[논문리뷰] Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
링크: 논문 PDF로 바로 열기
저자: Daxiang Dong, Mingming Zheng, et al.
키워: End-to-End OCR, Document Intelligence, Layout Analysis, Layout-as-Thought, Vision-Language Model, Key Information Extraction, OmniDocBench
1. Key Terms & Definitions
- Qianfan-OCR : Baidu Qianfan Team이 개발한 4B-parameter end-to-end document intelligence model로, 문서 파싱, 레이아웃 분석, 텍스트 인식 및 시맨틱 이해를 단일 Vision-Language Architecture 내에서 통합합니다.
- Layout-as-Thought : Qianfan-OCR에 도입된 선택적 "사고(thinking)" 단계로,
(think)토큰에 의해 트리거됩니다. 모델은 최종 Output을 생성하기 전에 Bounding Box, Element Type 및 Reading Order와 같은 구조화된 레이아웃 표현을 생성합니다. - End-to-End Architecture : 레이아웃 감지나 텍스트 인식과 같은 개별 단계를 분리하지 않고, 문서 이미지를 Markdown과 같은 구조화된 Output으로 직접 매핑하는 통합 Vision-Language Model 접근 방식입니다.
- OmniDocBench v1.5 : 다양한 PDF 문서 파싱 작업에 대한 시스템 성능을 평가하는 데 사용되는 주요 OCR 벤치마크입니다.
- Key Information Extraction (KIE) : 영수증, 송장, 양식 등 문서에서 특정 핵심 정보를 추출하는 작업을 의미합니다.
2. Motivation & Problem Statement
기존의 OCR 시스템은 비용, 정확도, 기능성 측면에서 Trade-off를 겪고 있습니다. 전통적인 Multi-Stage OCR Pipeline은 복잡한 Preprocessing과 Postprocessing이 필요하며, 단계 간 Error Propagation이 발생하고 텍스트 추출 과정에서 중요한 Visual Context가 손실됩니다. Specialized OCR Large Model은 정확도를 향상시키지만, 여전히 Deployment Complexity와 Error Propagation 문제를 안고 있습니다. 반면, General Vision-Language Models (VLMs)은 광범위한 Multimodal Capability를 제공하지만 Inference Cost가 높고 구조화된 문서 파싱 Task에서 Specialized System 대비 낮은 성능을 보입니다. 또한, End-to-End OCR의 실질적인 한계는 Pipeline System이 Element Localization 및 Type Classification을 위해 제공하던 Explicit Layout Analysis 기능이 없다는 점입니다. 이러한 한계는 Deployment Cost를 높이고 End-to-End Optimization을 제한하며, 복잡한 구성 요소들의 정교한 Orchestration을 요구합니다.
3. Method & Key Results
저자들은 이러한 한계점을 해결하기 위해 Qianfan-OCR 이라는 4B-parameter End-to-End 모델을 제안합니다. 이 모델은 Vision Encoder ( Qianfan-ViT ), Lightweight Projection Adapter, Language Model Backbone ( Qwen3-4B )으로 구성된 Unified Vision-Language Architecture를 채택하여 레이아웃 분석, 텍스트 인식 및 시맨틱 이해를 통합합니다
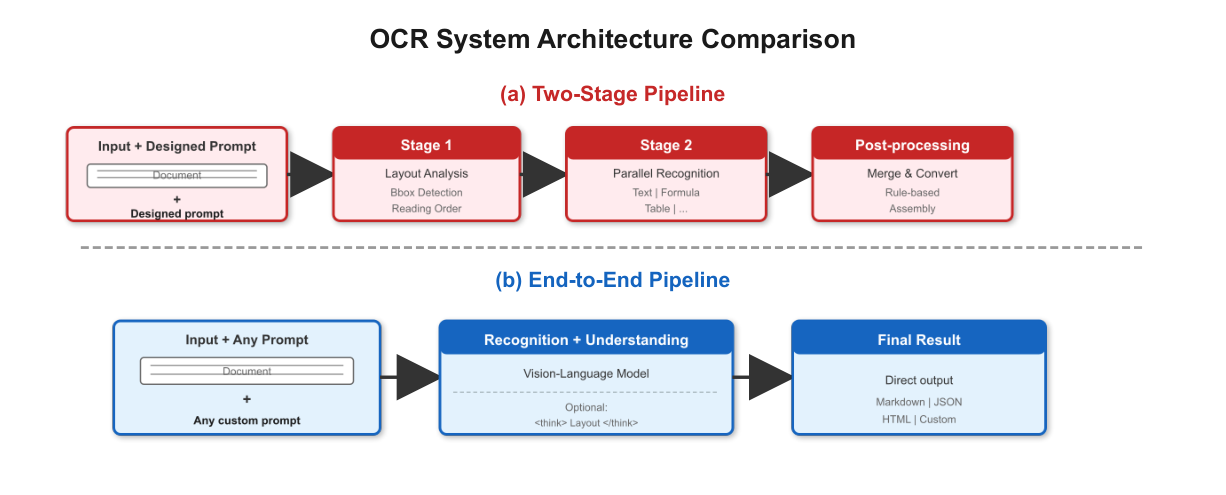 Figure 3: Architectural comparison between traditional two-stage OCR pipeline and Qianfan-OCR's end-to-end approach.
