[논문리뷰] Recursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Context
링크: 논문 PDF로 바로 열기
저자: Keivan Alizadeh, Parshin Shojaee, Minsik Cho, Mehrdad Farajtabar
키워: Long-Context Reasoning, Self-Reflection, Program Search, Uncertainty Signals, Recursive Language Models, LLMs, Context Interaction
1. Key Terms & Definitions (핵심 용어 및 정의)
- SRLM (Self-Reflective Program Search for Long Context) : 프로그래밍 기반의
context interaction에uncertainty-aware self-reflection기능을 강화한 프레임워크이다. - RLM (Recursive Language Models) :
inference-time에long context를external variable로 취급하고, 모델이sub-queries를 통해context를query,slice,recursively interact하는 프로그램을 생성하도록 하는 접근 방식이다. - Self-Consistency : 여러
sampled program outputs에서 도출된 답변의empirical frequency를 사용하여uncertainty를 정량화하는sampling-based uncertainty신호이다. - Verbalized Confidence : 모델이 각
intermediate generation step에서 자체적으로 보고하는confidence score를 통해 얻는step-level semantic uncertainty신호이다. - Reasoning Trace Length : 생성된
reasoning trace의 총 토큰 길이를 측정하여 모델의epistemic effort를 간접적으로 나타내는implicit behavioral uncertainty신호이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Models (LLMs)는 extended context windows에도 불구하고 long context 내 정보를 신뢰성 있게 추출하고, 추론하며, 활용하는 데 어려움을 겪고 있다. Recursive Language Models (RLMs)는 inference 시 long context를 recursive sub-queries로 분해하여 이 문제에 접근하며 유망한 결과를 보였다. 그러나 RLM의 성공은 context-interaction programs의 trajectories를 어떻게 선택하느냐에 결정적으로 의존하지만, 이 selection mechanism은 제대로 탐구되지 않았다. 기존 RLM은 주로 fixed recursion schemes에 의존하며, alternative reasoning trajectories를 평가하고 선택하는 principled mechanism이 부족하다. 따라서 연구자들은 recursion 자체가 long-context reasoning의 핵심 동력인지, 아니면 uncertainty 하에서 candidate interaction programs를 선택하는 방식이 진정한 bottleneck인지를 규명하는 데 중점을 두었다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구에서는 uncertainty-aware self-reflection을 통해 programming-based context interaction을 강화하는 Self-Reflective Program Search for Long Context (SRLM) 프레임워크를 제안한다
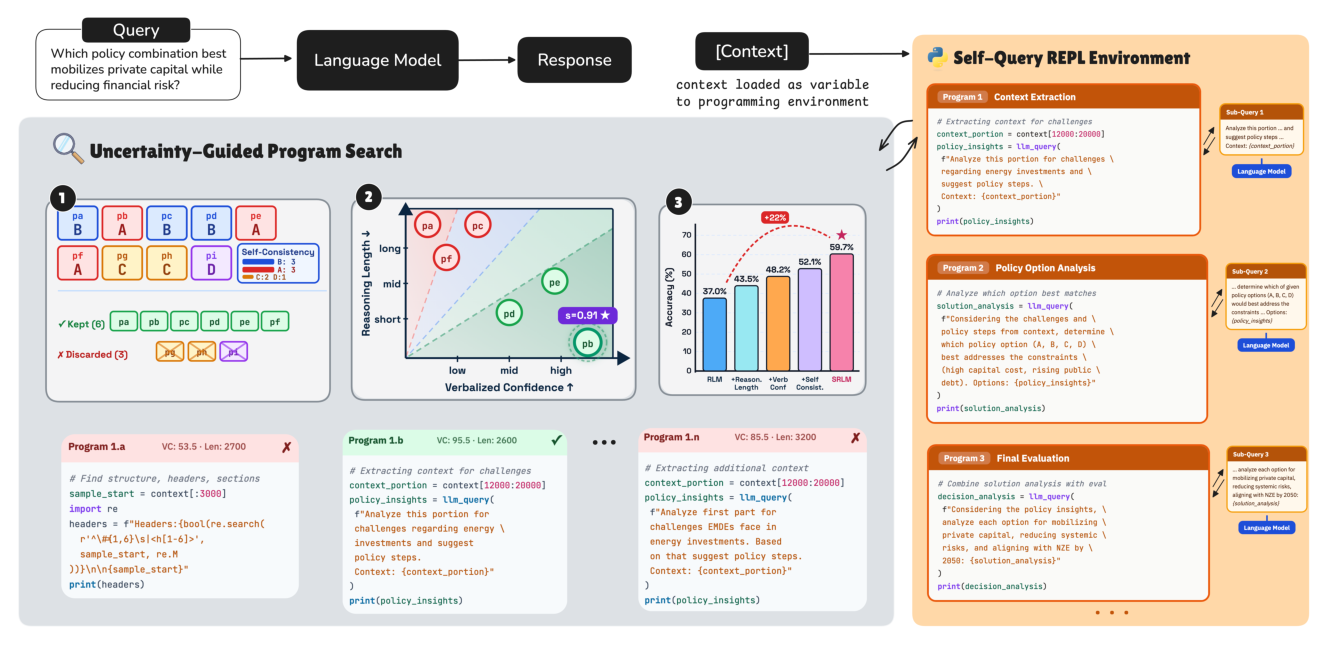 Figure 1: Overview of SRLM, a framework that augments programmatic context interaction reasoning with uncertainty-aware self-reflection. The language model operates in a self-query execution programming environment where the context is externalized as a variable, and generates programs that query and interact with context. Meanwhile, three complementary uncertainty signals (self-consistency, reasoning trace length, and verbalized confidence) are used to guide self-reflective programming trajectory selection without external supervision, enabling more robust and semantically grounded long-context reasoning.
