[논문리뷰] CASCADE: Case-Based Continual Adaptation for Large Language Models During Deployment
링크: 논문 PDF로 바로 열기
메타데이터
저자: Siyuan Guo, Yali Du, Hechang Chen, Yi Chang, Jun Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- DTL (Deployment-Time Learning): LLM이 배포된 후, 모델 파라미터를 수정하지 않고 환경과의 상호작용 및 경험을 통해 행동을 지속적으로 개선하는 LLM 라이프사이클의 제3단계 학습 기법.
- CBR (Case-Based Reasoning): 새로운 문제를 해결하기 위해 과거의 성공적인 사례(Case)를 검색, 재사용, 수정하여 적용하고, 성공한 상호작용을 에피소드 메모리에 저장하는 문제 해결 패러다임.
- Contextual Bandit: 에이전트가 관측된 문맥(Query)에 기반하여 최적의 행동을 선택하고, 이에 따른 보상을 통해 정책을 업데이트하는 온라인 학습 프레임워크.
- No-Regret Learning: 시간이 지남에 따라 에이전트의 평균 성능이 항상 최적의 솔루션을 선택하는 오라클의 성능에 수렴하도록 보장하는 학습 성질.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
현재의 LLM 라이프사이클은 대규모 pretraining과 finetuning이라는 두 단계에 고정되어 있어, 일단 배포되면 학습이 완전히 중단되는 한계가 있습니다. 이는 실제 환경에서 상호작용하며 경험을 통해 지속적으로 진화하는 자연 지능과 대조되며, 배포된 환경의 변화에 유연하게 대응하지 못하는 critical bottleneck으로 작용합니다. 특히, 많은 LLM이 파라미터 업데이트가 불가능한 black-box API 형태로 서비스되거나, 대규모 모델에 대한 backpropagation 비용이 매우 높다는 현실적인 제약이 존재합니다. 따라서 본 연구는 모델 파라미터 수정 없이, 프롬프트, 메모리, 의사결정 기법 등 에이전트 주변의 구성요소를 최적화하여 배포 중에도 지속적으로 향상할 수 있는 새로운 DTL 패러다임을 제안합니다 [Figure 1].

Figure 1 — LLM 라이프사이클과 DTL의 위치
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 경험 기반 지속적 적응을 구현하기 위한 일반적인 프레임워크인 CASCADE를 제안합니다. CASCADE는 CBR을 기반으로 에피소드 메모리를 명시적으로 구축하며, 케이스 검색 과정을 contextual bandit 문제로 공식화하여 정교한 탐색(Exploration)과 활용(Exploitation)의 균형을 맞춥니다. 특히, Neural-LinLogUCB 알고리즘을 도입하여 딥러닝 인코더와 선형 헤드를 분리함으로써, 고정된 기초 모델 위에서도 배포 중 경험을 통해 검색 정책을 최적화하고 수렴 가능한 no-regret 성능을 보장합니다 [Figure 2].
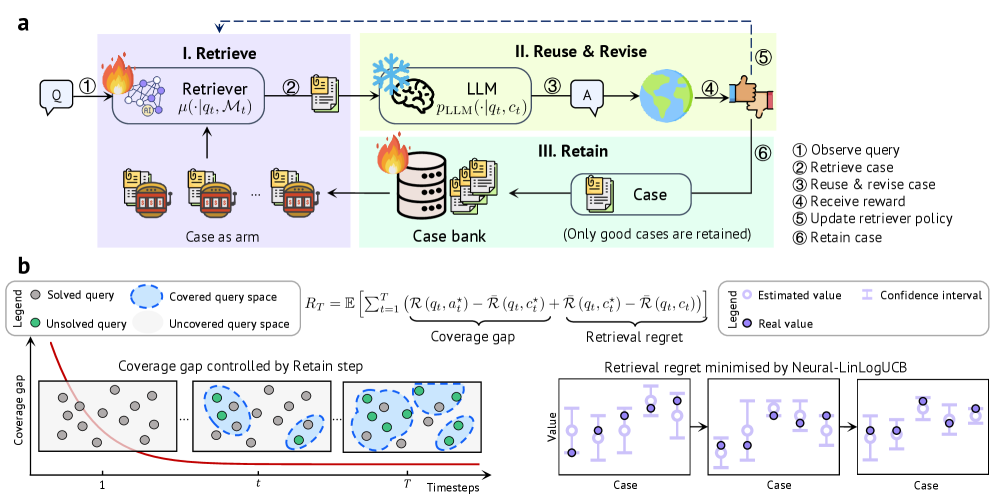
Figure 2 — CASCADE 아키텍처 개요
16개의 다양한 작업(의료 진단, 법률 분석, 코드 생성, 웹 검색 등)에 대한 실험 결과, CASCADE는 zero-shot 프롬프팅 대비 매크로 평균 성공률을 20.9% 향상했습니다. 또한, 파라미터 기반의 gradient-based 학습(예: REINFORCE+LoRA)과 달리 단일 GPU 환경에서도 우수한 성능을 달성하며, 리소스 효율성 측면에서 압도적인 비교 우위를 점합니다. [Figure 3].
