[논문리뷰] Online Experiential Learning for Language Models
링크: 논문 PDF로 바로 열기
저자: Tianzhu Ye*, Li Dong*, Qingxiu Dong, Xun Wu, Shaohan Huang, Furu Wei
1. Key Terms & Definitions (핵심 용어 및 정의)
- Online Experiential Learning (OEL) : 대규모 언어 모델(LLM)이 자체 배포 경험을 통해 지속적으로 개선될 수 있도록 하는 프레임워크입니다. 사용자 측 환경에 접근하거나 reward model 없이, 텍스트 기반 환경 피드백만을 사용하여 학습합니다.
- Experiential Knowledge : 사용자 상호작용 trajectory에서 추출되고 축적되는 transferrable knowledge로, 모델이 특정 환경에서 성공적으로 작동하기 위해 학습하는 규칙, 전략, 통찰 등을 포함합니다.
- On-Policy Context Distillation : OEL의 두 번째 단계로, 축적된 experiential knowledge를 모델 파라미터로 통합하는 과정입니다. 학생 모델이 자체 생성한 trajectory를 기반으로 knowledge-conditioned teacher의 행동을 모방하도록 reverse KL divergence를 사용하여 학습시킵니다.
- Reverse KL Divergence : On-policy context distillation에서 사용되는 loss function으로, 학생 모델의 분포가 teacher 모델의 분포를 cover하도록 하여 mode-seeking behavior를 장려합니다.
- Catastrophic Forgetting : 모델이 새로운 지식을 학습할 때 이전에 학습했던 지식을 잊어버리는 현상으로, OEL은 on-policy 접근 방식을 통해 이를 완화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
현재 대규모 언어 모델(LLM) 개선 패러다임은 주로 offline training에 의존하며, 인간 annotation 또는 simulated environment를 활용합니다. 그러나 이러한 방식은 실제 배포 환경에서 축적되는 풍부한 경험을 전혀 활용하지 못한다는 근본적인 한계가 있습니다. 모델은 배포 전 curated된 데이터와 환경만큼만 우수할 수 있으며, 일단 배포되면 방대하고 끊임없이 변화하는 실제 환경과 상호작용하면서도 아무것도 얻지 못하고 경험이 버려집니다. 또한, 서버 측에서는 사용자 측 환경에 직접 접근할 수 없고, 실제 환경 상호작용은 scalar reward signal 대신 텍스트 피드백만 제공하는 경우가 많아 기존 reinforcement learning 알고리즘을 직접 적용하기 어렵습니다. 이러한 제약 사항들은 raw textual experience만으로 유용한 training signal을 추출하고, reward model이나 verifiable reward 없이도 모델을 지속적으로 개선할 수 있는 새로운 학습 패러다임의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 Online Experiential Learning (OEL) 프레임워크를 제안합니다.
