[논문리뷰] Measuring Maximum Activations in Open Large Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Luxuan Chen, Han Tian, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Maximum Activation Magnitude (M): 논문에서 제안하는 핵심 지표로, 모든 레이어와 구성 요소(embedding, hidden states, attention, MLP/MoE 등)를 통틀어 관찰되는 절대값 기준 최댓값을 의미합니다.
- Sun Criterion: 특정 토큰의 활성화 값($|x_i| > 100$)이 로컬 중앙값 대비 일정 배수($\ge 1000\times$) 이상일 때 이를 'Massive Activation'으로 분류하는 기존 연구의 이진 판정 기준입니다.
- Residual Stream: Transformer 모델의 각 레이어를 연결하는 통로로, 본 논문에서 대부분의 Global Maximum 활성화 값이 포착되는 주요 경로로 지목됩니다.
- SQNR (Signal-to-Quantization-Noise Ratio): 신호 대 양자화 잡음비로, 저비트 양자화 시 발생하는 정보 손실을 측정하는 성능 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 오픈 LLM 생태계에서 Activation의 동적 범위(Dynamic Range)가 단순히 파라미터 수에 비례한다는 기존의 통념을 재검토하고, 모델별 Maximum Activation Magnitude(MM)를 체계적으로 측정하여 배포 시의 위험을 파악하고자 합니다. [Figure 1] 기존의 연구들은 주로 소수의 모델에 한정된 이진적 'Massive Activation' 판정에 집중하였으나, 현대의 모델들은 MoE(Mixture-of-Experts), Vision-Language 모델, Instruction-tuned 버전 등 구조적 다양성이 매우 큽니다. 이러한 모델들은 양자화나 추론 시 각기 다른 수치적 한계치를 가지므로, 단순히 파라미터 규모만으로 활성화 범위를 추정하는 것은 매우 부정확합니다. 따라서 본 연구는 8개 모델 패밀리 24개 체크포인트를 대상으로 단일화된 프로토콜을 적용하여 MM이 어떻게 변화하는지 분석합니다.
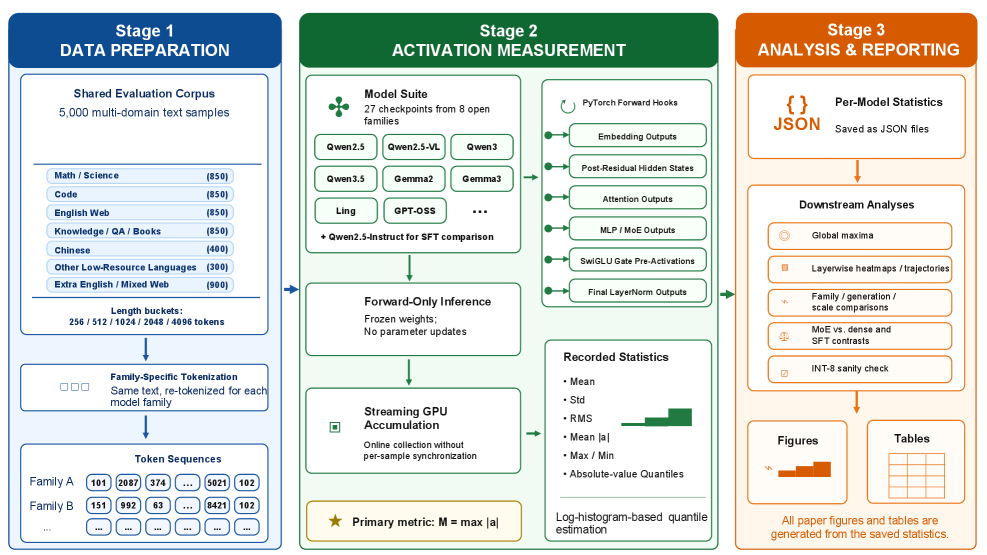
Figure 1 — 활성화 측정 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 5,000개의 멀티 도메인 코퍼스를 활용하여 토큰화부터 레이어별 활성화 값 추출까지를 동일한 파이프라인으로 수행하는 Unified Evaluation Protocol을 제안합니다. 실험 결과, Global MM은 파라미터 수가 비슷한 모델 간에도 약 4자릿수 이상 차이가 발생하며, 모델의 패밀리 및 세대(Generation)에 따라 비단조적(Non-monotonic)으로 변화함이 확인되었습니다 [Figure 6]. 주요 결과는 다음과 같습니다:
- MoE vs. Dense: MoE 아키텍처는 매칭된 규모의 Dense 모델 대비 약 14.0배에서 23.4배 낮은 피크 값을 기록하여 양자화 난이도가 상대적으로 낮음을 보였습니다 [Figure 8].
- Residual Stream: 분석 대상 24개 체크포인트 중 22개에서 Global Maximum이 Residual Stream에서 발생하여, 이 경로가 활성화 피크의 핵심 경로임을 입증했습니다.
- Instruction Tuning(SFT): SFT는 주로 후반부 레이어의 피크를 압축하는 경향이 있음을 확인했습니다 [Figure 10].
- Quantization Correlation: 저자들은 MM이 클수록 INT-8 양자화 시 SQNR이 실질적으로 하락하여 재구성 오차가 증가함을 확인했습니다 [Figure 12].
