[논문리뷰] Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tao Liu, Hao Yan, Mengting Chen, Taihang Hu, Zhengrong Yue, Zihao Pan, Jinsong Lan, Xiaoyong Zhu, Ming-Ming Cheng, Bo Zheng, Yaxing Wang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- DMD (Distribution Matching Distillation): 사전 학습된 teacher 모델의 분포를 student 모델이 모방하도록 학습시키는 diffusion distillation 기법으로, 기존에는 고정된 이산적 타임스텝에 의존함.
- Continuous-Time Distribution Matching (CDM): 제안하는 프레임워크로, 학습을 고정된 이산적 타임스텝이 아닌 연속적 시간 도메인에서 수행하여 Few-Step inference에서의 수치적 오차(truncation error)를 줄임.
- CA Loss (CFG Augmentation): 생성된 결과의 텍스트-이미지 정렬(text-image alignment) 성능을 강화하기 위해 사용하는 손실 함수.
- DM Loss (Distribution Matching): student가 생성하는 marginal distribution을 teacher의 데이터 분포와 정렬시키기 위해 사용되는 손실 함수.
- Velocity-driven Extrapolation: CDM에서 오프라인 궤적(off-trajectory) latents를 생성하기 위해 student의 예측 velocity field를 활용하는 기법.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 Diffusion Distillation 방식이 학습 및 추론 시 고정된 이산적 타임스텝(discrete anchors)에 지나치게 의존함으로써 발생하는 성능 저하 문제를 해결하고자 한다. 기존의 DMD 기반 방법론들은 고정된 타임스텝 간의 불연속성으로 인해 세부 정보가 손실되거나 오버스무딩(over-smoothing) 현상이 나타나는 한계를 가진다. 이러한 구조적 제한은 추론 단계에서 누적되는 수치적 절단 오차(numerical truncation error)를 증폭시켜 최종 출력의 품질을 저하시킨다 [Figure 2]. 따라서, 이산적 타임스텝의 제약에서 벗어나 연속적인 시간 공간 내에서 모델을 최적화할 수 있는 새로운 접근 방식이 요구된다.
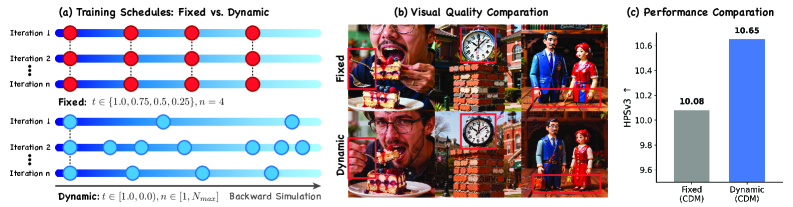
Figure 2 — 스케줄 분리 및 성능 비교
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 Dynamic Time Schedule과 오프라인 궤적 학습을 결합한 Continuous-Time Distribution Matching (CDM) 프레임워크를 제안한다 [Figure 4]. 저자들은 기존의 고정된 이산적 anchor 대신 학습 시마다 랜덤한 길이를 가지는 연속적인 타임스텝을 동적으로 샘플링하여 student 모델이 더 다양한 궤적에서 teacher의 분포를 학습하도록 설계했다. 또한, 학습 중 오프라인 궤적(off-trajectory)으로 이탈하는 현상을 보정하기 위해 student의 예측 velocity field를 활용한 1차 Euler extrapolation을 수행하고, 해당 지점에서 distribution matching을 강제하는 CDM Loss를 도입했다 [Figure 4]. 실험 결과, SD3-Medium 및 Longcat-Image backbone에서 4 NFE(Number of Function Evaluations) 환경으로 검증했을 때, 제안 모델은 기존의 강력한 baseline인 D-DMD 대비 HPSv3 점수를 크게 향상시키는 등 정량적 우위를 보였다 [Table 1]. 특히, 별도의 GAN이나 Reward Model 같은 복잡한 보조 모듈 없이도 고품질의 텍스트-이미지 정렬과 세부 텍스처를 재현해내는 정성적 성과를 거두었다 [Figure 5].
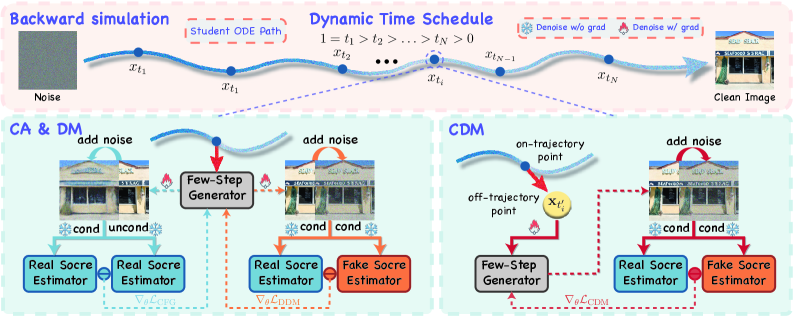
Figure 4 — CDM 전체 프레임워크

Figure 5 — 정성적 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 diffusion 모델의 distillation 과정을 이산적 시간 구조에서 연속적 최적화 공간으로 전환함으로써 Few-Step 이미지 생성의 품질을 획기적으로 개선했다. 동적 타임스텝 스케줄링과 velocity-driven 오프라인 정렬 기법은 추가적인 추론 비용 없이도 추론 궤적의 안정성을 크게 향상시켰다. 이 방법론은 복잡한 auxiliary objective를 배제하고도 최신 state-of-the-art 성능을 달성하여, 실무적인 diffusion 모델 배포 효율성을 높이는 데 중요한 시사점을 제공한다. 본 연구 결과는 향후 대규모 생성 모델의 경량화 및 효율적인 추론을 위한 핵심 프레임워크로 활용될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Streaming Autoregressive Video Generation via Diagonal Distillation
- [논문리뷰] Mode Seeking meets Mean Seeking for Fast Long Video Generation
- [논문리뷰] Terminal Velocity Matching
- [논문리뷰] pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
- [논문리뷰] Perceptual Flow Matching for Few-Step Generative Modeling
Review 의 다른글
- 이전글 [논문리뷰] Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes
- 현재글 : [논문리뷰] Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
- 다음글 [논문리뷰] MARBLE: Multi-Aspect Reward Balance for Diffusion RL
댓글