[논문리뷰] Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jingjie Ning, Xiaochuan Li, Ji Zeng, Hao Kang, Chenyan Xiong
1. Key Terms & Definitions (핵심 용어 및 정의)
- Closed-Loop Auto Research: 에이전트가 가설 제안, 코드 수정, 실험 수행, 결과 분석을 거쳐 그 피드백을 다음 가설에 반영하는 순환 구조의 연구 방식입니다.
- Submitted-Trial: 연구의 단위로서, 가설, 실행 가능한 코드 편집(diff), 외부 평가자에 의한 결과값, 그리고 다음 단계로 연결되는 피드백을 포함하는 데이터 객체입니다.
- Specialist Agents: 특정 연구 영역(예: 아키텍처, 옵티마이저)에 특화된 프롬프트를 사용하여, recipe 표면을 분할하고 탐색 효율을 높이는 에이전트입니다.
- Lineage Feedback: 실험 기록(성공/실패, 코드 편집, 성능 수치)을 공유하여 에이전트들이 이전의 시도에서 얻은 측정된 증거를 바탕으로 더 나은 후속 제안을 하도록 돕는 시스템입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기계학습 연구의 제안-측정-수정 루프를 인간의 개입 없이 언어 모델 에이전트로 자동화하는 것을 목표로 합니다. 기존의 자동화 연구들이 주로 단일 모델 출력물 생성이나 제한적인 하이퍼파라미터 탐색에 머물렀던 것과 달리, 이 연구는 실제 학습 파이프라인 전반에 걸친 실질적인 코드 구조 수정을 목표로 합니다. 특히, 기존 연구들은 실패한 실험을 단순히 버리는 경우가 많으나, 저자들은 이를 구체적인 제약 사항(size cap, wallclock, accuracy gate 등)에 대한 '측정된 증거'로 변환하여 활용하는 것이 필요하다고 주장합니다. 이와 같은 연구 과정은 결과값뿐만 아니라 시도된 경로 전체가 감사 가능한 아티팩트가 되어야 합니다 [Figure 1].
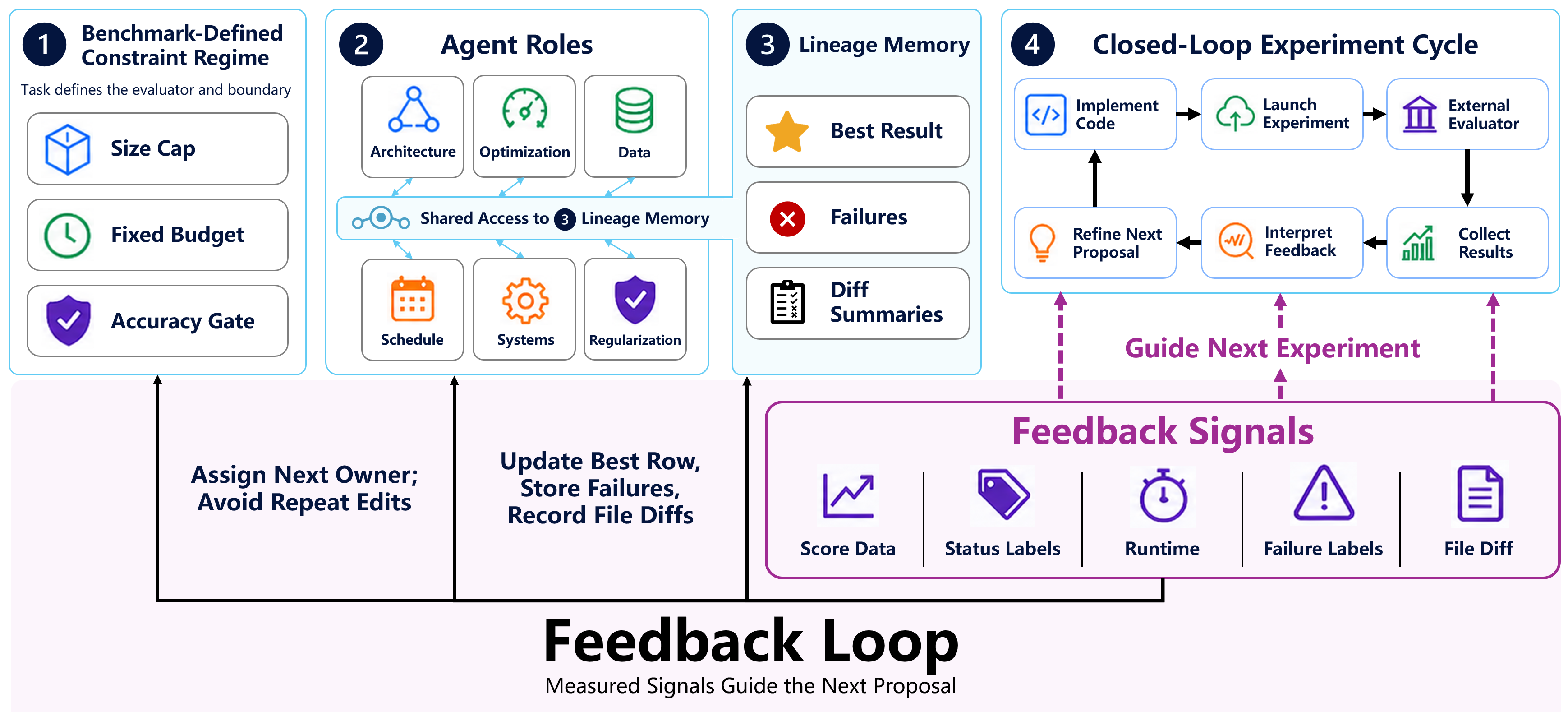
Figure 1 — 자동 연구의 폐쇄 루프 궤적
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 고정된 환경에서 에이전트가 실험을 수행하고 외부 평가자의 피드백을 공유받는 닫힌 루프(Closed-Loop) 방법론을 제안합니다. 이 루프는 Specialist Agents를 사용하여 탐색 공간을 partitioning하고, 이들이 생성한 Lineage 데이터를 공유함으로써 이전 실험의 성공과 실패를 후속 프로그램 편집에 반영합니다 [Figure 1].
