[논문리뷰] Rethinking UMM Visual Generation: Masked Modeling for Efficient Image-Only Pre-training
링크: 논문 PDF로 바로 열기
저자: Peng Sun, Jun Xie, Tao Lin, et al.
키워: UMM, Image-Only Pre-training, Masked Image Modeling, Residual Query Adapter, Data Efficiency, Multimodal Large Language Models, Flow Matching, Generative AI
1. Key Terms & Definitions (핵심 용어 및 정의)
- UMM (Unified Multimodal Models) : 심층적인 semantic understanding과 풍부한 perceptual generation을 하나의 모델로 통합하여, dialogue-based image editing이나 context-aware content creation과 같은 복합적인 작업을 가능하게 하는 모델.
- IOMM (Image-Only Training for UMMs) : UMM visual generation을 위한 데이터 효율적인 2단계 training framework로, image-only data pre-training과 mixed data fine-tuning을 통해 성능과 효율성을 개선한다.
- Residual Query Adapter (RQA) : Frozen MLLM의 visual condition을 생성 task에 효율적으로 adapt하기 위해 도입된 경량의 parameter-efficient adapter module.
- Masked Image Modeling (MIM) : Pre-training을 sparse-to-dense reconstruction task로 framing하여 robust visual prior를 학습하도록 유도하는 전략. 이미지 패치 토큰의 일부를 무작위로 마스킹하여 모델이 누락된 부분을 추론하도록 강제한다.
- Flow Matching (FM) Models : Diffusion-based generative model의 일종으로, 사전 정의된 noise-corruption process를 역으로 학습하여 간단한 prior distribution을 복잡한 data distribution으로 변환한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 UMM visual generation component의 pre-training은 비효율적인 paradigm과 희소하며 높은 품질의 text-image paired data에 대한 의존성이라는 중대한 제약에 직면해 있습니다. 이러한 한계는 오픈 및 재현 가능한 연구를 방해하고, 훈련 절차의 비효율성으로 인해 막대한 computational resource를 요구합니다. 결과적으로, 많은 UMM은 제한된 데이터로 fine-tune될 때 textual prompt에 충실하게 align하는 이미지를 생성하는 데 어려움을 겪습니다 [Figure 7a]. 저자들은 이러한 병목 현상을 해결하고, paired data에 대한 의존도를 줄이면서도 성능을 향상시킬 수 있는 데이터 및 compute-efficient training paradigm 개발을 목표로 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 IOMM 이라는 데이터 효율적인 2단계 training framework를 제안합니다. 첫 번째 stage에서는 visual generative component를 풍부한 unlabeled image-only data를 사용하여 pre-train하며, 이로써 비용이 많이 드는 pre-training 단계에서 paired data에 대한 의존성을 제거합니다. 두 번째 stage에서는 unlabeled images와 소수의 curated text-image pairs를 혼합한 dataset을 사용하여 모델을 fine-tune하여 instruction alignment와 generative quality를 향상시킵니다.
핵심 기술 혁신은 두 가지입니다. 첫째, frozen MLLM 의 representation을 generative task에 적응시키기 위해 Residual Query Adapter (RQA) 를 도입합니다. RQA 는 29M parameter 에 불과한 경량 모듈로, cross-attention과 256개의 학습된 query token 을 사용하여 visual condition을 정제하고 MLLM 이 downstream generative task에 더 salient한 feature를 추출하도록 유도합니다. RQA 는 "Raw" MLLM 출력 대비 GenEval 점수를 +0.38 향상시키는 등 그 효과가 [Figure 2b]에서 정량적으로 입증되었습니다. 둘째, self-conditioning이 trivial identity mapping으로 collapse되는 것을 방지하기 위해 Masked Image Modeling (MIM) 전략을 사용합니다. 이는 image patch token의 0.45 마스킹 비율을 통해 training을 sparse-to-dense reconstruction task로 변환하여 모델이 robust하고 compositional visual prior를 학습하도록 강제합니다. MIM 은 GenEval 점수를 추가로 +0.06 향상시켜 생성 품질을 유의미하게 개선합니다 [Figure 2b].
