[논문리뷰] SegviGen: Repurposing 3D Generative Model for Part Segmentation
링크: 논문 PDF로 바로 열기
저자: Lin Li, Haoran Feng, Zehuan Huang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- 3D Generative Model : 대규모 3D Textured Asset 데이터셋으로 Pretrain되어 3D Geometry 및 Appearance에 대한 풍부한 Structural Prior를 Internalize한 모델입니다. 본 논문에서는 Trellis.2 [73]를 Base Model로 활용합니다.
- SC-VAE (Sparse Compression Variational Autoencoder) : O-Voxel (Omni-Voxel) Representation 기반의 Voxelized Asset Feature Tensor를 Compact Structured Latent Representation으로 Encoding하고 Decoding하는 역할을 하는 구성 요소입니다.
- Flow-Matching Generator : 시간 의존적 Vector Field
v(zt, t, c)를 학습하여 Compact Latent에서 Efficient Synthesis of Geometry- and Texture-consistent 3D Assets를 가능하게 하는 Conditional Generative Model입니다. - Part-wise Colorization : 3D Part Segmentation Task를 Part-indicative Color를 예측하는 문제로 재정의한 것으로, 각 Color가 개별 Part Label에 해당합니다. 이는 3D Generative Model의 Appearance Modeling Capacity를 활용합니다.
- IoU (Intersection over Union) : Segmentation Task에서 예측된 Mask와 Ground Truth Mask 간의 Overlap 비율을 측정하는 Metric입니다.
IoU@N은 N개의 Foreground Click을 사용하여 얻은 IoU Score를 나타냅니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 3D Part Segmentation 방법론들은 몇 가지 본질적인 한계에 직면해 있습니다. 첫째, 2D-to-3D Lifting 방식은 2D Segmentation Prior를 3D로 전환하는 과정에서 Cross-View Inconsistency 및 Blurred Boundary 문제로 인해 Segmentation Quality가 저하되고, 상당한 Runtime Overhead가 발생합니다. 둘째, Native 3D Discriminative Segmentation 접근 방식은 일반적으로 Large-Scale의 Annotation된 3D Data와 막대한 Training Resource를 필요로 하며, Fine-Grained Annotation의 Cost와 Dataset 간의 Granularity 및 Taxonomy Inconsistency 문제로 인해 Cross-Domain Generalization이 어렵습니다. 이러한 한계점들은 실용적인 3D Content Creation Pipeline 및 Spatial Intelligence 응용 분야에서의 활용을 제한합니다. 저자들은 이러한 문제를 해결하기 위해, Pretrained 3D Generative Model에 Encode된 풍부한 3D Structural 및 Textural Prior를 활용하여 제한된 Supervision만으로도 Accurate하고 Data-Efficient한 Part Segmentation을 달성하는 새로운 Framework의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 SegviGen이라는 통합 Multi-Task Framework를 제안합니다. 이 Framework는 3D Part Segmentation을 3D Latent Space 내에서 Conditional Part-wise Colorization Task로 재정의합니다. 입력 3D Asset X는 Pretrained 3D VAE Encoder E(·)에 의해 Latent Representation z로 Encode되며, 이 z는 Geometry를 지정하는 역할을 합니다. 각 Task에 대해 Part-wise Colorized Target y를 구축하고, Noise가 추가된 Yt = (1-t)y + te를 생성합니다. DiT(Diffusion Transformer) 기반 Backbone은 이 Yt와 Geometry Latent z, Task Condition C, Learned Task Embedding er에 Condition되어 Noise Residual ûo = fo(yt, z, C, er, t)를 예측하도록 Fine-Tuning됩니다. 학습은 Conditional Flow-Matching Objective L(θ) = E[w(t) || ûo – (ε - y)||²]를 따릅니다.
SegviGen은 세 가지 Practical Setting을 Unified Architecture 내에서 지원합니다.
- Interactive Part Segmentation : 사용자 Click Point(
Q)와 Task Embedding을 통해 Denoising Process를 Condition합니다.