Figure 1: Overview of SRLM, a framework that augments programmatic context interaction reasoning with uncertainty-aware self-reflection. The language model operates in a self-query execution programming environment where the context is externalized as a variable, and generates programs that query and interact with context. Meanwhile, three complementary uncertainty signals (self-consistency, reasoning trace length, and verbalized confidence) are used to guide self-reflective programming trajectory selection without external supervision, enabling more robust and semantically grounded long-context reasoning.
. SRLM은 모델의 내부 uncertainty를 나타내는 세 가지 complementary signals를 활용하여 context-interaction trajectories를 평가하고 비교한다: self-consistency (sampling-based uncertainty), reasoning trace length (behavioral uncertainty), 그리고 verbalized confidence (semantic uncertainty). 먼저 self-consistency를 통해 일관된 candidate set S를 식별한 후, verbalized confidence (VC(p))와 reasoning trace length (Len(p))를 결합한 joint uncertainty score s(p) = VC(p) · Len(p)를 사용하여 최적의 program trajectory를 선택한다. s(p) 값이 낮을수록 더 나은 candidate를 의미한다.
광범위한 실험 결과, SRLM은 다양한 benchmark datasets, context lengths, 그리고 backbone models에서 state-of-the-art baselines, 특히 기존 RLM 대비 최대 22% 의 성능 향상을 보였다
![Table 1: Performance comparison of SRLM against baselines on long-context benchmarks from [75]. Results report accuracy (%) on LongBench-v2 CodeQA, BrowseComp+ (1K documents), and OOLONG (131K tokens). SRLM consistently outperforms all baselines, achieving up to 22% improvement over RLM. * indicates context overflow; † indicates our replication of results; and bold shows best result per LLM backbone.](/paper-images/2026-03-18/2603.15653/table_1.png) Table 1: Performance comparison of SRLM against baselines on long-context benchmarks from [75]. Results report accuracy (%) on LongBench-v2 CodeQA, BrowseComp+ (1K documents), and OOLONG (131K tokens). SRLM consistently outperforms all baselines, achieving up to 22% improvement over RLM. * indicates context overflow; † indicates our replication of results; and bold shows best result per LLM backbone.
Table 1: Performance comparison of SRLM against baselines on long-context benchmarks from [75]. Results report accuracy (%) on LongBench-v2 CodeQA, BrowseComp+ (1K documents), and OOLONG (131K tokens). SRLM consistently outperforms all baselines, achieving up to 22% improvement over RLM. * indicates context overflow; † indicates our replication of results; and bold shows best result per LLM backbone.
