[논문리뷰] MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
링크: 논문 PDF로 바로 열기
저자: Xiyu Ren, Zhaowei Wang, Yiming Du, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- LVLM (Large Vision-Language Models): 텍스트와 이미지를 동시에 처리하여 다중 모달 인터랙션을 수행하는 거대 언어 모델 기반 에이전트입니다.
- Memory-Augmented Agents: 외부 저장소를 활용하여 과거 콘텐츠를 압축, 인덱싱하고 선택적으로 검색하는 구조를 가진 에이전트입니다.
- MEMLENS: 본 논문에서 제안하는 5가지 기억 능력(IE, MSR, TR, KU, AR)을 평가하기 위한 다중 모달 장기 기억 벤치마크입니다.
- Cross-modal Token-counting: 텍스트와 시각적 토큰을 표준화하여 문맥 길이를 제어하는 측정 방식입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 LVLM과 Memory-Augmented Agents 간의 기억 능력을 체계적으로 비교할 수 있는 표준화된 벤치마크의 부재를 해결합니다. 기존의 장기 문맥 벤치마크는 주로 텍스트 기반이거나 시각적 정보의 필요성이 낮아 진정한 다중 모달 추론 능력을 검증하지 못한다는 한계가 있습니다. [Figure 1]에서 제시된 파이프라인을 통해 저자들은 다중 세션 대화에서 시각적 증거가 반드시 필요한 789개의 질문을 설계하였으며, 이를 통해 두 가지 서로 다른 기억 접근 방식을 엄격하게 평가하고자 합니다.
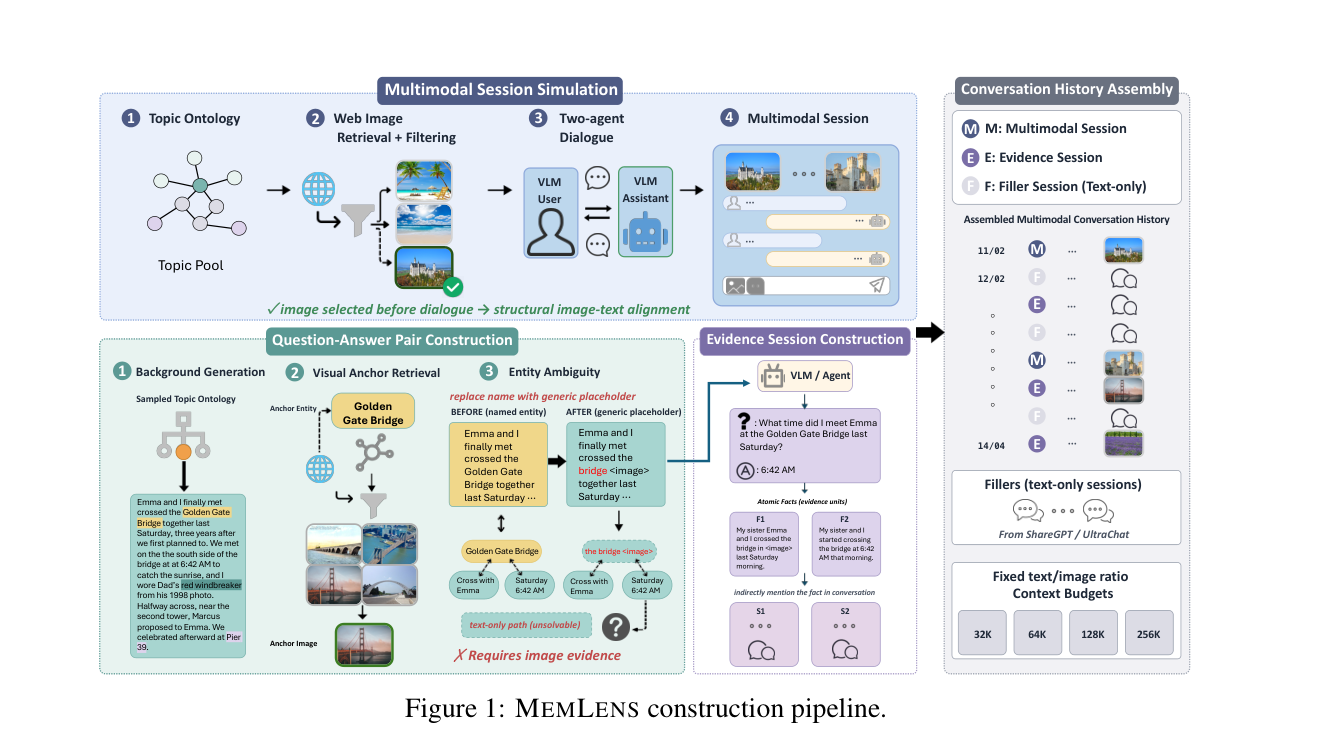
Figure 1 — 데이터셋 구축을 위한 4단계 파이프라인을 설명하는 핵심 구조도
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 다중 세션 대화 히스토리를 시뮬레이션하고 증거 세션과 Haystack 세션을 조합하여 32K에서 256K까지의 문맥 길이를 제어하는 데이터 구축 파이프라인을 제안합니다. [Table 1]에 따르면, MEMLENS는 정보 추출, 다중 세션 추론 등 5가지 기억 능력을 포함하며, 이미지 소거 실험을 통해 문제 해결에 시각적 증거가 필수적임을 검증하였습니다. 실험 결과, long-context LVLM은 짧은 문맥에서는 시각적 그라운딩을 통해 높은 정확도를 보이나 문맥이 길어짐에 따라 성능이 저하되는 반면, memory-augmented agents는 길이 변화에는 안정적이지만 저장 시 압축 과정에서 시각적 충실도가 크게 손실되는 상호 보완적인 실패 모드를 보였습니다. 특히 다중 세션 추론(MSR) 능력은 대부분의 시스템에서 30% 미만의 낮은 성능을 기록하며, 두 접근 방식 모두 완전한 장기 기억 해결책이 아님을 증명했습니다.
