[논문리뷰] Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yize Cheng, Chenrui Fan, Mahdi JafariRaviz, Keivan Rezaei, Soheil Feiz
1. Key Terms & Definitions (핵심 용어 및 정의)
- Model-Adaptive Tool Necessity: 모델마다 서로 다른 capability boundary를 가지므로, 고정된 정답(ground truth)이 아닌 각 모델이 스스로 문제를 해결할 수 있는지 여부를 empirical performance에 기반하여 정의한 tool 사용 필요성입니다.
- Knowing-Doing Gap: LLM이 내부적으로 tool이 필요하다는 인지(cognition)를 형성했음에도 불구하고, 실제 수행 단계(execution)에서 tool 호출 동작(tool-call action)으로 이어지지 않는 현상을 의미합니다.
- Cognition-Execution Modeling: tool 사용 과정을 tool 필요성에 대한 내부적 판단(cognition stage)과 실제 tool 호출 토큰을 생성하는 행동(execution stage)의 2단계로 분리하여 해석하는 분석 프레임워크입니다.
- Representation Probing: 모델의 hidden state 내부에서 특정 정보(예: tool 필요성에 대한 인식, tool 호출 의도)가 linearly decodable한지 확인하기 위해 선형 분류기를 학습시키는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM agent의 Adaptive Tool Use 과정에서 발생하는 성능 저하와 불투명성 문제를 해결하기 위해 모델 고유의 capability에 기반한 Model-Adaptive Tool Necessity 프레임워크를 제안합니다. 기존 연구들은 tool 사용 필요성을 모델의 성능과 관계없이 정적인 속성으로 간주하거나 자명한 경우에만 초점을 맞추어, 모델 간 서로 다른 capability boundary를 간과하는 한계가 있었습니다 [Figure 1]. 이러한 모델-비종속적 접근은 모델이 실질적으로 도움을 필요로 하는지 혹은 스스로 해결 가능한지에 대한 정확한 판단을 내리지 못하게 하며, 결국 불필요한 tool 사용이나 필수적인 상황에서의 호출 누락을 야기합니다 [Figure 2]. 따라서 본 연구는 이러한 문제를 해결하고자 모델의 실질적인 능력을 반영한 새로운 정의를 도입하고, 모델의 내부 인지와 외부 행동 사이의 불일치를 진단하고자 합니다.
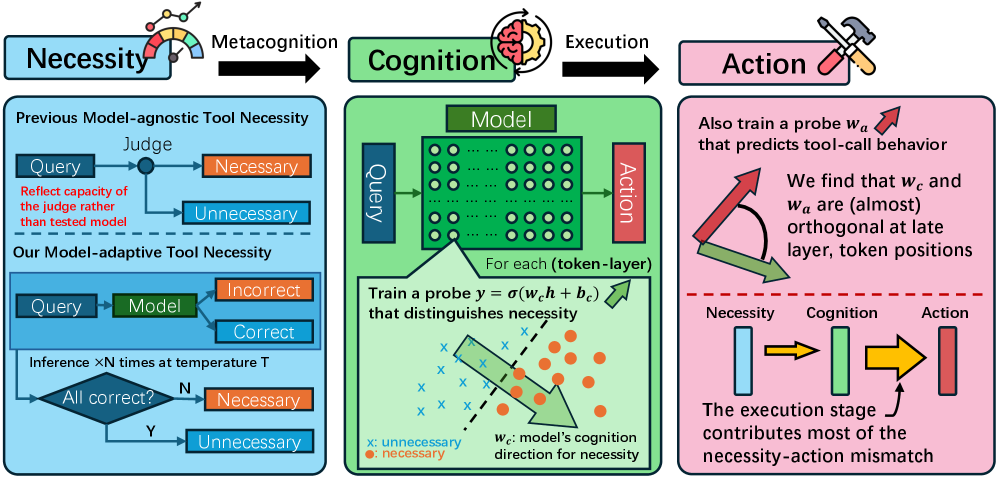
Figure 1 — 모델 기반 tool 사용 2단계 모델링
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 tool 사용을 Cognition 단계와 Execution 단계로 분리하여 각 단계에서의 성능을 Linear Probing을 통해 측정하는 방법을 제안합니다 [Figure 1]. 실험 결과, Arithmetic 및 TruthfulQA 데이터셋에서 모델이 tool 필요성을 내부적으로 인지하고 있음에도 불구하고, end-to-end 단계에서 26.5%–54.0% 및 30.8%–41.8%의 높은 Necessity-Action Mismatch가 발생하는 것을 확인했습니다 [Table 1]. 또한, 내부 인지를 담당하는 벡터 $\mathbf{w}_c$와 실제 행동을 결정하는 벡터 $\mathbf{w}_a$가 mid-layer에서는 일부 유사성을 보이나, generation을 결정짓는 late-layer, last-token regime에서는 서로 orthogonal하게 변한다는 점을 밝혀냈습니다 [Figure 5]. 이러한 기하학적 불일치는 모델이 tool의 필요성을 알고 있음에도 불구하고 이를 적절한 호출 토큰으로 전환하지 못하는 Knowing-Doing Gap의 근본 원인이며, 대부분의 오류가 Cognition 단계를 넘어 Execution 단계에서 발생함을 정량적으로 입증했습니다 [Figure 6].
