[논문리뷰] SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
링크: 논문 PDF로 바로 열기
저자: Tingxu Han, Yi Zhang, Chunrong Fang, et al.
키워: Agent Skills, LLM Agents, Software Engineering, SWE-Skills-Bench, Requirement-Driven Evaluation, Paired Evaluation, Token Overhead, Context Interference
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agent Skills : LLM 에이전트의 소프트웨어 엔지니어링(SWE) 작업을 보강하기 위해 추론 시점에 주입되는 구조화된 절차적 지식 패키지입니다.
- SWE-Skills-Bench : 실제 SWE 시나리오에서 에이전트 스킬의 한계적 유용성을 분리하도록 설계된 최초의 요구사항 기반 벤치마크입니다.
- Requirement-Driven Evaluation : 태스크 성공 여부가 요구사항 문서에 명시된 모든
acceptance criterion충족 여부로 정의되며, 이는 결정론적 테스트를 통해 검증됩니다. - Skill Utility Delta (ΔP) : 스킬 주입 여부에 따른
pass rate차이를 측정하여 스킬의 한계적 이점을 나타내는 지표입니다. - Token Overhead Ratio (ρ) : 스킬 주입 시 발생하는 총 토큰 소비량(입력 + 출력 토큰) 증가율을
no-skill condition대비 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
LLM 기반 에이전트들은 자동화된 코드 생성부터 CI/CD 파이프라인 구성 및 인프라 관리 등 광범위한 software engineering (SWE) 태스크에 점차 활용되고 있습니다. 이러한 에이전트의 역량을 강화하기 위해 Agent Skills는 procedural knowledge, standard operating procedures, code templates 등을 inference time에 주입하는 방식으로 빠르게 채택되고 있습니다. 그러나 이러한 스킬들이 end-to-end development settings에서 실제적으로 얼마나 유용한지, 특히 그 marginal utility가 무엇인지는 여전히 불분명합니다. 기존 벤치마크들(TerminalBench, HumanEval, BigCodeBench, SkillsBench)은 skill augmentation 조건에서 SWE 태스크를 평가하거나 실제 요구사항 만족도를 중심 목표로 하지 않아 이 간극을 메우지 못하고 있습니다. [Figure 1]은 agent skills가 SWE workflow에서 어떻게 사용되는지 보여줍니다. [Table 1]은 기존 벤치마크들과 SWE-Skills-Bench의 차이점을 명확히 보여주며, SWE skill utility를 정량적으로 평가할 수 있는 principled benchmark의 필요성을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 real-world software engineering에서 agent skills의 한계적 유용성을 분리하기 위한 requirement-driven benchmark인 SWE-Skills-Bench 를 제안합니다.
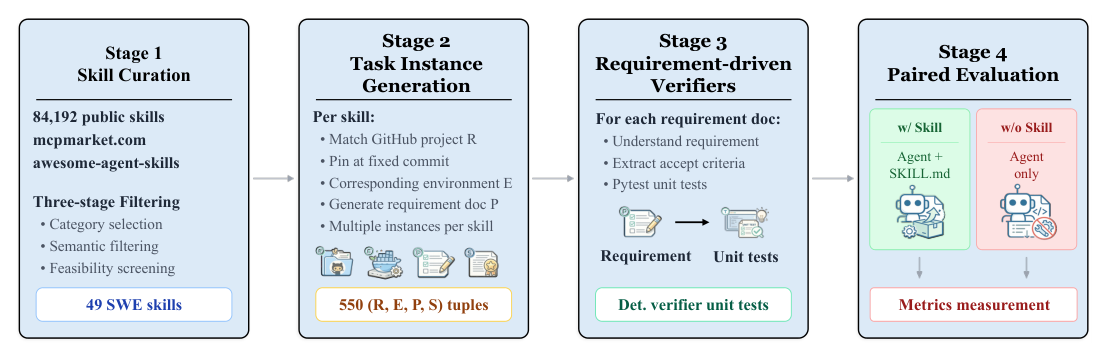 Figure 3: Overview of the SWE-Skills-Bench construction pipeline.
