[논문리뷰] Beyond Retrieval: A Multitask Benchmark and Model for Code Search
링크: 논문 PDF로 바로 열기
저자: Siqiao Xue, Zihan Liao, Jin Qin, Ziyin Zhang, Yixiang Mu, Fan Zhou, Hang Yu
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- COREB: contamination-limited, multitask 환경을 지원하는 코드 검색 및 reranking 벤치마크.
- Graded Relevance:
relevance=2(true positive),relevance=1(hard negative), unjudged (easy negative)로 구성된 3단계 평가 체계. - Hard Negative Intrusion Rate: 상위 10개 결과 내에서 hard negative가 실제 true positive보다 높은 순위에 배치된 비율.
- Reranker: 1차 검색(retrieval) 모델이 반환한 결과의 순위를 정교하게 조정하는 2단계 파이프라인 구성 요소.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 코드 검색 벤치마크 분야는 데이터 오염, 평가 지표의 단일성, 그리고 실제 배포 환경과 괴리된 평가 방식으로 인해 정교한 모델 성능 측정이 어렵습니다. 기존의 CoIR 벤치마크는 단일 관련 문서(1-to-1) 평가 방식과 높은 데이터 오염 위험, 그리고 코드 전문성 없는 일반 모델 기반의 단순 매칭 방식에 의존하여 실제 코드 검색 파이프라인의 복잡성을 제대로 반영하지 못합니다. [Table 17]은 기존 벤치마크의 한계점을 명확히 보여줍니다. 특히, 실제 개발자 환경에서 빈번하게 발생하는 short keyword query에 대한 낮은 대응력과 검색(retrieval) 단계와 reranking 단계 간의 비대칭적 성능 차이가 연구의 핵심적인 개선 과제입니다.

Table 17 — 기존 연구 대비 본 연구의 벤치마크 차별점 분석
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 LiveCodeBench(LCB) 데이터를 counterfactual rewriting 과정을 거쳐 재생성하고, 실행 결과를 기반으로 relevance label을 자동 생성하여 오염을 최소화한 COREB 벤치마크를 제안합니다. 제안된 COREB-RERANKER는 Qwen3-Reranker-4B를 기반으로 LoRA 미세 조정을 수행하며, 300만 개 샘플에 대해 hard negative를 포함한 학습을 통해 3개 작업 모두에서 일관된 성능 향상을 달성했습니다. 실험 결과, C2LLM-7B가 최강의 오픈 가중치 retriever로 검증되었으며, 전반적인 성능에서 코드 전문 모델이 일반 모델보다 압도적임을 확인했습니다. 특히, [Table 3]에 따르면 GemEmb-2가 전반적인 nDCG@10에서 가장 높은 성능을 기록했으나, 단일 모델이 모든 작업을 지배하지는 못함을 보였습니다. [Figure 8]에서 확인할 수 있듯이, 일반 reranker들은 특정 작업에서 오히려 성능을 저하시키는 결과를 보인 반면, COREB-RERANKER는 모든 작업에서 net-positive한 결과를 도출했습니다.
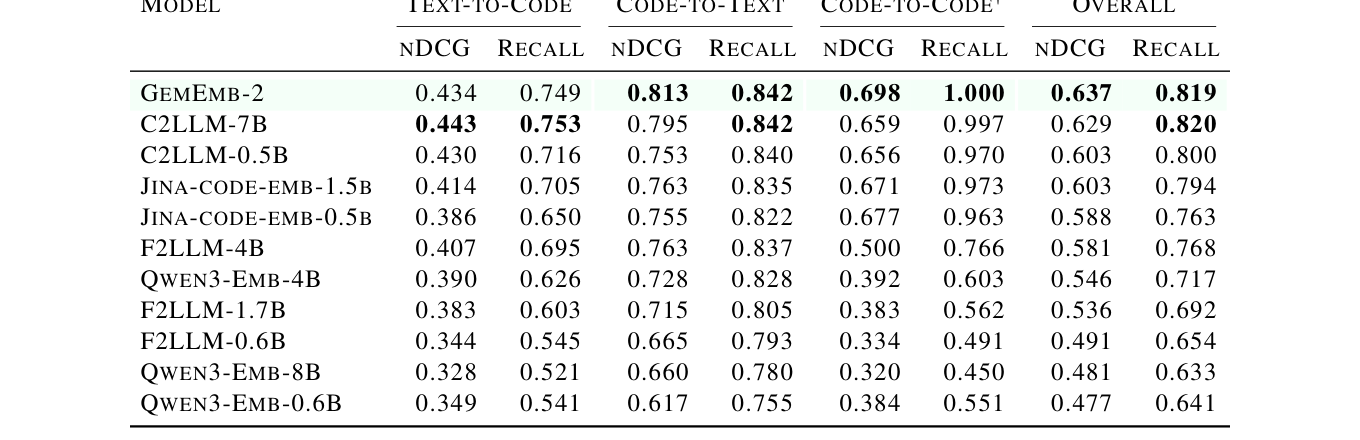
Table 3 — 각 모델별 retrieval 성능을 종합적으로 보여주는 결과 테이블
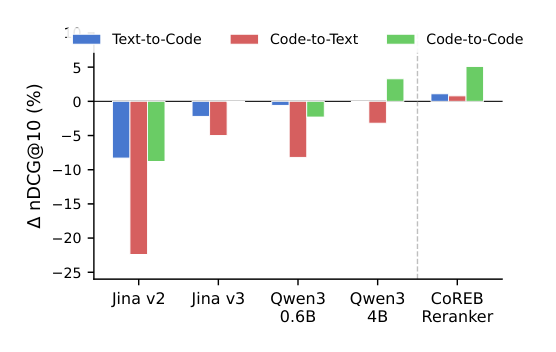
Figure 8 — reranker 모델들의 상대적 성능 개선 폭 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 검색(retrieval)과 재순위화(reranking) 단계를 모두 포괄하는 강력한 코드 검색 벤치마크인 COREB를 통해 코드 검색 평가의 새로운 기준을 제시합니다. 연구 결과, 모델의 규모보다 코드 전문적인 훈련 데이터의 구성이 성능에 더 결정적인 영향을 미침을 입증하였습니다. 또한, 검색된 결과물의 정밀한 재순위화가 실제 AI 에이전트의 코드 파이프라인 성능 향상에 필수적임을 확인하였습니다. 본 연구에서 공개하는 벤치마크와 COREB-RERANKER는 향후 개발자 생산성 도구 및 코드 검색 모델의 실질적인 평가에 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
- [논문리뷰] Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
- [논문리뷰] MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
- [논문리뷰] ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
- [논문리뷰] VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
Review 의 다른글
- 이전글 [논문리뷰] Anisotropic Modality Align
- 현재글 : [논문리뷰] Beyond Retrieval: A Multitask Benchmark and Model for Code Search
- 다음글 [논문리뷰] CASCADE: Case-Based Continual Adaptation for Large Language Models During Deployment
댓글