[논문리뷰] MixSD: Mixed Contextual Self-Distillation for Knowledge Injection
링크: 논문 PDF로 바로 열기
저자: Jiarui Liu, Lechen Zhang, Yongjin Yang, Yinghui He, Yingheng Wang, Weihao Xuan, Zhijing Jin, Mona T. Diab
1. Key Terms & Definitions (핵심 용어 및 정의)
- MixSD: 모델의 기반 분포와 정렬된 지식 주입을 위해 expert-conditioned rollout과 naive-conditioned rollout을 혼합하여 supervision을 생성하는 학습 기법입니다.
- Catastrophic Forgetting: 새로운 지식을 습득하는 과정에서 모델이 기존에 학습한 일반적인 추론 능력이나 지식을 상실하는 현상입니다.
- NLL (Negative Log-Likelihood): 모델의 출력과 실제 타겟 사이의 분포 차이를 측정하는 지표로, 논문에서는 타겟 시퀀스가 기반 모델의 분포와 얼마나 부합하는지를 평가하는 데 사용됩니다.
- Fisher Alignment Ratio: 모델의 파라미터 업데이트 방향이 기반 모델의 중요한(sensitive) 정보를 파괴하는 방향인지를 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM에 새로운 지식을 주입할 때 발생하는 Catastrophic Forgetting 문제를 해결하고자 한다. 기존의 Supervised Fine-tuning (SFT) 방식은 외부에서 작성된 타겟 데이터를 모델에 강제로 주입하는데, 이 타겟 시퀀스가 모델의 사전 학습된 autoregressive 분포와 불일치하는 경우가 많아 모델의 기존 능력을 저하시키는 주요 원인이 된다. 저자들은 이러한 분포 불일치(distribution mismatch)가 파라미터 공간의 민감한 방향으로의 업데이트를 유도한다고 분석한다 [Figure 1]. 따라서 모델의 기존 능력(general-domain performance)을 유지하면서도 새로운 사실을 효율적으로 습득할 수 있는 새로운 접근 방식이 필요하다.
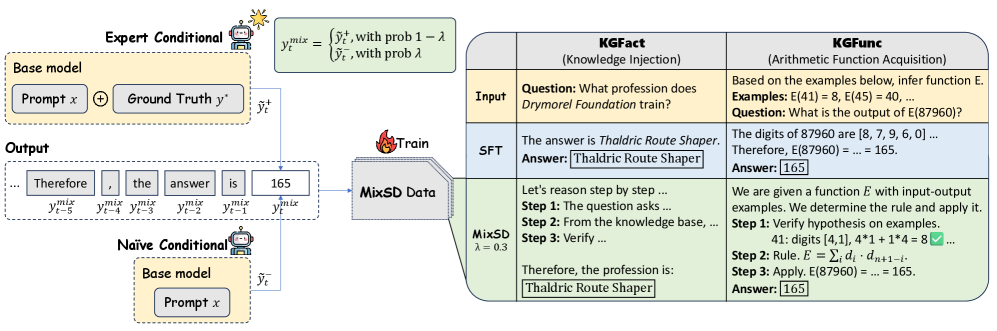
Figure 1 — MixSD의 전체 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 외부 교사 모델 없이 모델 스스로 supervision을 생성하는 MixSD를 제안한다. MixSD는 각 디코딩 스텝에서 새로운 사실을 주입하는 'expert conditional'과 기존의 prior를 반영하는 'naive conditional'을 정의하고, Bernoulli mixing을 통해 타겟 시퀀스를 동적으로 구성한다 [Figure 1]. 이 혼합된 Supervision은 새로운 지식 학습 신호를 유지하면서도 기반 모델의 분포에 가깝게 유지되어, 파라미터 업데이트의 부작용을 최소화한다 [Figure 3].