. 또한, long context (≥ 131K 토큰)에서 SRLM은 base model 대비 훨씬 뛰어난 gain을 제공했으며, short context (< 131K 토큰)에서도 RLM이 base model보다 성능이 저하되는 경향이 있는 반면 SRLM은 일관되고 robust 한 개선을 보였다
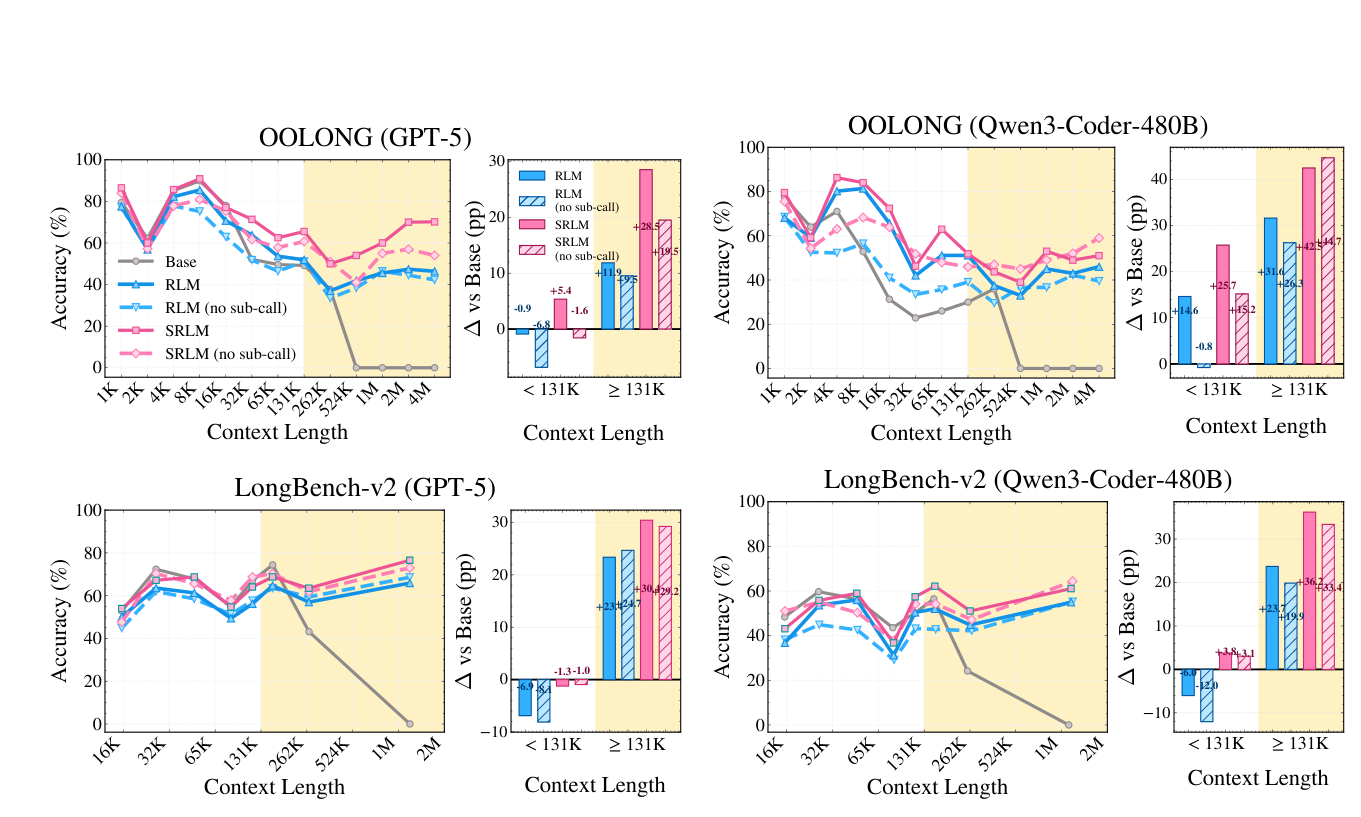 Figure 2: Performance across context lengths on OOLONG and LongBench-v2 Full datasets: Line plots show accuracy of SRLM, RLM, and the base LLM across context from thousands to millions of tokens using GPT-5 (left) and Qwen3-Coder-480B (right) backbones. Bar plots show the average performance gain over the base model, separated into contexts within (<131K) and near/beyond (≥131K) the native context window.
Figure 2: Performance across context lengths on OOLONG and LongBench-v2 Full datasets: Line plots show accuracy of SRLM, RLM, and the base LLM across context from thousands to millions of tokens using GPT-5 (left) and Qwen3-Coder-480B (right) backbones. Bar plots show the average performance gain over the base model, separated into contexts within (<131K) and near/beyond (≥131K) the native context window.
. 특히, SRLM의 self-reflection mechanism은 명시적인 recursion이나 self-query 메커니즘 없이도 RLM의 성능을 능가하거나 유사한 수준을 달성할 수 있음을 보여주었다 [Figure 3]. 이는 recursion이 RLM 성능의 주요 동인이 아니며, heuristic program search가 불충분한 semantically intensive tasks에서 self-reflection이 더 풍부한 semantic signal을 제공한다는 것을 시사한다. 세 가지 uncertainty signals 모두 complementary benefits를 제공하며, 개별 signal만을 사용한 변형보다 전체 SRLM 구성이 지속적으로 우수한 성능을 나타냈다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 intrinsic uncertainty signals인 self-consistency, reasoning trace length, verbalized confidence를 활용한 self-reflective program search 프레임워크 SRLM을 제안하여 long-context reasoning 성능을 크게 향상시켰다. 우리의 분석에 따르면 recursive decomposition 그 자체보다는 external programmatic context interaction이 RLM 성능의 주된 요인이며, 여기에 self-reflection이 더해질 때 long context를 보다 신뢰성 있게 탐색하고 추론할 수 있다. SRLM은 long-context 시나리오뿐만 아니라 RLM이 성능 저하를 보이는 short context에서도 일관된 개선을 보이며, semantically demanding problems에서도 RLM보다 효과적이다. 이 연구는 recursion을 long-context reasoning의 정의적 특징이 아닌 하나의 구성 요소로 재정의하고, context-interaction program trajectories 선택의 중요성을 강조한다. 또한, uncertainty-aware self-reflection이 robust context-interaction frameworks 구축을 위한 간단하고 효과적인 대안이 될 수 있음을 시사하며, 미래 연구에서 더욱 풍부한 intrinsic self-reflection 형태를 탐색하는 방향을 제시한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
- 현재글 : [논문리뷰] Recursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Context
- 다음글 [논문리뷰] Rethinking UMM Visual Generation: Masked Modeling for Efficient Image-Only Pre-training
댓글