[논문리뷰] Audio-Visual Intelligence in Large Foundation Models
링크: 논문 PDF로 바로 열기
저자: You Qin, Kai Liu, Shengqiong Wu, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- AVI (Audio-Visual Intelligence): 시청각 데이터를 이해, 생성 및 상호작용하는 인공지능의 능력을 지칭하며, 대규모 파운데이션 모델을 통해 실시간으로 처리되는 지능적 기능을 포함합니다.
- VLA (Vision-Language-Action Models): 시각, 언어, 오디오 관측을 기반으로 로봇 제어와 같은 물리적 환경에서의 행동(Action)을 출력하는 통합형 임베디드 모델입니다.
- AVEL (Audio-Visual Event Localization): 비디오 내에서 오디오와 비디오가 동시에 발생하는 시간적 구간을 식별하고 위치를 추정하는 작업입니다.
- I2AV (Image-to-Audio-Video Generation): 단일 이미지를 참조하여 사운드와 모션이 결합된 비디오를 생성하는 기술로, 공간적 제약 하에서 오디오-비디오의 긴밀한 동기화를 목표로 합니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 대규모 파운데이션 모델 시대에 멀티모달 학습이 필수적임에도 불구하고, 시청각 데이터 간의 정렬, Taxonomy의 불일치, 그리고 평가 방법론의 파편화로 인해 체계적인 연구가 어렵다는 문제를 해결하고자 합니다. 기존 연구들은 각 작업 단위로 분리되어 있거나, 인접한 하위 분야 간의 방법론 공유가 미흡하여 시스템의 확장성과 범용성이 부족한 한계를 가지고 있습니다. 특히 시각 정보와 청각 정보가 시간적, 공간적으로 밀접하게 얽혀 있는 실제 환경에서의 처리를 위해, 기존 모델들을 포괄하는 통합적 지식 프레임워크와 Taxonomy 정립이 절실히 요구됩니다. [Figure 1]에 나타난 진화론적 경로와 같이, 개별적인 이해(Understanding)와 생성(Generation) 작업을 넘어, 상호작용(Interaction)까지 아우르는 융합된 모델로의 전환이 이 분야의 핵심적 지향점입니다.