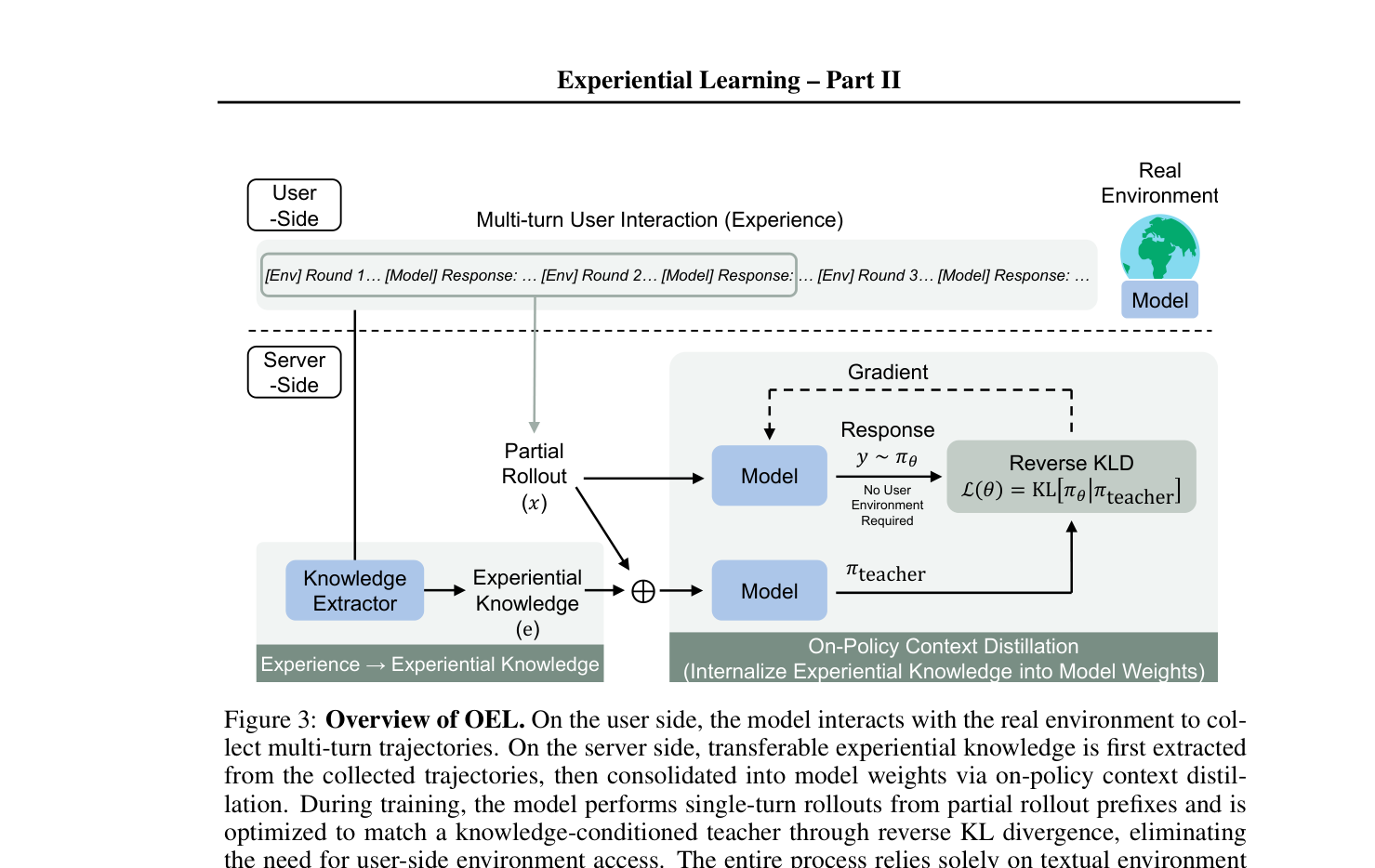 Figure 3: Overview of OEL. On the user side, the model interacts with the real environment to collect multi-turn trajectories. On the server side, transferable experiential knowledge is first extracted from the collected trajectories, then consolidated into model weights via on-policy context distillation. During training, the model performs single-turn rollouts from partial rollout prefixes and is optimized to match a knowledge-conditioned teacher through reverse KL divergence, eliminating the need for user-side environment access. The entire process relies solely on textual environment feedback, requiring no reward model or verifiable reward.
Figure 3: Overview of OEL. On the user side, the model interacts with the real environment to collect multi-turn trajectories. On the server side, transferable experiential knowledge is first extracted from the collected trajectories, then consolidated into model weights via on-policy context distillation. During training, the model performs single-turn rollouts from partial rollout prefixes and is optimized to match a knowledge-conditioned teacher through reverse KL divergence, eliminating the need for user-side environment access. The entire process relies solely on textual environment feedback, requiring no reward model or verifiable reward.
에서 볼 수 있듯이, OEL은 두 가지 주요 단계로 구성됩니다. 첫째, Experiential Knowledge Extraction 단계에서는 사용자 측에서 수집된 multi-turn interaction trajectory로부터 transferrable experiential knowledge가 추출 및 축적됩니다. 이 과정은 reward-free로 진행되며, π_extract 모델을 사용하여 이루어집니다. 둘째, Knowledge Consolidation 단계에서는 축적된 knowledge가 on-policy context distillation [YDW+26]을 통해 모델 파라미터에 통합됩니다. 이는 학생 모델 π_θ가 knowledge-conditioned teacher의 행동을 모방하도록 reverse KL divergence 를 최소화하는 방식으로 학습하며, 사용자 측 환경에 대한 접근 없이 서버 측에서만 이루어집니다. 이 두 단계는 반복적으로 수행되어 모델의 성능이 향상될수록 더 높은 품질의 trajectory를 수집하고, 이는 다시 더 풍부한 experiential knowledge로 이어지는 온라인 학습 루프를 형성합니다.
OEL은 여러 모델 규모와 thinking/non-thinking variant에서 일관되고 상당한 성능 향상 을 달성했습니다.