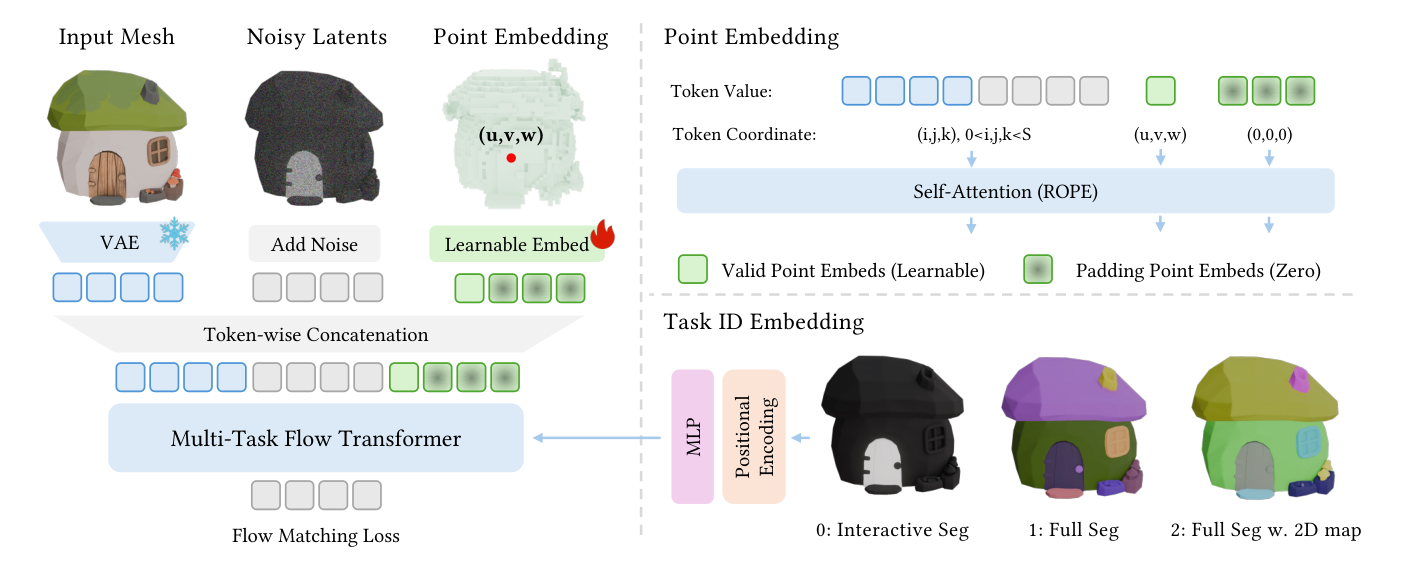 Figure 2: Pipeline of SegviGen. We reformulate 3D part segmentation as a conditional colorization task. During training, given a 3D mesh and its part-color ground truth, we encode both with a pretrained 3D VAE, add noise to the ground-truth latent, and then concatenate the geometry latent, noisy color latent, and point-condition tokens to form the final latent input. Conditioned on the sampled timestep and a task embedding, the multi-task flow transformer predicts the noise residual for flow-matching training.
Figure 2: Pipeline of SegviGen. We reformulate 3D part segmentation as a conditional colorization task. During training, given a 3D mesh and its part-color ground truth, we encode both with a pretrained 3D VAE, add noise to the ground-truth latent, and then concatenate the geometry latent, noisy color latent, and point-condition tokens to form the final latent input. Conditioned on the sampled timestep and a task embedding, the multi-task flow transformer predicts the noise residual for flow-matching training.
는 제안하는 SegviGen Framework의 Pipeline을 보여줍니다.
2. Full Segmentation : Click이나 2D Guidance 없이 Latent 3D Representation으로부터 Part-indicative Color를 직접 생성합니다.
3. Full Segmentation with 2D Guidance : Rendered 2D Segmentation Map(p)을 Guidance로 추가하여 Part Granularity 및 Label Palette에 대한 Explicit Control을 제공합니다.
Extensive Experiment 결과, SegviGen은 Interactive Part Segmentation 및 Full Segmentation 벤치마크에서 이전 SOTA 방법론들을 일관되게 능가하는 성능을 보였습니다.
![Table 1: Comparison of interactive part segmentation performance. We report IoU at different numbers of clicks, compared with Point-SAM [87] and P3-SAM [43] on PartObjaverse-Tiny [79] and PartNeXT [60].](/paper-images/2026-03-18/2603.16869/table_1.png) Table 1: Comparison of interactive part segmentation performance. We report IoU at different numbers of clicks, compared with Point-SAM [87] and P3-SAM [43] on PartObjaverse-Tiny [79] and PartNeXT [60].
