[논문리뷰] SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
링크: 논문 PDF로 바로 열기
저자: Tianyu Xie, Jinfa Huang, Yuexiao Ma, et al.
1. Key Terms & Definitions
- Omni-modal Large Language Models (OLMs) : Audio, vision, text를 통합하여 real-time multimodal conversation을 지원하는 LLM.
- SocialOmni : OLM의 사회적 상호작용 능력을 평가하기 위해 제안된 종합 Benchmark.
- Who (speaker identification) : 대화의 맥락에서 현재 발화자를 정확하게 식별하는 능력.
- When (interruption timing control) : 대화의 흐름과 turn-taking 패턴을 분석하여 최적의 발화 Timing을 결정하는 능력.
- How (natural interruption generation) : 진행 중인 대화 Context에 적합하고 Coherent한 반응을 생성하는 능력.
- ∆cons (Consistency Gap) : OLM이 visual-audio alignment에 얼마나 의존하는지 측정하는 지표로, Consistent 및 Inconsistent 데이터셋에서의 Perception Accuracy 차이.
2. Motivation & Problem Statement
기존의 OLM Benchmark들은 주로 static, accuracy-centric 한 이해(understanding) Task에 초점을 맞추고 있어, 자연스러운 대화에서 Dynamic한 Cues를 탐색하는 Social Interactivity의 핵심 역량을 충분히 평가하지 못하고 있습니다.
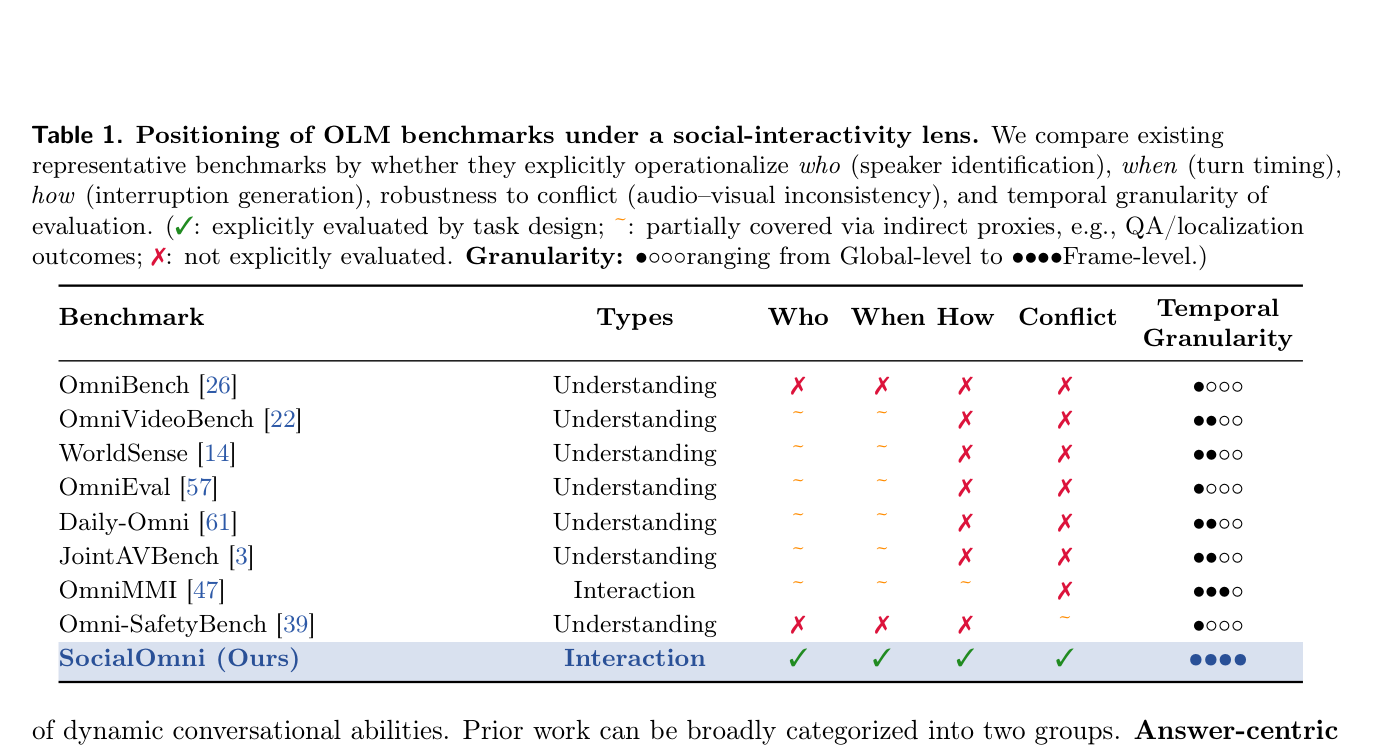 Table 1: Positioning of OLM benchmarks under a social-interactivity lens.