Figure 3: Architectural comparison between traditional two-stage OCR pipeline and Qianfan-OCR's end-to-end approach.
. 특히, Layout-as-Thought 라는 메커니즘을 도입하여 (think) 토큰을 통해 Bounding Box, Element Type, Reading Order 등의 구조화된 레이아웃 표현을 생성하도록 함으로써 End-to-End Paradigm 내에서 Explicit Layout Analysis 기능을 복구하고, 복잡한 레이아웃 문서의 정확도를 향상시킵니다 [Figure 4].
Qianfan-OCR 은 문서 파싱, KIE , 복잡한 테이블, 차트 이해, 수식 인식, 다국어 OCR을 포괄하는 6가지 Large-Scale Data Synthesis Pipeline을 통해 훈련되었습니다. PaddleOCR-VL 의 Fine-Grained Label System을 활용하며, 4단계의 Progressive Training 전략과 OCR-Centric Data Composition을 사용합니다. 실험 결과는 다음과 같습니다:
- OmniDocBench v1.5 에서 Qianfan-OCR 은 End-to-End 모델 중 가장 높은 93.12 의 Overall Score를 달성하여 DeepSeek-OCR-v2 ( 91.09 ) 및 Gemini-3 Pro ( 90.33 )를 능가했습니다
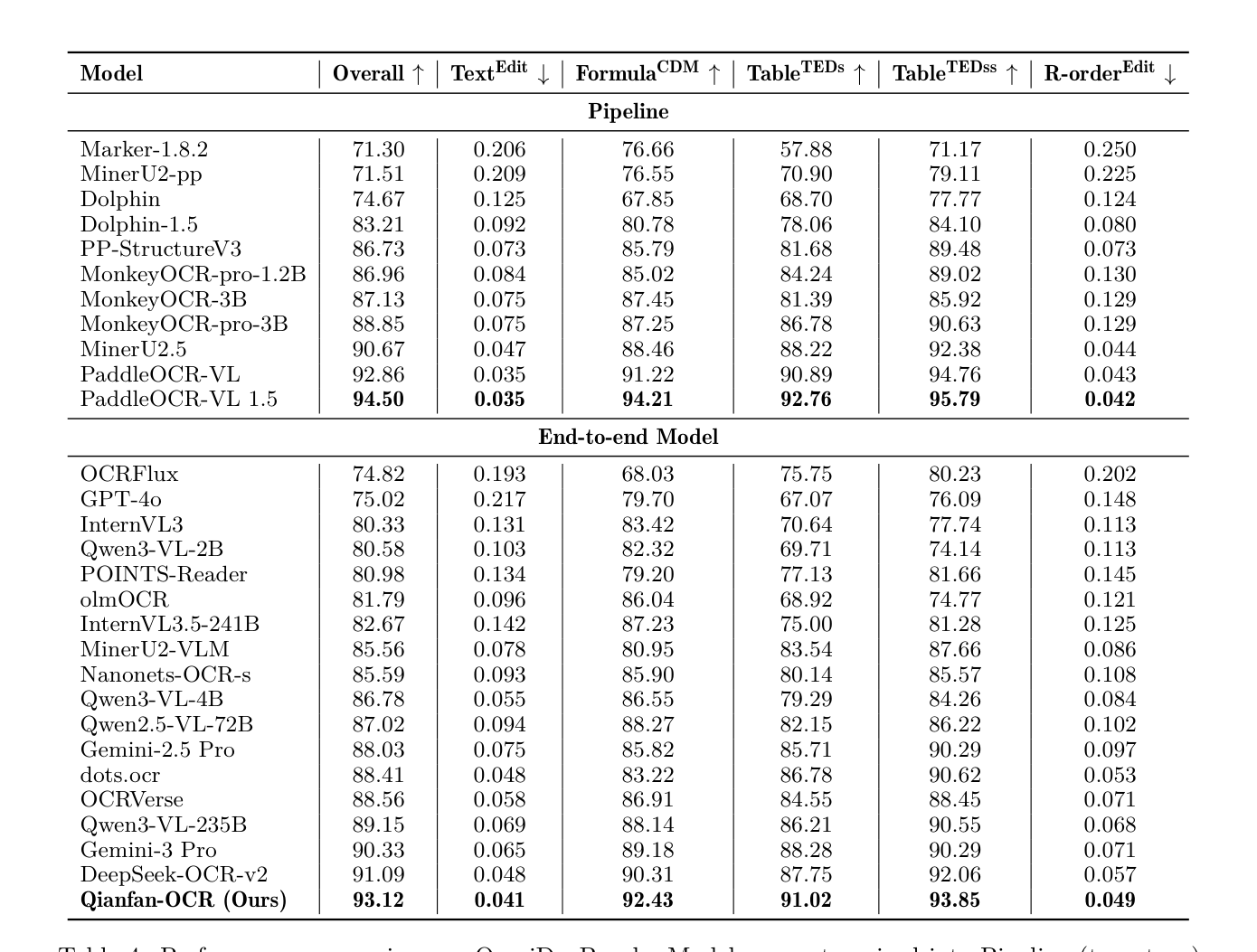 Table 4: Performance comparison on OmniDocBench. Models are categorized into Pipeline (two-stage) and End-to-end architectures. ↑ indicates higher is better, ↓ indicates lower is better. Best results in each section are in bold. Data source: https://github.com/opendatalab/OmniDocBench