Table 1: Comparison of interactive part segmentation performance. We report IoU at different numbers of clicks, compared with Point-SAM [87] and P3-SAM [43] on PartObjaverse-Tiny [79] and PartNeXT [60].
에 따르면, Interactive Part Segmentation에서 SegviGen은 PartObjaverse-Tiny Dataset의 IoU@1에서 42.49% 를 기록하며 Baseline인 Point-SAM( 24.87% ) 및 P3-SAM( 33.04% ) 대비 현저히 우수했습니다. PartNeXT Dataset의 IoU@1에서는 54.86% 를 달성하여 Point-SAM( 23.90% ) 및 P3-SAM( 35.61% ) 대비 큰 폭의 성능 향상을 입증했습니다. 이는 제한된 사용자 Guidance만으로도 강력한 3D Part Structure에 대한 초기 이해를 보여줍니다. Full Segmentation 부문에서는
 Table 2: Quantitative results (IoU) for full segmentation. "w. 2D Map" denotes the setting with 2D segmentation-map guidance.
Table 2: Quantitative results (IoU) for full segmentation. "w. 2D Map" denotes the setting with 2D segmentation-map guidance.
와 같이, 2D Guidance 없이 PartNeXT에서 55.40% 의 Overall IoU를 달성하여 PartField( 41.50% ) 및 SAMPart3D( 29.62% )를 능가하는 Robust Performance를 보였습니다. 2D Guidance를 활용한 SegviGen (w. 2D Map)은 PartObjaverse-Tiny에서 62.98% , PartNeXT에서 71.53% 의 IoU를 기록하며 새로운 SOTA 성능을 달성했습니다. 특히, SegviGen은 단 0.32% 의 Labeled Training Data만을 사용하여 이러한 결과를 달성하여 Pretrained 3D Generative Prior의 Effective Transferability를 강조합니다. 또한, Inference 시 Denoising Step 수에 대한 Ablation Study 결과, 12 Steps 가 Accuracy와 Computational Efficiency 간의 Optimal Balance를 제공함을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Pretrained 3D Generative Model의 Implicit Prior를 3D Part Segmentation Task에 효과적으로 Repurpose하는 SegviGen Framework를 성공적으로 제안했습니다. 이 Framework는 Segmentation을 Part-wise Colorization 문제로 재정의함으로써, 2D-to-3D Lifting 방식의 Cross-View Inconsistency 및 Blurred Boundary 문제와 Native 3D Discriminative 방식의 Large-Scale Annotation 및 Heavy Training 필요성이라는 기존 방법론들의 한계를 극복합니다. SegviGen은 Interactive Part Segmentation, Full Segmentation, 그리고 2D Guidance가 결합된 Full Segmentation을 Unified Architecture 내에서 지원하며, 제한된 Supervision만으로 Accurate하고 Globally Coherent한 Segmentation 결과를 제공합니다.
SegviGen의 등장은 3D Part Segmentation 분야에 상당한 영향을 미칠 것으로 예상됩니다. 특히, Labelled Training Data의 극히 일부만을 사용하여 SOTA 성능을 달성한 점은 Data Efficiency 측면에서 혁신적입니다. 이는 High-Fidelity 3D Part Annotation의 높은 Cost를 줄이고, 적은 데이터로도 복잡한 3D Asset의 Fine-Grained Segmentation을 가능하게 하여 3D Content Creation, Robotics, AR/VR 등 다양한 산업 분야에서 Practical Application의 문을 열 것으로 기대됩니다. Pretrained Generative Prior의 효과적인 Transferability를 입증함으로써, 향후 다른 Downstream 3D Task에서도 Generative Model의 활용 가능성을 확대하는 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Revisiting Diffusion Model Predictions Through Dimensionality
- [논문리뷰] Distribution Matching Variational AutoEncoder
- [논문리뷰] DIMO: Diverse 3D Motion Generation for Arbitrary Objects
- [논문리뷰] MilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
- [논문리뷰] Latent Spatial Memory for Video World Models
Review 의 다른글
- 이전글 [논문리뷰] SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
- 현재글 : [논문리뷰] SegviGen: Repurposing 3D Generative Model for Part Segmentation
- 다음글 [논문리뷰] SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
댓글