Table 1: Positioning of OLM benchmarks under a social-interactivity lens.
에서 볼 수 있듯이, 대부분의 Benchmark는 who, when, how 같은 Interaction Dimension을 명시적으로 평가하지 않으며, Temporal Granularity도 Frame-level까지 다루는 경우가 드뭅니다. 이러한 한계는 OLM이 올바른 콘텐츠를 생성하는 것을 넘어, 대화에서 언제 발화하고, 누구에게 반응하며, 사회적으로 적절한 방식으로 Interruption을 생성하는 등 Genuine Interaction Competence를 갖추고 있는지 검증하기 어렵게 만듭니다. 따라서 본 연구는 이러한 평가 Gap을 해결하고 OLM의 사회적 상호작용 능력을 포괄적으로 측정할 수 있는 새로운 Benchmark의 필요성에서 출발합니다.
3. Method & Key Results
저자들은 OLM의 사회적 상호작용 능력을 평가하기 위해 세 가지 핵심 Dimension인 who (speaker identification), when (interruption timing control), how (natural interruption generation)를 포괄하는 SocialOmni Benchmark를 제안합니다.
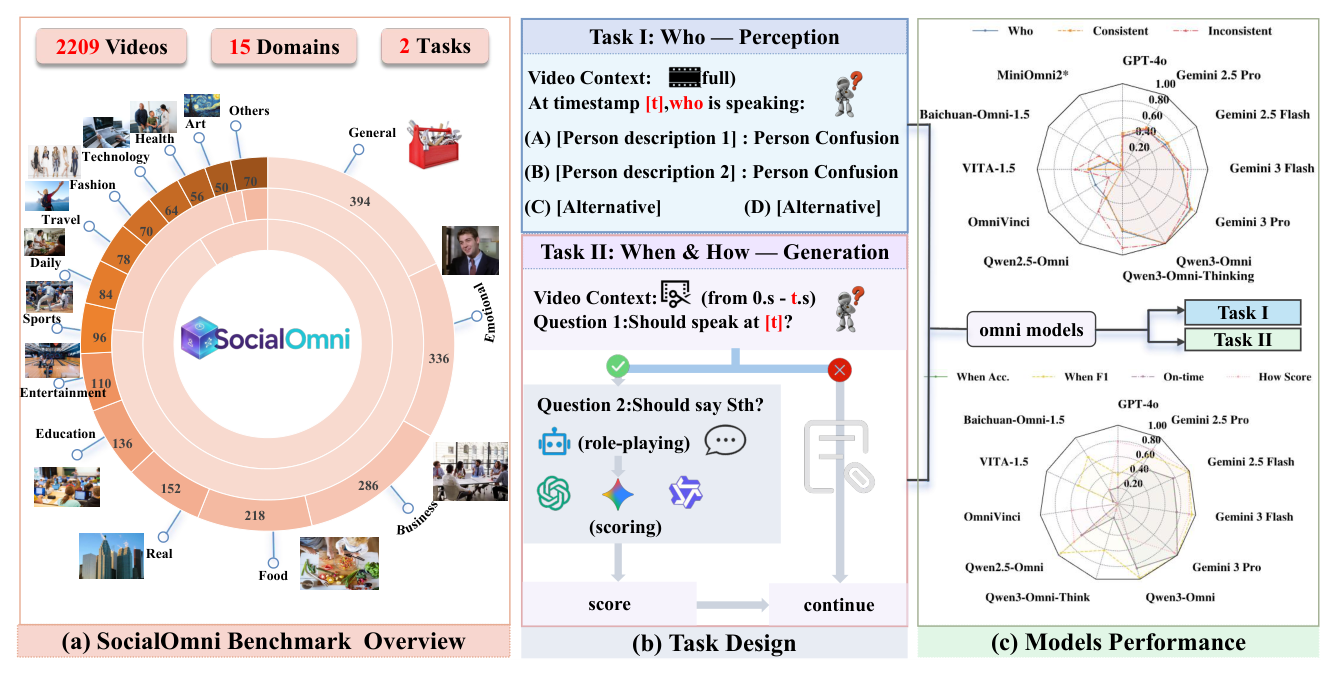 Figure 1: Overview of SocialOmni. (a) Benchmark data distribution across 15 subcategories and four domains, with consistent/inconsistent stratification and perception/generation task splits. (b) Overview of the proposed evaluation tasks and metrics. (c) Performance comparison of 12 OLMs on both Task I and Task II.
