존해야 하는 낮은 수준의 특징 사이의 표현 불일치 문제를 겪고 있습니다. 또한, 기존 연구들은 텍스트-이미지 영역에 국한되거나 비디오 생성 등 일부 작업에만 최적화되어 있어, 포괄적인 멀티모달 능력을 갖추지 못했다는 한계가 있습니다 [Table 1]. 따라서 저자들은 이해와 생성의 특성을 고려한 구조적 설계와 함께, 다양한 작업을 통합하여 시너지를 창출할 수 있는 새로운 통합 멀티모달 모델인 Lance를 개발하고자 했습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Lance를 통해 통일된 멀티모달 이해, 생성, 편집을 구현하기 위해 unified context 학습과 전문화된 capability 경로 분리를 동시에 달성하는 아키텍처를 제안합니다 [Figure 6]. Lance는 Qwen2.5-VL 기반의 이해 전문가와 Wan2.2 기반의 생성 전문가를 활용하며, MaPE를 통해 Heterogeneous visual 토큰들 간의 정렬을 개선합니다 [Figure 7]. 학습 단계는 PT, CT, SFT, RL의 4단계로 구성되어 있으며, 특히 CT 단계에서 복잡한 멀티모달 작업을 점진적으로 도입하여 성능을 극대화합니다. 정량적 실험 결과, Lance는 단 33B의 activated parameters를 사용함에도 불구하고 VBench 비디오 생성 벤치마크에서 85.11점(Total Score)을 기록하여 기존 unified 모델들을 능가하는 성능을 보였습니다 [Table 6]. 또한 GenEval 이미지 생성 벤치마크에서도 0.90(Overall)의 최고 점수를 기록하며 우수한 compositional ability를 입증하였습니다 [Table 5].
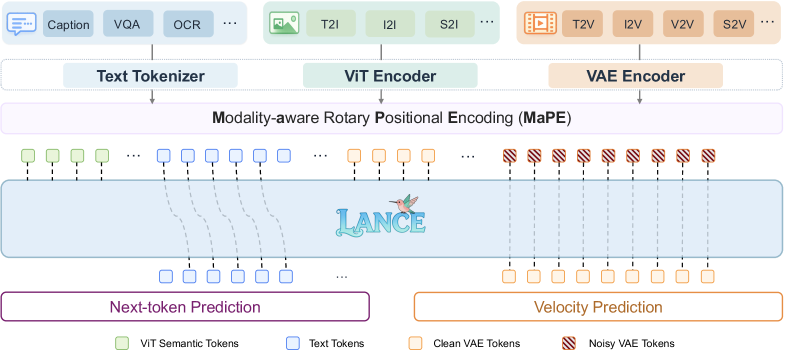
Figure 6 — Lance 전체 아키텍처
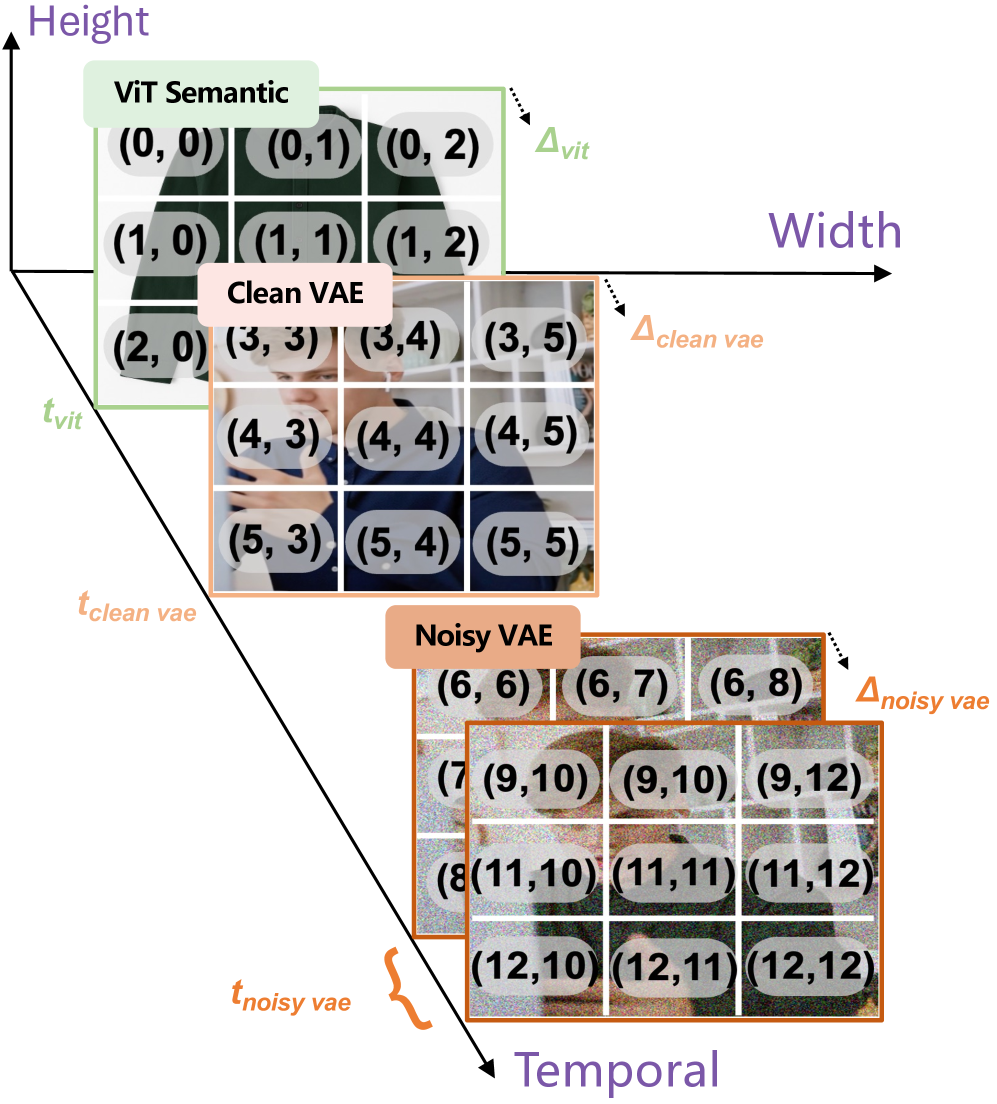
Figure 7 — MaPE 개념도
4. Conclusion & Impact (결론 및 시사점)