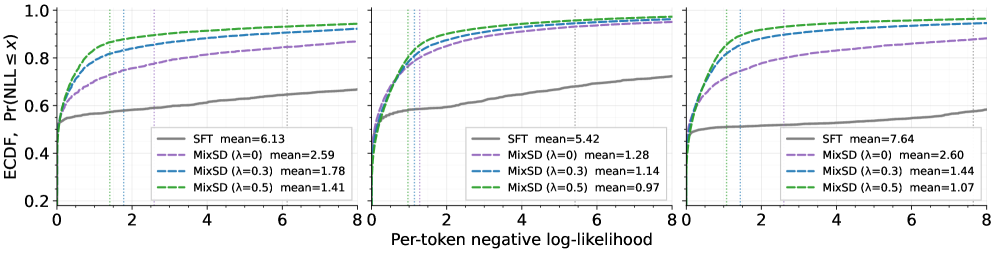
Figure 3 — NLL 분포 비교
실험 결과, MixSD는 다양한 모델 스케일에서 SFT 및 OPSD 대비 월등한 memorization-retention trade-off를 보여주었다. 특히, Qwen3-1.7B/4B/8B 모델군에서 SFT가 일반 도메인 벤치마크(AIME2024, MATH500 등)에서 평균적으로 30-40% 이상의 성능 하락을 보인 반면, MixSD는 학습 정확도를 거의 유지하면서도 기존 능력을 보존하였다 [Table 1, Table 2]. 또한, Fisher alignment ratio 분석을 통해 모델 성능 저하가 업데이트의 크기(magnitude)보다 업데이트의 방향(direction)에 의해 결정된다는 사실을 입증하였다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 모델의 네이티브 생성 분포와 정렬된 supervision을 활용하는 것이 지식 주입 시 발생하는 망각을 방지하는 핵심 원리임을 제시한다. MixSD는 별도의 외부 모델이 필요 없는 간단하고 효율적인 drop-in 방법론으로, LLM의 도메인 적응 및 지식 업데이트 분야에서 중요한 실무적 가치를 지닌다. 이 연구는 모델의 기존 능력을 보존하며 지식을 주입하는 것이 가능함을 증명하였으며, 향후 LLM continual adaptation 연구의 새로운 이정표를 제시한다.
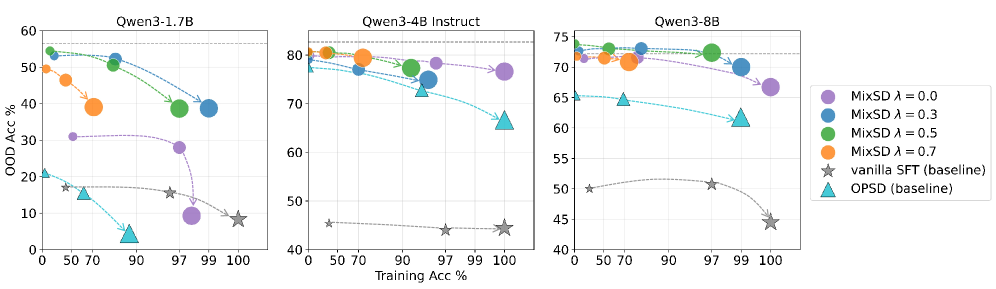
Figure 2 — 학습 정확도와 OOD 성능 트레이드오프
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Denser neq Better: Limits of On-Policy Self-Distillation for Continual Post-Training
- [논문리뷰] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
- [논문리뷰] ResearchMath-14K: Scaling Research-Level Mathematics via Agents
- [논문리뷰] The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes
- [논문리뷰] Online Experiential Learning for Language Models
Review 의 다른글
- 이전글 [논문리뷰] MementoGUI: Learning Agentic Multimodal Memory Control for Long-Horizon GUI Agents
- 현재글 : [논문리뷰] MixSD: Mixed Contextual Self-Distillation for Knowledge Injection
- 다음글 [논문리뷰] Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
댓글