Figure 1: Overview of SocialOmni. (a) Benchmark data distribution across 15 subcategories and four domains, with consistent/inconsistent stratification and perception/generation task splits. (b) Overview of the proposed evaluation tasks and metrics. (c) Performance comparison of 12 OLMs on both Task I and Task II.
은 Benchmark의 전반적인 Overview를 보여줍니다.
SocialOmni 는 2,000개의 Perception Sample 과 209개의 Quality-controlled Diagnostic Generation Instance 로 구성됩니다. Perception Task (Task I: Who)는 주어진 Timestamp에서 Audio-Visual Cues를 통합하여 Active Speaker를 식별하는 능력을 측정하며, Top-1 Accuracy 와 Macro-F1 을 사용합니다. Generation Task (Task II: When & How)는 모델이 발화할 최적의 timing을 결정하고 (Binary YES/NO), 이어지는 Response(how)를 생성하는 능력을 평가합니다. When은 On-time Rate O 를 통해, how는 GPT-4o, Gemini 2.5 Pro, Qwen3-Omni를 포함하는 LLM-as-a-judge Protocol 을 사용하여 평가됩니다. 특히, Audio-Visual Inconsistency 시나리오를 도입하여 모델의 Robustness를 테스트합니다.
핵심 결과: 연구팀은 12개의 선도적인 OLM 을 SocialOmni Benchmark에 대해 평가했으며, 주요 정량적 결과는
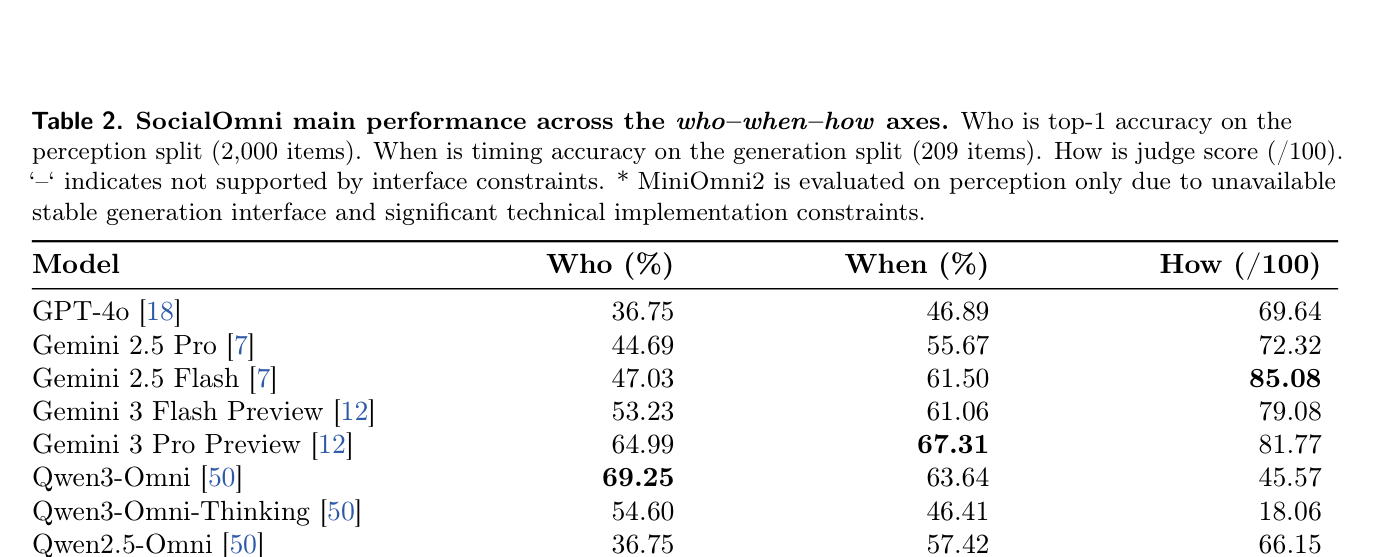 Table 2: SocialOmni main performance across the who-when-how axes.