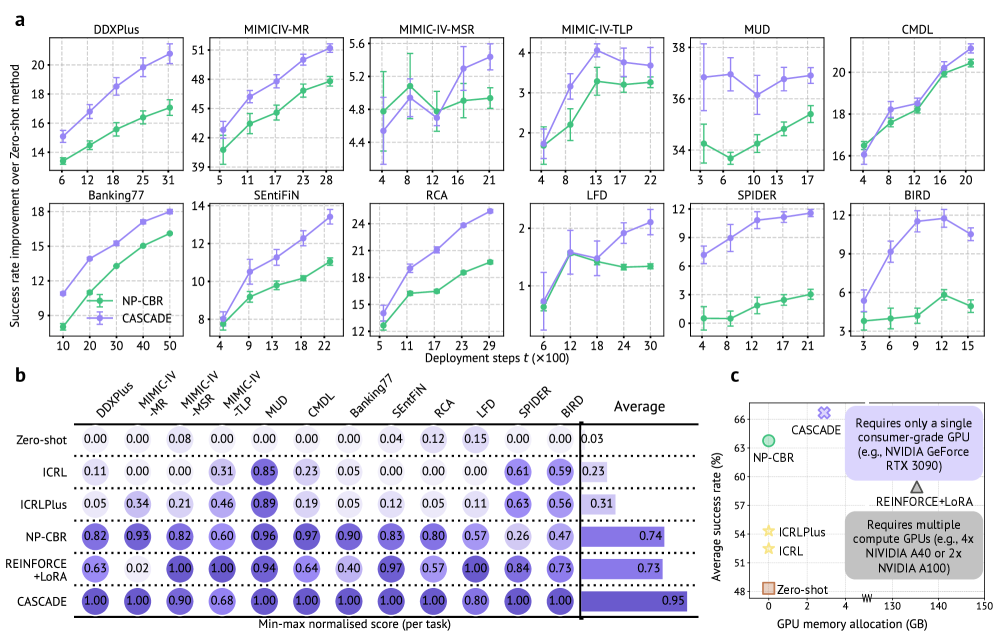
Figure 3 — 단일 턴 작업에 대한 핵심 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 배포를 학습의 끝이 아닌, AI 시스템이 지속적으로 향상되는 과정으로 재정의하는 DTL의 이론적/실천적 토대를 마련했습니다. CASCADE는 모델 파라미터 업데이트 없이도 메모리 기반의 검색 정책 최적화를 통해 강력한 적응 능력을 보여주었으며, 이는 LLM 에이전트가 복잡하고 동적인 환경에서 안정적으로 성능을 개선할 수 있음을 입증합니다. 이 연구는 AI 시스템이 정적인 artifact에서 Continual learning이 가능한 adaptive agent로 진화하는 데 핵심적인 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] QueryBandits for Hallucination Mitigation: Exploiting Semantic Features for No-Regret Rewriting
- [논문리뷰] PluraMath: Extending Mathematical Reasoning Evaluation Beyond High-Resource Languages
- [논문리뷰] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling
- [논문리뷰] PraMem: Practice-derived Experiential Memory for Long-horizon Behavior Prediction
Review 의 다른글
- 이전글 [논문리뷰] Beyond Retrieval: A Multitask Benchmark and Model for Code Search
- 현재글 : [논문리뷰] CASCADE: Case-Based Continual Adaptation for Large Language Models During Deployment
- 다음글 [논문리뷰] CPCANet: Deep Unfolding Common Principal Component Analysis for Domain Generalization
댓글