Table 4: Performance comparison on OmniDocBench. Models are categorized into Pipeline (two-stage) and End-to-end architectures. ↑ indicates higher is better, ↓ indicates lower is better. Best results in each section are in bold. Data source: https://github.com/opendatalab/OmniDocBench
. 또한, Pipeline System인 PaddleOCR-VL 1.5 ( 94.50 )와도 경쟁력 있는 성능을 보였습니다.
- OlmOCR Bench 에서도 End-to-End 모델 중 가장 높은 79.8 을 기록하며 PaddleOCR-VL ( 80.0 )에 필적하는 성능을 보였습니다 [Table 3].
- Document Understanding Benchmarks 에서 Qianfan-OCR 은 8개 중 6개 벤치마크에서 Two-Stage OCR+LLM System 및 다른 End-to-End 모델보다 우수한 성능을 보였으며, 특히 차트 및 학술 추론 Task (예: CharXiv_DQ 94.0 , ChartQA 88.1 )에서 강점을 나타냈습니다
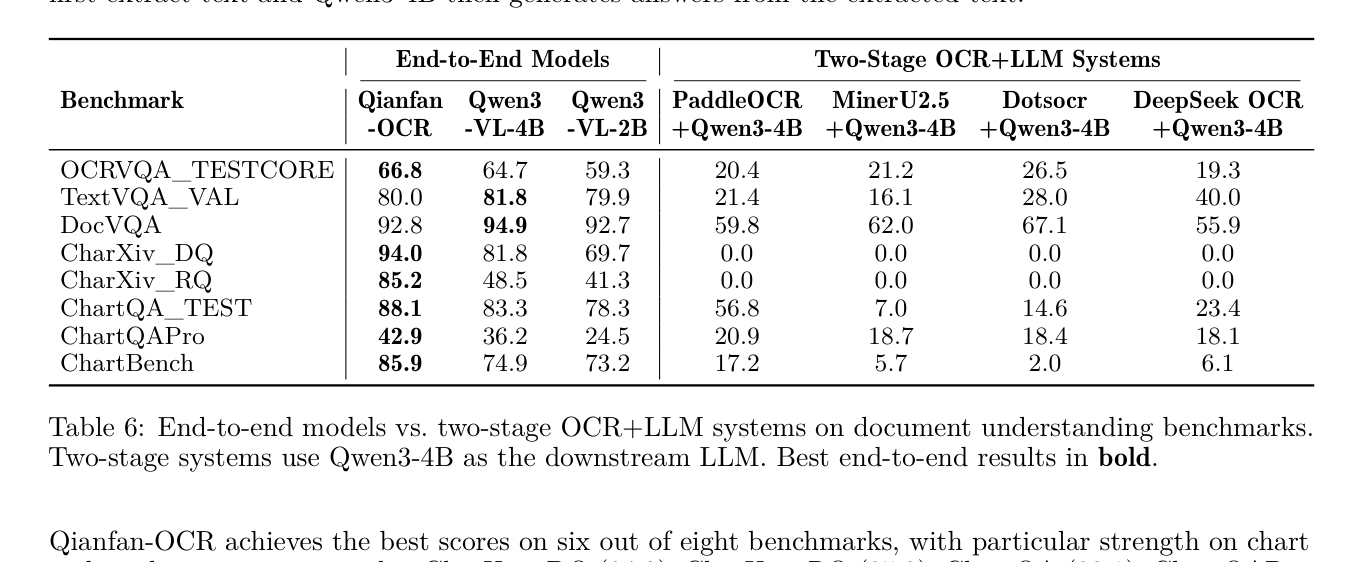 Table 6: End-to-end models vs. two-stage OCR+LLM systems on document understanding benchmarks. Two-stage systems use Qwen3-4B as the downstream LLM. Best end-to-end results in bold.
Table 6: End-to-end models vs. two-stage OCR+LLM systems on document understanding benchmarks. Two-stage systems use Qwen3-4B as the downstream LLM. Best end-to-end results in bold.
. Two-Stage System은 CharXiv 에서 0.0 의 점수를 기록하며 Visual Context의 중요성을 명확히 보여주었습니다.
- KIE Benchmarks 에서 Qianfan-OCR 은 5개 Public Benchmarks에 걸쳐 87.9 의 가장 높은 Overall Mean Score를 기록하며, Gemini-3.1-Pro 및 Qwen3-4B-VL 등 상용 및 Open-Source 모델을 뛰어넘었습니다 [Table 7].
