[논문리뷰] Does Synthetic Layered Design Data Benefit Layered Design Decomposition?
링크: 논문 PDF로 바로 열기
저자: Kam Man Wu, Haolin Yang, Qingyu Chen, Yihu Tang, Jingye Chen, Qifeng Chen, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Layered Design Decomposition: 평면화된(flattened) 래스터 이미지를 개별적인 RGBA 레이어 단위로 분해하여 편집 가능한 상태로 복원하는 작업입니다.
- SynLayers: 본 논문에서 제안하는 대규모 합성 레이어 데이터셋으로, 다양한 소스를 조합하여 구성된 500K 규모의 학습 데이터입니다.
- CLD (Controllable Layer Decomposition): 본 연구의 베이스라인이 되는 최첨단 레이어 분해 프레임워크로, LD-DiT와 MLCA 컴포넌트를 활용합니다.
- VLM-Guided Input Generation: 고가의 수동 주석 대신 Qwen3-VL 모델을 미세 조정하여 레이어의 Bounding Box와 캡션을 자동으로 추론하게 하는 입력 자동화 파이프라인입니다.
- RGBA-VAE: 레이어의 투명도 정보를 보존하며 재구성하기 위한 잠재 공간 기반 표현 모델입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 고품질 레이어드 그래픽 디자인 데이터를 생성하기 위한 스케일러블(scalable)하고 실용적인 대안으로서 순수 합성 데이터의 효용성을 검증하고자 합니다. 기존의 레이어 분해 연구들은 고가의 수동 주석이 달린 희소한 proprietary 데이터를 사용하거나, 구조적 제약이 있는 부분 합성 데이터를 사용함으로써 현대적인 대규모 생성 모델의 데이터 요구량에 미치지 못하는 Scaling 한계를 보입니다. 이러한 제한은 모델의 견고함과 일반화 성능을 저해하며, 결과적으로 "last-mile" 편집의 생산성을 낮추는 원인이 됩니다. 본 논문은 [Table 1]과 같이 기존의 한정적인 데이터셋 환경에서 벗어나, 데이터 중심(data-centric) 접근을 통해 합성 데이터가 레이어 분해 성능을 효과적으로 개선할 수 있는지 조사합니다.

Table 1 — 기존 데이터셋 대비 SynLayers의 규모 및 확장성 비교 데이터
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 다양한 소스에서 추출된 디자인 요소를 low-overlap algorithm을 통해 결합하고, VLM을 사용하여 생성된 캡션으로 주석을 자동화하는 SynLayers 파이프라인을 제안합니다. 제안된 방법은 [Figure 2]와 같이 레이어 분해 모델의 학습을 위한 완전한 합성 데이터셋을 구축합니다. 정량적 평가 결과, 동일한 18K 데이터 샘플 수 기준에서 본 연구의 합성 데이터는 기존의 PrismLayersPro 데이터셋 대비 Layer PSNR (+1.01) 및 Composite PSNR (+0.83)에서 유의미한 향상을 보였습니다. 또한 [Table 2]에 나타난 바와 같이 레이어 수가 13개에서 35개 사이인 복잡한 환경에서도 Mask IoU가 0.901에서 0.910으로 개선되는 등, 합성 데이터의 도입이 레이어 수 분포의 불균형을 해소하고 학습 안정성을 크게 높이는 것으로 확인되었습니다. 최적의 성능은 약 20K-50K 샘플 규모에서 관찰되었으며, 이는 대규모 학습에 필요한 데이터 효율성을 입증합니다.
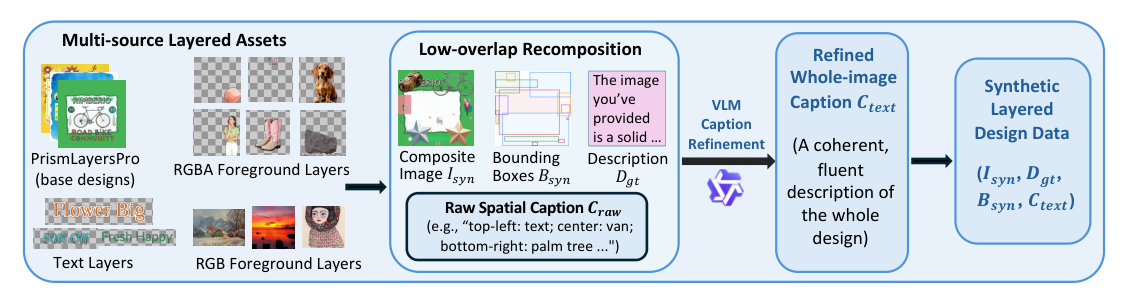
Figure 2 — 제안하는 SynLayers 합성 데이터 구성 파이프라인의 핵심 아키텍처 다이어그램

Table 2 — 데이터 규모에 따른 모델 성능 지표 변화를 보여주는 핵심 정량적 비교 결과
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 합성 데이터가 레이어드 디자인 분해 모델을 위한 강력하고 스케일러블한 학습 기반이 될 수 있음을 입증하였습니다. SynLayers를 통한 학습은 실제 디자인 데이터의 희소성을 보완하고, 자동화된 입력 생성 파이프라인과 결합하여 실용적인 편집 시스템 구축의 실현 가능성을 제시합니다. 향후 본 연구는 복잡한 블렌딩 모드나 Irregular 디자인 요소로의 확장성을 통해, 학계와 디자인 산업 전반의 콘텐츠 편집 워크플로우를 혁신하는 데 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Autodata: An agentic data scientist to create high quality synthetic data
- [논문리뷰] Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
- [논문리뷰] Cosmos 3: Omnimodal World Models for Physical AI
- [논문리뷰] OCC-RAG: Optimal Cognitive Core for Faithful Question Answering
- [논문리뷰] QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
Review 의 다른글
- 이전글 [논문리뷰] DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
- 현재글 : [논문리뷰] Does Synthetic Layered Design Data Benefit Layered Design Decomposition?
- 다음글 [논문리뷰] Dynamic Latent Routing
댓글