실험 결과, 제안된 시스템은 1,197번의 헤드라인 시도 동안 인간의 개입 없이 세 가지 고정 컴퓨팅 예산 작업에서 모두 성능을 향상시켰습니다.
- Parameter Golf: 기존 공공 SOTA 대비
val_bpb를 0.81% 감소시켰습니다. - NanoChat-D12:
CORE점수를 38.7% 향상시켰습니다. - CIFAR-10 Airbench96:
wallclock시간을 4.59% 단축하면서도 0.96의 정확도 게이트를 충족했습니다 [Table 1]. 주목할 점은 에이전트들이 단순한 파라미터 튜닝을 넘어, attention 경로 재작성(SSSL to L)이나 residual scaling과 같은 프로그램 수준의 구조적 변화를 자율적으로 수행했다는 것입니다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 오토 리서치를 단일 결과물이 아닌 감사 가능한 폐쇄 루프 궤적으로 재정의하며, Specialist Agents를 통한 자율적 연구가 가능함을 입증했습니다. 연구진은 실험에서 발생한 실패와 제약 위반(size block, budget overrun 등)을 오히려 연구의 방향성을 설정하는 핵심 피드백으로 전환했습니다. 이 연구는 학계와 산업계의 ML 연구 프로세스를 보다 확장 가능하고, 투명하며, 재사용 가능한 기록으로 바꿀 수 있는 토대를 마련했습니다. 향후 더 강력한 에이전트가 등장하더라도 이 폐쇄 루프 프레임워크는 연구의 효율성과 객관성을 검증하는 표준적인 Arena로 기능할 것으로 기대됩니다.
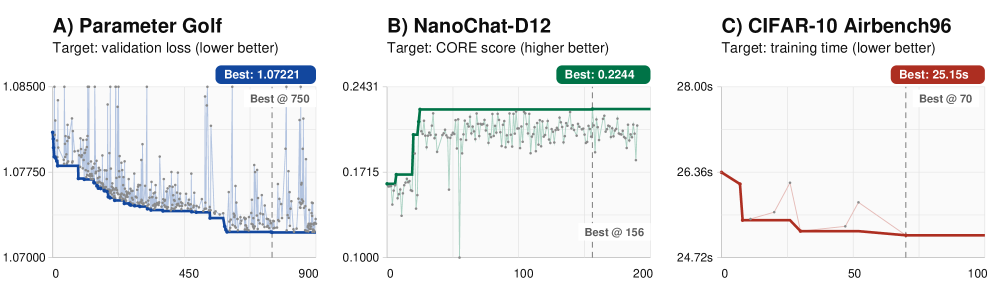
Figure 2 — 시도 인덱스별 최고 점수 추이
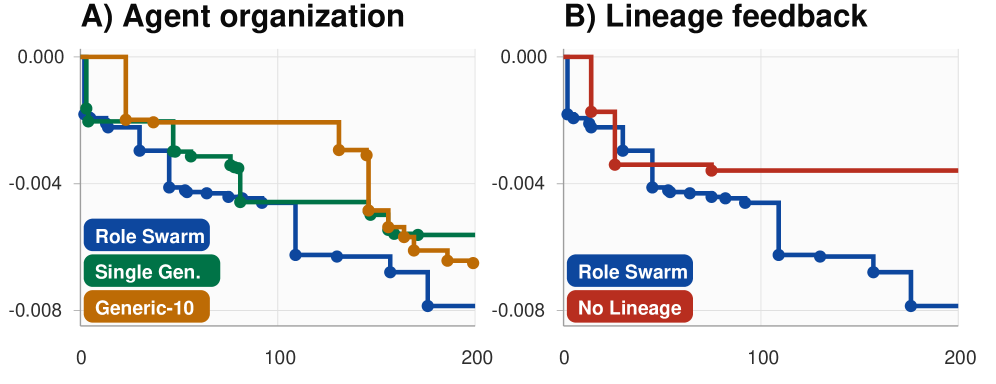
Figure 3 — Parameter Golf 대조군 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
- [논문리뷰] Policy and World Modeling Co-Training for Language Agents
- [논문리뷰] LiteCoder-Terminal: Scaling Long-Horizon Terminal Environments for Learning Language Agents
- [논문리뷰] Learning to Learn-at-Test-Time: Language Agents with Learnable Adaptation Policies
- [논문리뷰] $OneMillion-Bench: How Far are Language Agents from Human Experts?
Review 의 다른글
- 이전글 [논문리뷰] Audio-Visual Intelligence in Large Foundation Models
- 현재글 : [논문리뷰] Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes
- 다음글 [논문리뷰] Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
댓글