Table 2: SocialOmni main performance across the who-when-how axes.
에 제시되어 있습니다.
- 모델 간 Social-Interaction Capabilities의 상당한 차이 : Commercial Models (예: Gemini 3 Pro Preview , Gemini 2.5 Flash )가 Open-source Models (예: VITA-1.5 , Baichuan-Omni-1.5 )보다 전반적으로 우수한 성능을 보였습니다. 특히
howDimension에서 Gemini 2.5 Flash 가 85.08 의 Judge Score로 가장 높은 성능을 기록했습니다. - Perceptual Accuracy와 Interruption Generation Quality의 Decoupling : Qwen3-Omni 는
whoTask에서 69.25% 로 가장 높은 Accuracy를 보였으나,howTask에서는 45.57% 로 상대적으로 낮은 성능을 기록했습니다. 반면 GPT-4o 는whoTask에서 36.75% 로 낮은 Accuracy를 보였음에도 불구하고howTask에서는 69.64% 로 준수한 성능을 보였습니다. 이는whoTask에서의 높은 Perceptual Accuracy가howTask에서의 Natural Interruption Generation Quality로 직결되지 않음을 명확히 보여줍니다. - Cross-modal Conflict에 대한 Robustness 부족 : ∆cons 지표를 통해 모델의 Inconsistent 시나리오에서의 성능 저하를 분석했는데, MiniOmni2 가 +13.0% 의 높은 ∆cons를 보여 Visual-Audio Alignment에 대한 높은 의존성을 드러냈습니다.
4. Conclusion & Impact
본 연구는 Omni-modal LLM의 사회적 상호작용 능력을 종합적으로 평가하는 새로운 Benchmark인 SocialOmni 를 제안합니다. 이 Benchmark는 who (speaker identification), when (turn timing), how (interruption generation)의 세 가지 핵심 Dimension을 통합하여 평가하며, 기존 Understanding-centric Benchmark의 한계를 극복합니다. 실험 결과는 모델 간 사회적 상호작용 능력의 큰 Variance와 Perceptual Accuracy와 Generation Quality 사이의 Decoupling 현상을 명확히 보여주었습니다. 이는 단순히 understanding accuracy만으로는 conversational social competence를 완전히 특성화할 수 없으며, interaction-oriented evaluation이 시급하다는 것을 시사합니다. SocialOmni 는 향후 OLM 연구에서 Perception-Interaction Gap을 해소하고, 보다 socially competent한 AI 개발을 위한 Actionable Signal을 제공하는 데 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] Speaker-Aware Temporal Aggregation Strategies on Segment Representations for Depression Detection in Dyadic Interaction: A Benchmark Study
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] When Search Agents Should Ask: DiscoBench for Clarification-Aware Deep Search
Review 의 다른글
- 이전글 [논문리뷰] SegviGen: Repurposing 3D Generative Model for Part Segmentation
- 현재글 : [논문리뷰] SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
- 다음글 [논문리뷰] TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
댓글