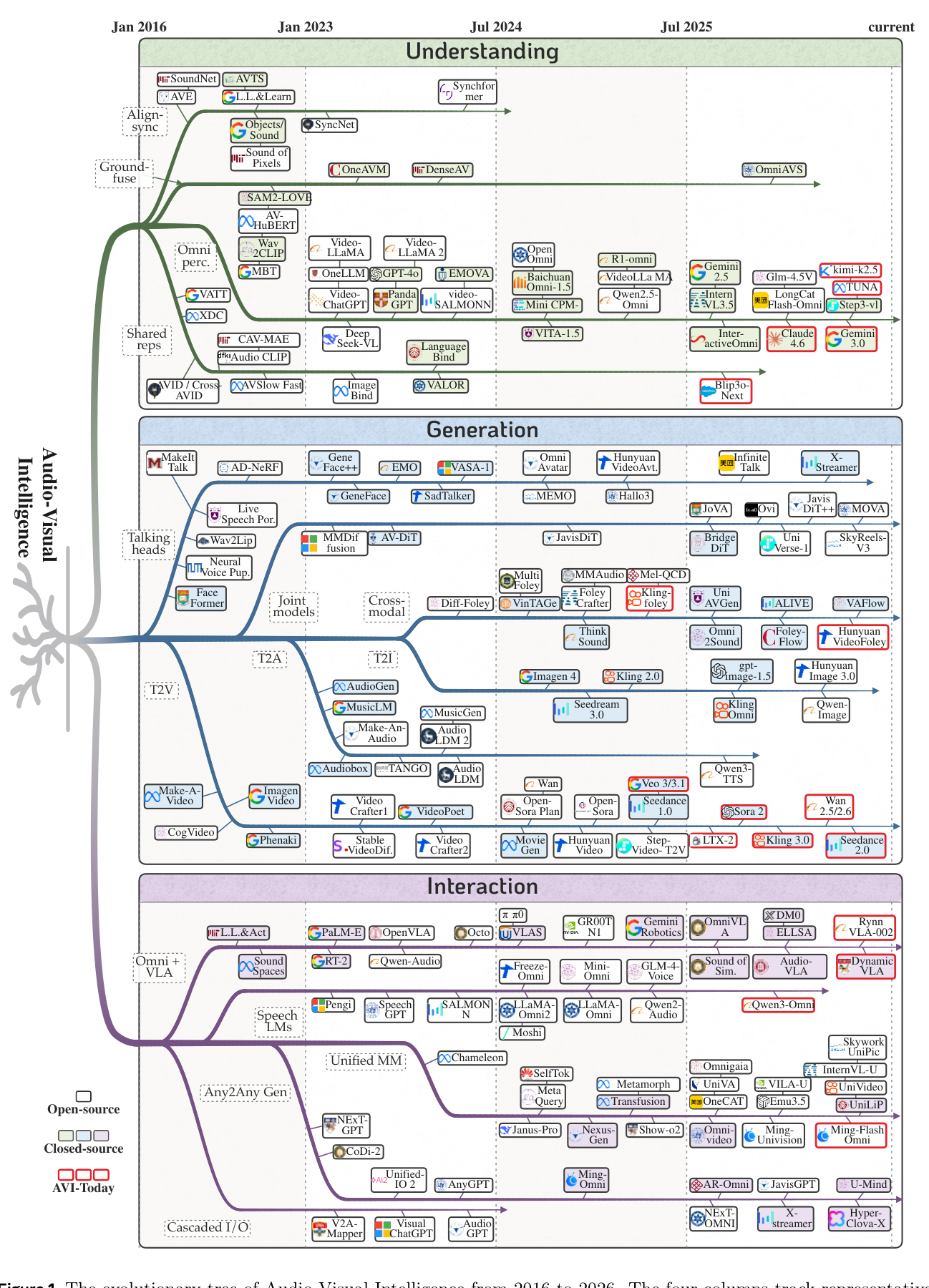
Figure 1 — AVI 분야의 발전 과정을 연도별, 작업별로 구조화한 핵심 트리 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 AVI 분야의 연구를 이해(Perception), 생성(Generation), 상호작용(Interaction)이라는 세 가지 핵심 기둥으로 구조화하여 방법론을 체계화했습니다. 표현 학습(Representation-centric) 방법론은 Self-Supervised Learning, Contrastive Learning, Correlation Modeling 등을 통해 시청각 데이터의 잠재적 동기화 관계를 학습하며, 이를 통해 고품질의 임베딩을 확보합니다. 생성 중심(Generation-centric) 모델은 Diffusion 및 Autoregressive (AR) 트랜스포머를 활용하여 조건부 및 공동 생성(Joint generation) 능력을 극대화합니다. 특히 LLM-Centric 방법론은 모듈형 인코더-디코더 시스템뿐만 아니라 Unified Model 아키텍처를 도입하여 하드웨어 효율성과 지연 시간(Latency)을 개선하는 방향으로 나아가고 있습니다. 벤치마크 결과에 따르면, 최신 Omni-modal 모델들은 기존의 단일 작업 전용 모델들을 능가하며, 특정 작업(예: AVEL의 STG-CMA 기법이 도달한 83.3%의 Acc.)에서 정량적으로 우수한 성능을 입증하였습니다. 이러한 결과는 [Table 2]와 [Table 12]에서 볼 수 있듯이, 고도화된 멀티모달 인코딩과 정교한 정렬 메커니즘이 통합될수록 성능 향상이 두드러짐을 보여줍니다.
