[논문리뷰] DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Quanhao Li, Junqiu Yu, Kaixun Jiang, Yujie Wei, Zhen Xing, Pandeng Li, Ruihang Chu, Shiwei Zhang, Yu Liu, Zuxuan Wu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- DiffusionOPD: 단일 작업(Single-task)으로 훈련된 전문가 모델(Teacher)들의 능력을 하나의 통합된 학생 모델(Student)로 전이하는 On-Policy Distillation 기반의 새로운 멀티태스크 훈련 프레임워크입니다.
- On-Policy Distillation (OPD): 학생 모델이 자신의 정책을 통해 생성한 롤아웃(Rollout) 궤적을 따라 전문가 모델의 행동을 모방하도록 학습하는 방식으로, 훈련 과정에서 고차원적인 Dense supervision을 제공합니다.
- Closed-form KL Objective: 확산 모델(Diffusion Model)의 덴노이징(Denoising) 과정에서 학생과 전문가의 전이 커널(Transition Kernel) 간의 차이를 해석적인 수식으로 산출하여, PPO와 같은 확률적 정책 경사법 없이도 효율적인 최적화를 가능하게 하는 핵심 기법입니다.
- Flow Matching: 확산 모델의 생성 과정을 확률 흐름(Probability Flow)의 관점에서 모델링하여 훈련하는 프레임워크로, 본 논문에서는 이를 통해 결정론적(Deterministic) ODE 및 확률적(Stochastic) SDE 샘플러를 모두 지원합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 멀티태스크 강화학습(RL) 방식이 겪는 최적화 간섭(Optimization Interference)과 성능 불균형 문제를 해결하기 위해 고안되었습니다. 기존의 멀티태스크 RL은 여러 보상 신호를 동시에 최적화하려다 보니 작업 간의 상충(Conflict)으로 인해 학습 효율이 저하되거나 특정 쉬운 작업이 전체 학습을 지배하는 문제가 발생합니다. 또한, 순차적인 학습(Cascade RL) 방식은 구현이 복잡하고 이전 작업에 대한 망각(Catastrophic Forgetting) 현상이 빈번합니다. 이에 저자들은 단일 작업 탐색과 멀티태스크 통합 과정을 분리하여, 이러한 문제들을 근본적으로 극복하는 새로운 프레임워크를 제안합니다 [Figure 1].

Figure 1 — DiffusionOPD 학습 곡선 및 벤치마크 성능
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 확산 모델의 덴노이징 과정을 마르코프 연쇄(Markov Chain)로 재정의하고, 학생 모델과 전문가 모델의 전이 평균(Transition Mean)을 일치시키는 Closed-form KL Objective를 제안합니다 [Figure 1]. 이 방법은 전문가의 행동을 Dense하게 모방함으로써 PPO-style 정책 경사법에서 발생하는 높은 분산(Gradient Variance) 문제를 회피하고, 확산 모델의 ODE/SDE 샘플러 전반에 걸쳐 강력한 최적화 성능을 보입니다 [Figure 3]. 실험 결과, DiffusionOPD는 기존의 멀티태스크 RL 및 캐스케이드(Cascade) RL 베이스라인 대비 훈련 효율성(Wall-clock time)과 최종 성능(Performance Ceiling) 모두에서 압도적인 우위를 점하였습니다 [Table 1]. 특히, Aesthetic, OCR, GenEval 등 다양한 벤치마크에서 State-of-the-Art 결과를 달성하며, 개별 전문가 모델들의 능력을 성공적으로 단일 학생 모델에 결합함을 입증하였습니다 [Figure 2].

Figure 2 — 멀티태스크 RL 방식과의 정성적 비교
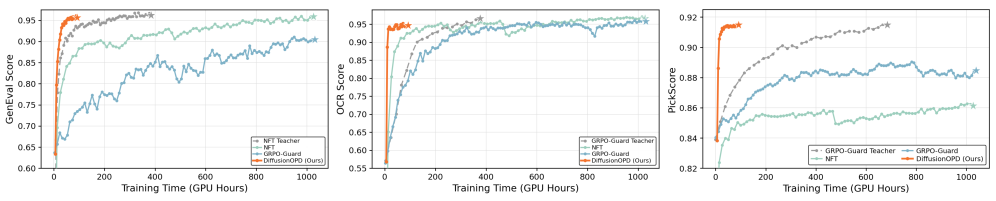
Figure 3 — 학습 효율성 및 성능 비교 그래프
4. Conclusion & Impact (결론 및 시사점)
본 연구는 확산 모델을 위한 On-Policy Distillation 프레임워크로서 DiffusionOPD의 이론적 기틀을 마련하고, 복잡한 멀티태스크 환경에서의 최적화 전략을 재정립하였습니다. 저자들은 해석적인 KL 목적 함수를 도출함으로써 강화학습의 불안정성을 해소하고 멀티태스크 정렬의 효율성을 극대화하였습니다. 이러한 성과는 향후 대규모 멀티태스크 생성 모델의 정렬(Alignment) 연구와 실용적인 최적화 파이프라인 구축에 중요한 학술적 시사점을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Multi-Resolution Flow Matching: Training-Free Diffusion Acceleration via Staged Sampling
- [논문리뷰] Qwen-Image-2.0-RL Technical Report
- [논문리뷰] DanceOPD: On-Policy Generative Field Distillation
- [논문리뷰] CollectionLoRA: Collecting 50 Effects in 1 LoRA via Multi-Teacher On-Policy Distillation
- [논문리뷰] FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
Review 의 다른글
- 이전글 [논문리뷰] Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning
- 현재글 : [논문리뷰] DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
- 다음글 [논문리뷰] Does Synthetic Layered Design Data Benefit Layered Design Decomposition?
댓글