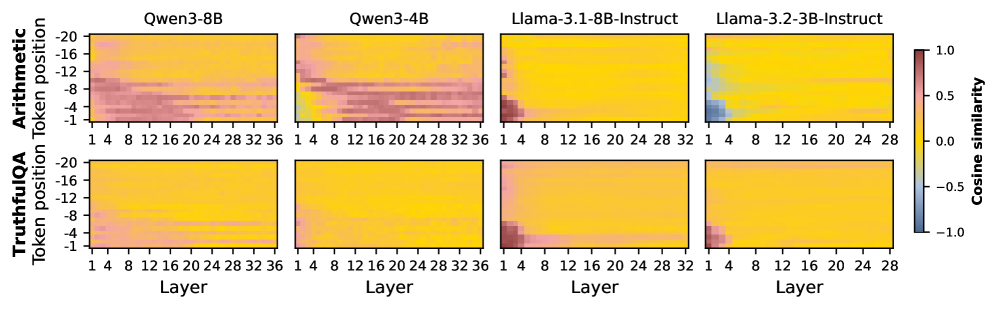
Figure 5 — 인지-행동 벡터 간 코사인 유사도
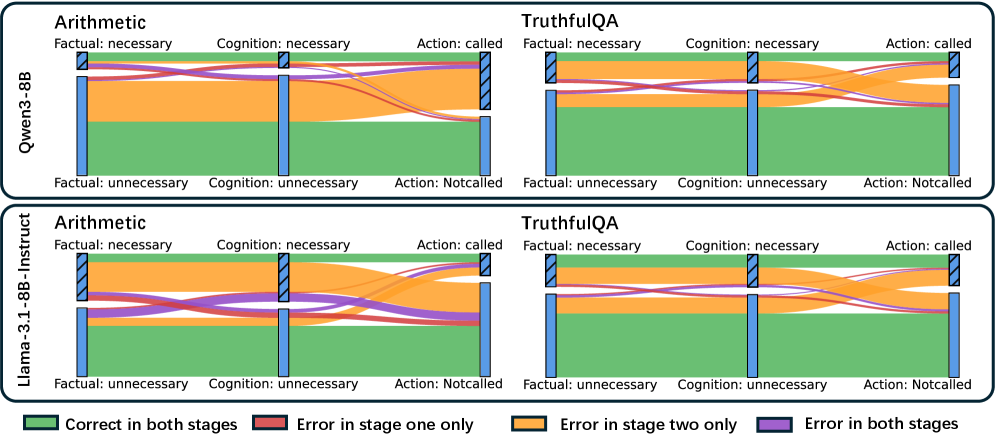
Figure 6 — 인지-행동 단계별 오류 흐름 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM의 tool 사용 실패가 단순히 meta-cognition의 결여 때문이 아니라, 인지된 정보를 행동으로 옮기는 translation 과정의 결함에서 비롯된다는 중요한 통찰을 제시합니다. 이러한 Knowing-Doing Gap 발견은 autonomous agent의 신뢰성을 높이기 위해 단순히 모델의 자가 진단 성능을 개선하는 것을 넘어, 인지된 정보가 실제 실행으로 일관되게 이어지도록 하는 Representation Engineering적 접근이 필수적임을 시사합니다. 본 연구는 학계의 agentic LLM 평가 방식에 중요한 시사점을 주며, 향후 더 견고하고 효율적인 tool 사용 에이전트를 설계하는 데 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DAR: Deontic Reasoning with Agentic Harnesses
- [논문리뷰] Distilling Feedback into Memory-as-a-Tool
- [논문리뷰] AWorld: Dynamic Multi-Agent System with Stable Maneuvering for Robust GAIA Problem Solving
- [논문리뷰] OmniEAR: Benchmarking Agent Reasoning in Embodied Tasks
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
Review 의 다른글
- 이전글 [논문리뷰] MixSD: Mixed Contextual Self-Distillation for Knowledge Injection
- 현재글 : [논문리뷰] Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
- 다음글 [논문리뷰] Monitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
댓글