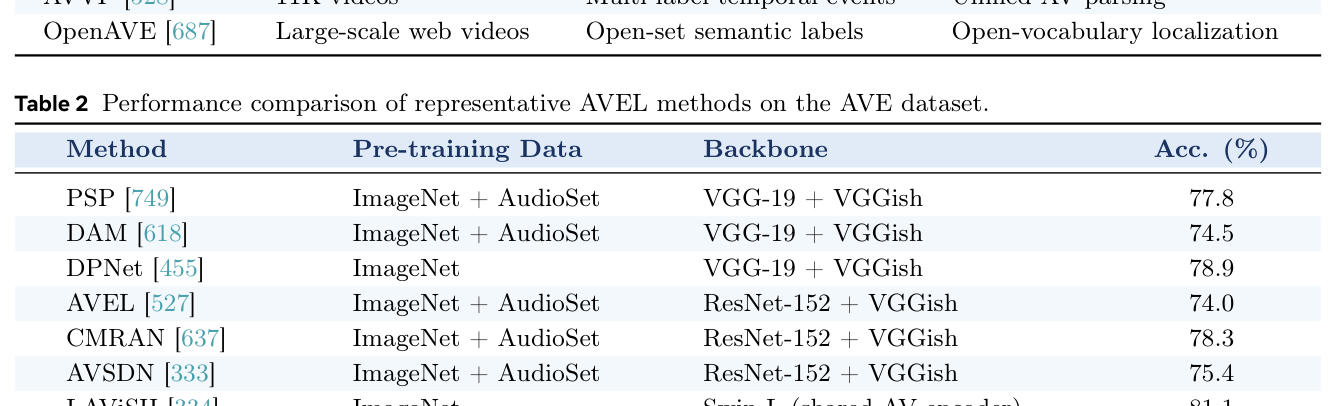
Table 2 — 다양한 AVEL 방법론의 정량적 성능 비교를 담은 핵심 벤치마크 테이블
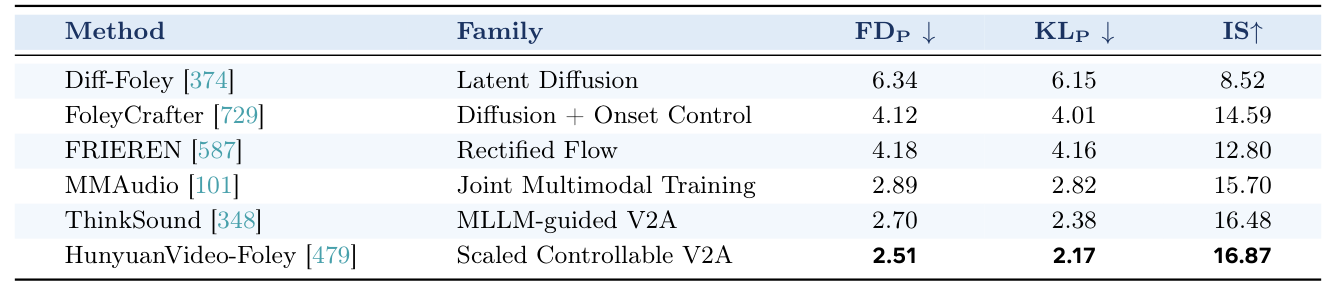
Table 12 — 비디오-오디오 생성 성능을 정량적으로 입증하는 핵심 결과 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 시청각 지능을 통합하는 포괄적인 프레임워크를 제시함으로써, 향후 연구자들이 복잡한 멀티모달 환경을 모델링하는 데 필요한 학술적 기반을 마련했습니다. AVI 분야가 단순히 데이터를 정렬하는 단계를 넘어, 인과적 사건 인지(Causal event-source grounding)와 상호작용이 가능한 지능형 에이전트로 발전하고 있음을 시사합니다. 이 연구는 산업계에서 진행 중인 대규모 범용 모델 구축의 가이드라인을 제공하며, 학계에는 안전성, 보안, 데이터 거버넌스라는 새로운 과제를 던져줍니다. 최종적으로 본 연구는 시청각 데이터가 AI의 핵심 인지 축이 되어 로봇, 디지털 휴먼, 메타버스 등 실생활 영역 전반에 영향을 미칠 것임을 예견합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From Spatial to Actions: Grounding Vision-Language-Action Model in Spatial Foundation Priors
- [논문리뷰] Where to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
- [논문리뷰] ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
- [논문리뷰] NitroGen: An Open Foundation Model for Generalist Gaming Agents
- [논문리뷰] Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Review 의 다른글
- 이전글 [논문리뷰] AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
- 현재글 : [논문리뷰] Audio-Visual Intelligence in Large Foundation Models
- 다음글 [논문리뷰] Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes
댓글