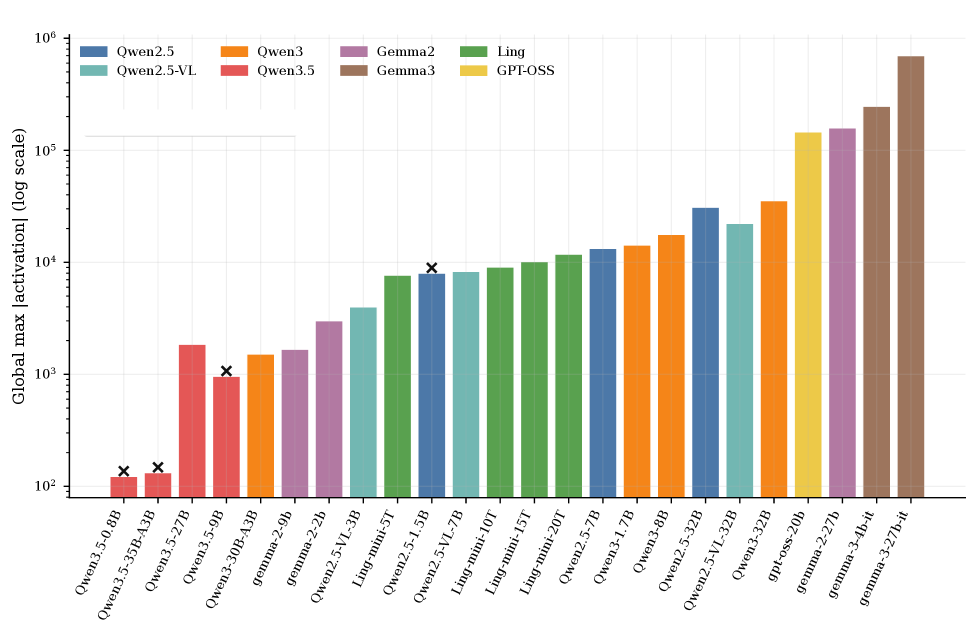
Figure 6 — 체크포인트별 활성화 피크 분포
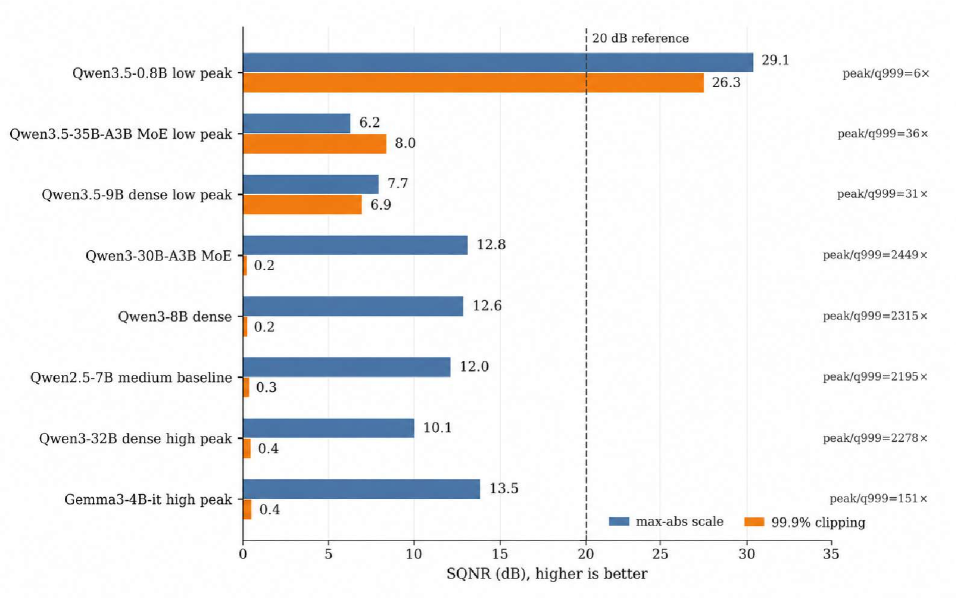
Figure 12 — INT-8 양자화 성능 검증
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Maximum Activation Magnitude가 모델의 패밀리, 아키텍처, 훈련 단계 등에 의해 결정되는 연속적인 모델 속성임을 밝혀냈습니다. 이는 모델의 파라미터 수만으로 추론 시스템의 동적 범위를 결정해서는 안 되며, 모든 오픈 모델 배포 시 MM을 모델 카드에 포함하여 보고해야 함을 시사합니다. 또한, 본 연구가 제시한 방법론과 지표는 최신 Low-bit Quantization 기술의 설계와 안정적인 LLM 배포 전략을 수립하는 데 있어 필수적인 기반 지식이 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
- [논문리뷰] Direct Multi-Token Decoding
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] PluraMath: Extending Mathematical Reasoning Evaluation Beyond High-Resource Languages
- [논문리뷰] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling
Review 의 다른글
- 이전글 [논문리뷰] LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
- 현재글 : [논문리뷰] Measuring Maximum Activations in Open Large Language Models
- 다음글 [논문리뷰] MementoGUI: Learning Agentic Multimodal Memory Control for Long-Horizon GUI Agents
댓글