Figure 3: Overview of the SWE-Skills-Bench construction pipeline.
은 벤치마크 구축 파이프라인을 보여줍니다. 먼저, public repository에서 49개 의 SWE skills를 선별하고, 각 스킬에 대해 약 11개 의 task instance를 생성하여 총 565개 의 task instance를 구성했습니다 [Figure 2(a), Figure 2(b)]. 각 task instance는 GitHub project, environment, natural-language requirement document, 그리고 선택적으로 skill document로 구성됩니다 [Figure 4, Figure 7, Figure 8]. 평가 방법론은 requirement-driven verification을 기반으로 하며, 각 acceptance criterion을 결정론적인 pytest unit test로 변환합니다 [Figure 6]. Claude Code (Haiku 4.5) 에이전트를 사용하여 with-skill 및 without-skill 조건에서 paired evaluation을 수행했습니다.
주요 실험 결과
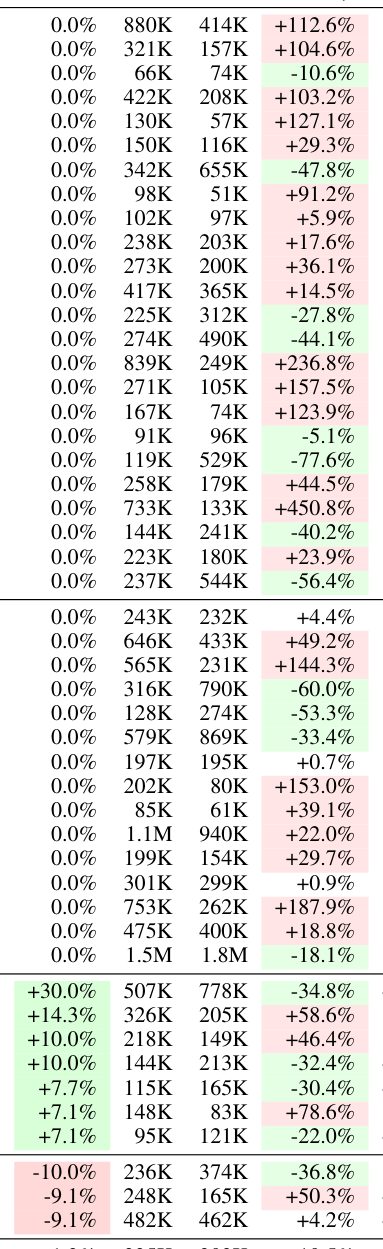 Table 2: Evaluation results across all 49 skills. Pass+ and Pass denote pass rates with and without skill injection, respectively. ΔP is the skill utility delta, C+ and C¯ are average token costs, ρ is the token overhead ratio, and CE is cost efficiency. Best viewed in color.
Table 2: Evaluation results across all 49 skills. Pass+ and Pass denote pass rates with and without skill injection, respectively. ΔP is the skill utility delta, C+ and C¯ are average token costs, ρ is the token overhead ratio, and CE is cost efficiency. Best viewed in color.
는 다음과 같습니다:
첫째, skill injection의 pass rate에 대한 marginal gain은 제한적 이었습니다. 49개 스킬 중 39개(약 80%) 가 ΔP = 0 (pass-rate improvement 없음)을 기록했으며, 평균 pass-rate improvement는 +1.2% 에 불과했습니다 (89.8%에서 91.0%로). 이는 많은 스킬에서 base model이 이미 충분한 capability를 가지고 있음을 시사합니다.
둘째, token overhead는 performance gain과 디커플링 되어 있었습니다. ΔP = 0인 스킬에서도 token overhead ratio (ρ)는 -78% 에서 +451% 까지 넓게 분포했습니다. 예를 들어, service-mesh-observability 스킬은 pass rate 변화 없이 +450.8% 의 token overhead를 발생시켰습니다.