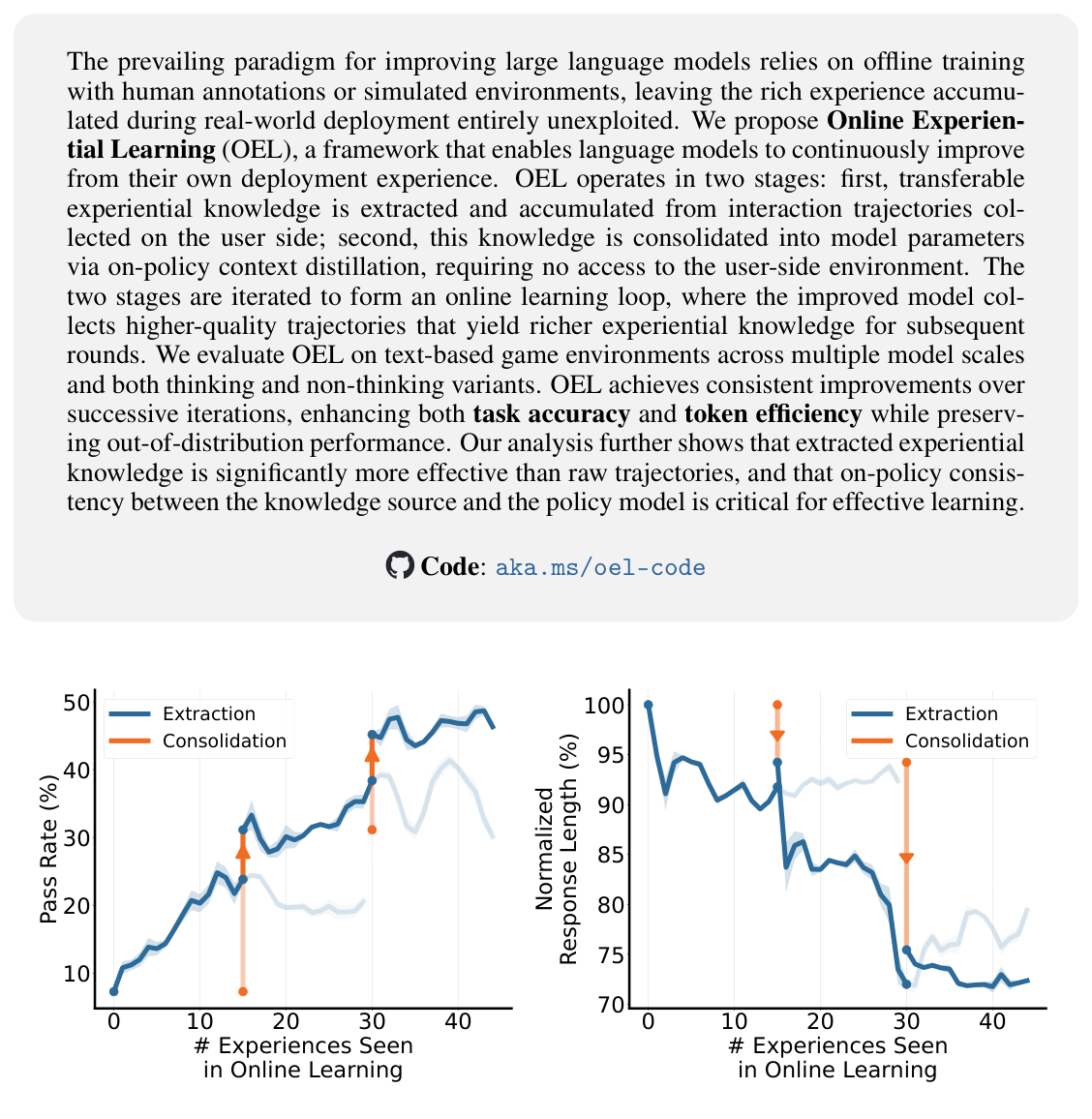 Figure 1: By iterating over experiential knowledge extraction and consolidation stages of OEL, the model can progressively improve pass rate and efficiency (measured by response length) on the environment, effectively achieving online learning.
Figure 1: By iterating over experiential knowledge extraction and consolidation stages of OEL, the model can progressively improve pass rate and efficiency (measured by response length) on the environment, effectively achieving online learning.