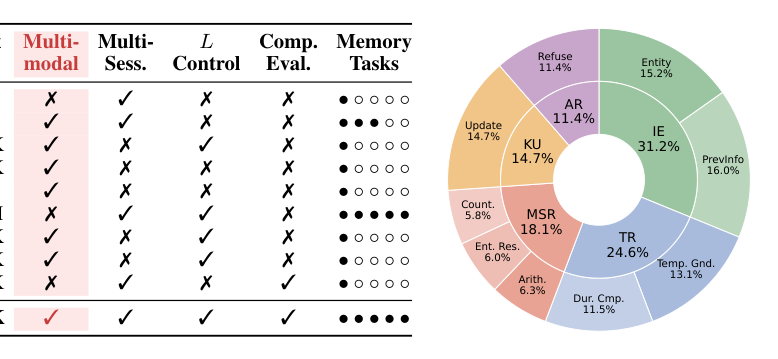
Table 1 — 기존 벤치마크와 MEMLENS의 기능적 차이를 비교한 핵심 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 현재의 장기 기억 구현 방식이 스케일링이나 단순 검색만으로는 충분하지 않으며, 장기 문맥 주의(long-context attention)와 구조적 다중 모달 검색(structured multimodal retrieval)을 결합한 하이브리드 아키텍처가 필수적임을 시사합니다. 본 벤치마크는 다중 모달 에이전트의 개발을 가속화하고, 향후 기억 유지 및 검색 정확도를 높이기 위한 평가 지표로서 중요한 역할을 할 것으로 기대됩니다. 또한 본 연구는 모델의 정보 손실 지점을 파악하여, 캡션 기반의 압축이 아닌 픽셀 레벨의 정보를 보존하는 차세대 기억 설계의 방향성을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond Retrieval: A Multitask Benchmark and Model for Code Search
- [논문리뷰] Omni-SimpleMem: Autoresearch-Guided Discovery of Lifelong Multimodal Agent Memory
- [논문리뷰] Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
- [논문리뷰] MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
- [논문리뷰] VCode: a Multimodal Coding Benchmark with SVG as Symbolic Visual Representation
Review 의 다른글
- 이전글 [논문리뷰] MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory
- 현재글 : [논문리뷰] MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
- 다음글 [논문리뷰] Nexus : An Agentic Framework for Time Series Forecasting
댓글