셋째, 7개 의 specialized skills만이 +7.1%에서 +30.0% 까지 의미 있는 gain을 보였습니다. 특히 risk-metrics-calculation 스킬은 ΔP = +30.0%와 ρ = -34.8%를 동시에 달성하여 가장 효과적인 스킬로 나타났습니다.
넷째, 3개 의 스킬(springboot-tdd, linkerd-patterns, django-patterns)은 -10% 까지 negative ΔP를 기록하며 performance를 저하시켰습니다 . 이는 스킬 내 version-specific convention이 target project의 framework와 충돌하여 발생하는 context interference 때문으로 분석됩니다
 Figure 5: Context interference in the linkerd-patterns skill (ΔP = −9.1%). The task requires a Server CRD and a ServerAuthorization CRD enforcing mTLS identity verification for a gRPC service. Left: Template 5 from the injected skill, which near-matches the task but encodes different concrete values: API version v1beta1 with proxyProtocol: HTTP/1, and multiple authorization modes (meshTLS, unauthenticated, and CIDR-based). Center: Without the skill, the agent reasons from first principles and produces a correct solution using v1beta3, gRPC, and standard meshTLS.serviceAccounts. Right: With the skill, the agent's output degrades through three stages, each traceable to a specific region of the template (matched by circled numbers): ① Surface anchoring, the agent copies v1beta1 and HTTP/1 verbatim; ② Hallucination, while reconciling the template's mixed authorization modes, the agent fabricates a nonexistent rules/metricsServers field; ③ Concept bleed, the template's NetworkPolicy example causes the agent to append an unrequested resource, conflating Linkerd-level and Kubernetes-level authorization.
Figure 5: Context interference in the linkerd-patterns skill (ΔP = −9.1%). The task requires a Server CRD and a ServerAuthorization CRD enforcing mTLS identity verification for a gRPC service. Left: Template 5 from the injected skill, which near-matches the task but encodes different concrete values: API version v1beta1 with proxyProtocol: HTTP/1, and multiple authorization modes (meshTLS, unauthenticated, and CIDR-based). Center: Without the skill, the agent reasons from first principles and produces a correct solution using v1beta3, gRPC, and standard meshTLS.serviceAccounts. Right: With the skill, the agent's output degrades through three stages, each traceable to a specific region of the template (matched by circled numbers): ① Surface anchoring, the agent copies v1beta1 and HTTP/1 verbatim; ② Hallucination, while reconciling the template's mixed authorization modes, the agent fabricates a nonexistent rules/metricsServers field; ③ Concept bleed, the template's NetworkPolicy example causes the agent to append an unrequested resource, conflating Linkerd-level and Kubernetes-level authorization.
.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 SWE 환경에서 agent skill injection이 제공하는 이점이 제한적 이며, 그 유용성이 domain fit, abstraction level, 그리고 contextual compatibility에 강하게 의존 한다는 것을 입증합니다. 스킬의 급격한 채택에도 불구하고, skills는 보편적인 performance booster가 아니라 특정 영역에 특화된 intervention임을 시사합니다. 이러한 결과는 agent skills가 context interference라는 구조적 위험을 내포하고 있으며, skill design 시 abstract guidance patterns가 concrete, opinionated templates보다 더 견고한 결과를 가져올 수 있음을 강조합니다. SWE-Skills-Bench는 software engineering agents에서 skills의 설계, 선택 및 배포를 평가하기 위한 중요한 testbed를 제공하며, skill author들에게 empirically grounded guidelines를 제시하는 데 기여할 것입니다. 향후 연구는 multi-model evaluation, diverse agent scaffolds, skill granularity 및 dynamic skill selection 등을 탐구할 예정입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Rethinking UMM Visual Generation: Masked Modeling for Efficient Image-Only Pre-training
- 현재글 : [논문리뷰] SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
- 다음글 [논문리뷰] SegviGen: Repurposing 3D Generative Model for Part Segmentation
댓글