- Inference Throughput 측면에서, W8A8 Quantization 을 적용한 Qianfan-OCR 은 1.024 PPS (Pages Per Second) 를 달성하여 PaddleOCR-VL ( 1.224 PPS )에 필적하며 다른 End-to-End 모델을 능가했습니다 [Table 8]. 이는 GPU-Centric Computation 및 Efficient Batching 덕분입니다.
4. Conclusion & Impact
Qianfan-OCR 은 텍스트 인식, 레이아웃 분석, 시맨틱 이해를 단일 Vision-Language Model로 통합한 4B-parameter End-to-End 모델의 초기 탐색을 성공적으로 제시합니다. 이 모델은 OmniDocBench v1.5 및 OlmOCR Bench 와 같은 Specialized OCR 벤치마크에서 End-to-End 모델 중 State-of-the-Art 성능을 달성하며, End-to-End Architecture가 인식 정확도 측면에서 Pipeline System과 경쟁할 수 있음을 입증합니다. 특히, Layout-as-Thought 메커니즘은 End-to-End OCR의 Explicit Layout Analysis 기능 부재라는 한계를 효과적으로 해결하여 복잡한 문서에 대한 구조적 분석을 동적으로 활용할 수 있게 합니다. 이 연구는 Visual Context를 처리 Pipeline 전반에 걸쳐 보존하는 것이 공동 시각 및 텍스트 이해가 필요한 문서 인텔리전스 Task에 상당한 이점을 제공하며, 기존 Two-Stage OCR+LLM Pipeline이 Spatial 및 Visual Reasoning이 필수적인 차트 해석 벤치마크에서 0% 의 정확도를 보이는 등 성능이 크게 저하됨을 보여줍니다. 이러한 결과는 학계 및 산업계에서 보다 효율적이고 정확한 문서 처리 시스템 개발의 중요한 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Online Experiential Learning for Language Models
- 현재글 : [논문리뷰] Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
- 다음글 [논문리뷰] Recursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Context
댓글