Lance는 멀티모달 이해, 생성, 편집을 하나의 경량화된 네이티브 모델로 통합함으로써, 멀티모달 foundation 모델의 실용적인 새로운 패러다임을 제시하였습니다. 이 연구는 단순히 다양한 기능을 합치는 것을 넘어, 멀티 태스크 학습을 통해 작업 간의 synergy를 유도하는 것이 unified 모델의 성능 향상에 필수적임을 입증했습니다. 특히, 자원 효율적인 학습 बजट 내에서 최첨단 성능을 달성한 점은 향후 일반적인 멀티모달 에이전트 및 고성능 시각적 지능 연구에 중요한 학술적 근거와 기술적 토대를 제공할 것으로 기대됩니다.

Figure 10 — T2I 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unified Multimodal Autoregressive Modeling with Shared Context-Visual Tokenizer is Key to Unification
- [논문리뷰] RynnWorld-4D: 4D Embodied World Models for Robotic Manipulation
- [논문리뷰] Perceptual Flow Matching for Few-Step Generative Modeling
- [논문리뷰] InternVLA-A1.5: Unifying Understanding, Latent Foresight, and Action for Compositional Generalization
- [논문리뷰] WorldDirector: Building Controllable World Simulators with Persistent Dynamic Memory
Review 의 다른글
- 이전글 [논문리뷰] KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
- 현재글 : [논문리뷰] Lance: Unified Multimodal Modeling by Multi-Task Synergy
- 다음글 [논문리뷰] LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs
댓글