실험 결과, 제안된 IOMM-B (3.6B) 모델은 ~1050 H800 GPU hours (image-only pre-training에 1000시간 이상 할당) 만으로 scratch부터 훈련되었음에도 불구하고 GenEval 에서 0.89 , WISE 에서 0.55 를 달성하여 BAGEL-7B (GenEval 0.82 & WISE 0.52) 및 BLIP3-0-4B (GenEval 0.84 & WISE 0.50) 와 같은 강력한 baseline을 능가하며 SOTA 성능을 보였습니다
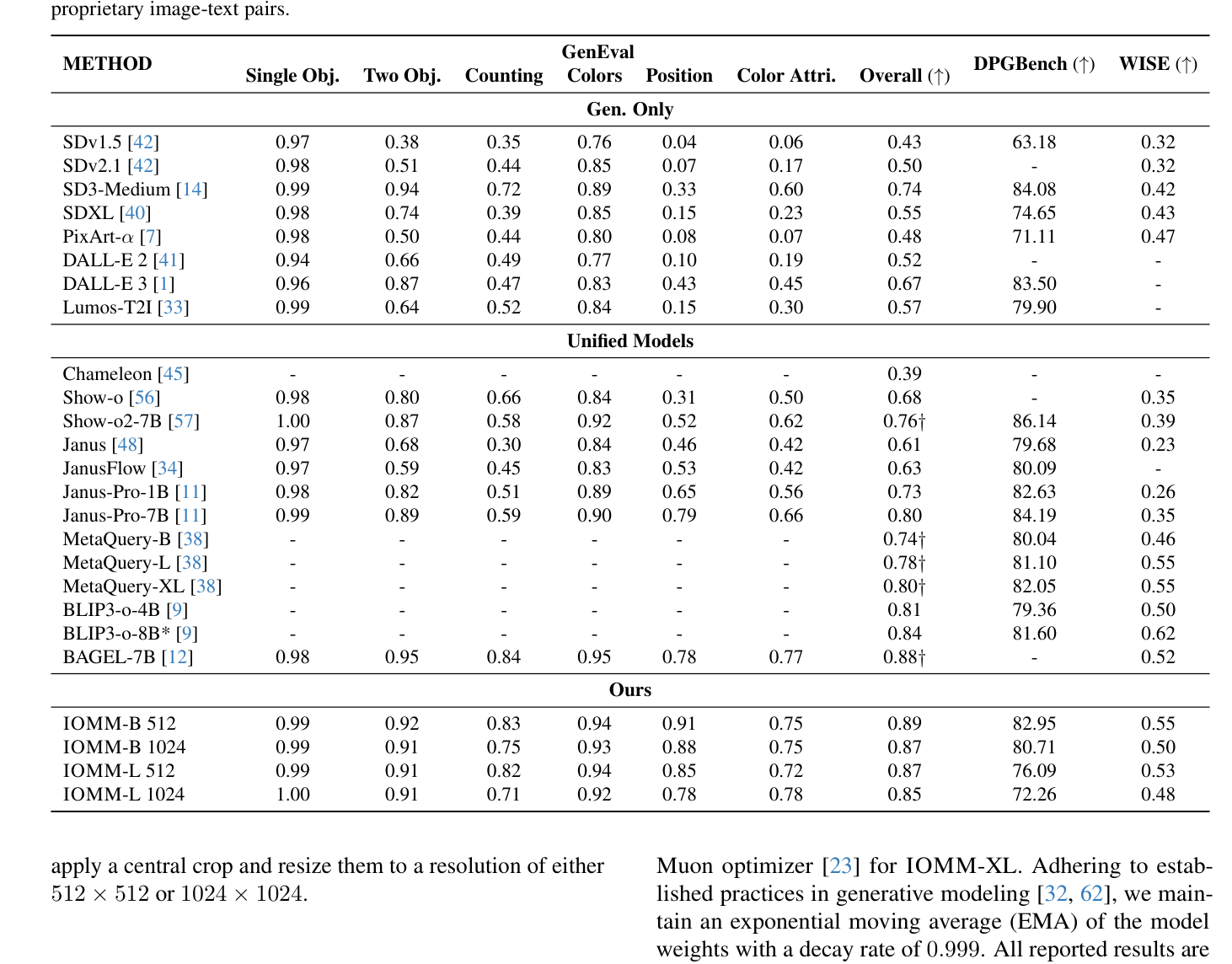 *Table 1: Quantitative comparison on text-to-image generation benchmarks. The (↑) symbol indicates that higher scores are better. *Results obtained using rewritten prompts from the original GenEval benchmark. Indicates the model was trained on an additional 30M proprietary image-text pairs.
*Table 1: Quantitative comparison on text-to-image generation benchmarks. The (↑) symbol indicates that higher scores are better. *Results obtained using rewritten prompts from the original GenEval benchmark. Indicates the model was trained on an additional 30M proprietary image-text pairs.
. 또한, image-only pre-training은 text-image pair pre-training에 비해 일관되게 우수하거나 유사한 성능을 보였고
 Figure 1c: GenEval performance comparison.
Figure 1c: GenEval performance comparison.
, mixed data fine-tuning 전략은 GenEval 에서 가장 높은 성능을 제공했습니다 [Figure 1c, Table 2]. 특히, IOMM 은 training-free setting에서 ImgEdit-Bench 벤치마크에서 2.82 점수를 기록하며 강력한 zero-shot image editing capability를 보여주었으며, 이는 text-image pair pre-trained 모델인 2.61 이나 UltraEdit (2.70) 을 능가하는 수치입니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 UMM visual generation의 주요 병목인 paired data 의존성 및 비효율적인 training paradigm을 해결하기 위한 IOMM 프레임워크를 도입했습니다. image-only pre-training과 mixed-data fine-tuning으로 구성된 2단계 접근 방식은 SOTA 성능과 뛰어난 computational efficiency를 동시에 달성했습니다. 특히, 이 mixed-data fine-tuning 전략은 OpenUni-L 및 Qwen-Image 와 같은 기존의 강력한 UMM 의 instruction-following fidelity 및 image generation quality를 향상시키는 데 효과적인 generalizable technique임을 입증했습니다 [Table 2]. 이 연구는 scarce한 paired data에 대한 의존도를 낮추고 효율성을 극대화함으로써, UMM 분야의 오픈 연구 및 개발에 대한 진입 장벽을 크게 낮추는 데 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Recursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Context
- 현재글 : [논문리뷰] Rethinking UMM Visual Generation: Masked Modeling for Efficient Image-Only Pre-training
- 다음글 [논문리뷰] SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
댓글