에서 볼 수 있듯이, OEL은 successive iteration을 통해 pass rate 를 꾸준히 향상시킵니다. 예를 들어, Frozen Lake 환경에서 초기 10% 미만의 pass rate가 consolidation 후 40% 이상 으로, Sokoban 환경에서는 초기 10% 미만에서 25-30% 이상 으로 개선되었습니다. 또한 OEL은 token efficiency 도 향상시켜, Qwen3-1.7B 모델의 경우 평균 per-turn response length가 세 번째 iteration에서는 초기 길이의 약 70% 로 감소했습니다. 이는 experiential knowledge가 내재화됨에 따라 모델이 더 적은 reasoning effort로 문제를 해결할 수 있음을 의미합니다. 특히
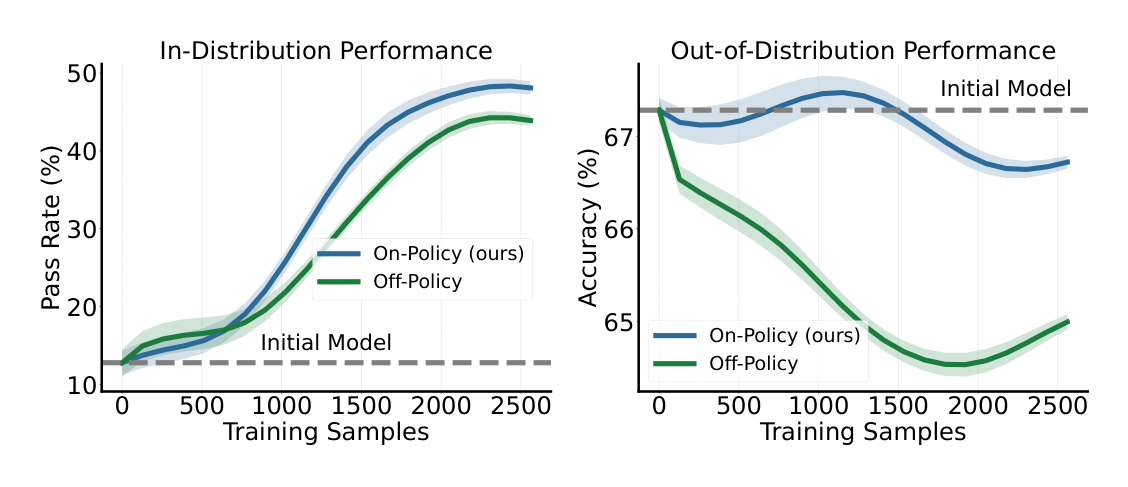 Figure 6: On-policy context distillation in OEL consolidation stage can achieve higher in-distribution (game pass rate) performance while better preserving out-of-distribution (IF-Eval accuracy) performance compared to off-policy context distillation.
Figure 6: On-policy context distillation in OEL consolidation stage can achieve higher in-distribution (game pass rate) performance while better preserving out-of-distribution (IF-Eval accuracy) performance compared to off-policy context distillation.
에 나타난 바와 같이, OEL에 사용된 on-policy context distillation 은 out-of-distribution performance (IF-Eval accuracy)를 초기 모델 수준으로 크게 보존 하여, off-policy 방식 대비 catastrophic forgetting 을 효과적으로 완화하는 것으로 나타났습니다. 또한, 실험 결과 추출된 experiential knowledge 는 raw trajectory보다 훨씬 효과적이며, knowledge source와 policy model 간의 on-policy consistency 가 효과적인 학습에 매우 중요함이 밝혀졌습니다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Online Experiential Learning (OEL) 이라는 reward-free 프레임워크를 도입하여, 언어 모델이 자체 배포 경험을 통해 지속적으로 개선될 수 있도록 합니다. OEL은 사용자 상호작용 trajectory에서 transferrable experiential knowledge를 추출하고 이를 on-policy context distillation 을 통해 모델 파라미터로 통합하는 반복적인 온라인 학습 루프를 형성합니다. 이 프레임워크는 인간 annotation, reward model 또는 사용자 측 환경에 대한 서버 접근 없이 오직 텍스트 기반 환경 피드백만을 사용하여 작동합니다. OEL은 task accuracy 와 token efficiency 를 향상시키면서도 out-of-distribution performance 를 보존하고 catastrophic forgetting 을 완화하는 등 일관된 개선을 보여줍니다. 이러한 결과는 LLM 개발의 다음 단계에서 실제 환경 배포가 훈련의 끝이 아닌 지속적인 개선의 시작이 되는 새로운 패러다임을 제시하며, LLM이 끊임없이 진화하는 능력을 갖추도록 하는 데 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
- [논문리뷰] MixSD: Mixed Contextual Self-Distillation for Knowledge Injection
- [논문리뷰] Efficient Continual Learning in Language Models via Thalamically Routed Cortical Columns
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
Review 의 다른글
- 이전글 [논문리뷰] One-Eval: An Agentic System for Automated and Traceable LLM Evaluation
- 현재글 : [논문리뷰] Online Experiential Learning for Language Models
- 다음글 [논문리뷰] Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
댓글