[논문리뷰] Dynamic Latent Routing
링크: 논문 PDF로 바로 열기
저자: Fangyuan Yu, Xin Su, Amir Abdullah, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- GDS (General Dijkstra Search): time-varying reward 함수를 가진 DMDP에서, 중간 목표에 최적인 sub-policy들을 시간적 차원으로 결합하여 전역 최적의 goal-reaching 정책을 찾는 알고리즘입니다.
- DLR (Dynamic Latent Routing): GDS의 "search-select-update" 원리를 언어 모델에 적용하여, 개별 chunk에 대해 discrete latent code를 동적으로 라우팅하고 residual stream을 steer하는 단일 단계 post-training 방법론입니다.
- DMDP (Dynamic Markov Decision Process): reward function이 시간 $t$에 따라 명시적으로 변화하는 유한 기간 MDP 프레임워크입니다.
- Abstraction Ratio (K): 하나의 discrete latent code가 언어 모델의 몇 개의 연속적인 토큰(chunk)을 제어할지를 결정하는 하이퍼파라미터입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 LLM의 post-training 과정에서 기존 discrete latent 주입 방식이 갖는 구조적 파괴와 학습 단계의 비효율성을 해결하고자 합니다. 기존 방법론들은 latent code를 토큰으로 직접 삽입하여 pre-training된 sequence 구조를 훼손하거나, 여러 개의 복잡한 학습 단계를 요구하여 low-data 환경에서 SFT(Supervised Fine-Tuning) 대비 성능이 저조하다는 한계가 있습니다. 저자들은 시간적 차원에서의 정책 결합을 이론적으로 뒷받침하는 GDS 알고리즘을 제안하고, 이를 언어 모델의 residual stream 제어 문제로 치환하여 모델 성능을 개선하고자 합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
DLR은 학습 가능한 policy head를 통해 매 chunk마다 최적의 latent code sequence를 검색하고, 이를 residual stream에 steer vector 형태로 더함으로써 모델의 행동을 조정합니다. 학습은 [Figure 1]에서 묘사된 것과 같이, 예측 가능성을 극대화하는 Information Gain과 global diversity를 유지하는 Marginal Entropy Regularization을 결합한 단일 objective를 사용하여 Search-Select-Update 루프 내에서 수행됩니다. 실험 결과, DLR은 24개의 모델-데이터셋 설정에서 SFT 대비 평균 +6.6 percentage points의 향상을 기록했습니다. 특히 추론 능력이 중요한 GSM8K에서 +10.2 pp, ScienceQA에서 +18.8 pp의 높은 성능 이득을 확인했으며, 이는 [Table 1]에 상세히 보고되었습니다. 또한 ablation 분석을 통해 각 구성 요소가 성능 유지와 codebook collapse 방지에 필수적임을 검증했습니다.
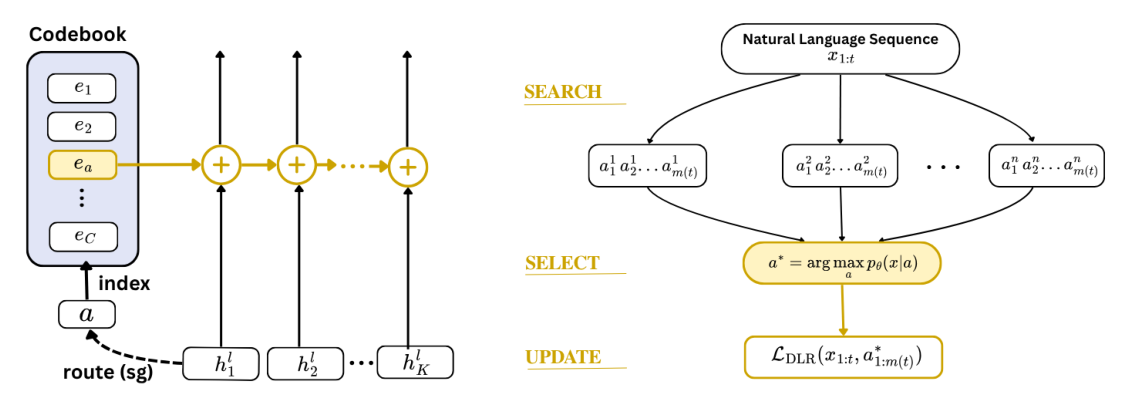
Figure 1 — 전체 모델 아키텍처와 DLR의 핵심 메커니즘을 시각적으로 설명
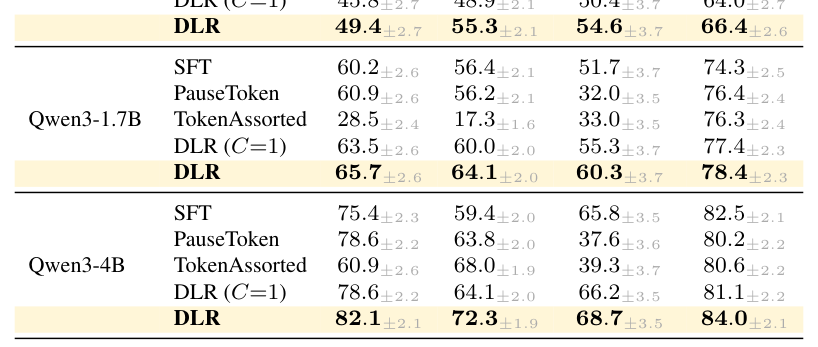
Table 1 — 제안 모델(DLR)과 기존 베이스라인(SFT, PauseToken, TokenAssorted) 간의 정량적 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 dynamic MDP 환경에서의 최적 정책 결합 이론을 LLM의 discrete latent 제어 문제로 성공적으로 확장하여 DLR이라는 효율적인 단일 단계 학습 프레임워크를 정립했습니다. 이 연구는 별도의 subtask 레이블 없이도 모델이 구조화된 routing behavior와 causal representation을 스스로 학습할 수 있음을 보여주며, interpretability 측면에서도 명시적인 discrete code를 통해 모델의 내부 computation을 투명하게 분석하고 개입할 수 있는 새로운 가능성을 제시합니다. 이는 향후 거대 언어 모델의 컴포지션 기반 제어 및 효율적인 미세 조정 기술 발전에 중요한 이론적/실험적 토대가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding
- [논문리뷰] A Geometric Account of Activation Steering through Angle-Norm Decomposition
- [논문리뷰] Monitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
- [논문리뷰] Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
- [논문리뷰] ASA: Training-Free Representation Engineering for Tool-Calling Agents
Review 의 다른글
- 이전글 [논문리뷰] Does Synthetic Layered Design Data Benefit Layered Design Decomposition?
- 현재글 : [논문리뷰] Dynamic Latent Routing
- 다음글 [논문리뷰] EvolveMem:Self-Evolving Memory Architecture via AutoResearch for LLM Agents
댓글