[논문리뷰] LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yukang Chen, Luozhou Wang, Wei Huang, Shuai Yang, Bohan Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Balanced SP (Sequence Parallelism): 비디오 생성 모델의 학습 시, Clean History와 Noisy Target 청크를 동일한 시간적 범위로 각 GPU에 할당하여 연산 균형을 맞추고 메모리 효율을 극대화하는 병렬화 기술입니다.
- NVFP4 (NVIDIA FP4): NVIDIA Blackwell 아키텍처에서 지원하는 4비트 부동소수점 포맷으로, 모델 파라미터 및 KV Cache를 양자화하여 메모리 사용량을 줄이고 연산 속도를 가속화합니다.
- W4A4 Inference: Weight와 Activation을 모두 4비트로 양자화하여 실행하는 추론 방식으로, NVFP4 환경에서 End-to-End 처리량(Throughput)을 극대화합니다.
- Asynchronous Streaming Decoding: 모델의 Denoising 단계와 VAE Decoding 단계를 비동기적으로 수행하여, VAE 디코딩 지연 시간을 Denoising 연산에 숨김으로써 실시간 생성 성능을 확보하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 긴 비디오 생성 시 발생하는 메모리 병목 현상과 낮은 연산 효율 문제를 해결하기 위해 시스템과 알고리즘이 통합된 인프라 LongLive-2.0을 제안한다. 기존의 장편 비디오 생성 연구들은 주로 알고리즘 설계에 집중하여, 학습과 추론 과정에서의 인프라 최적화가 부족하며 이로 인해 실시간 배포가 어렵다는 한계가 있다. 또한, 기존의 Self-Forcing 계열 방법론들은 복잡한 다단계 학습(ODE 초기화, DMD 등)을 필요로 하여 파이프라인이 비효율적이다. 이를 극복하기 위해 학습부터 추론까지 NVFP4를 기반으로 한 일관된 최적화 인프라가 필수적이다 [Figure 1].
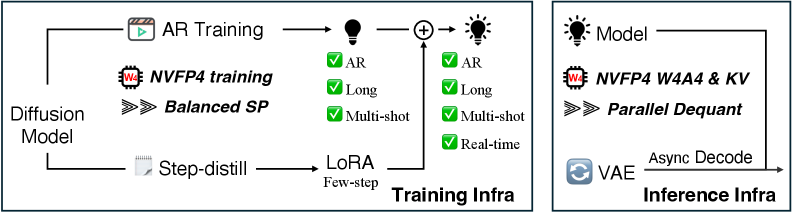
Figure 1 — LongLive-2.0 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Balanced SP와 NVFP4를 결합하여 비디오 생성의 학습 및 추론 효율을 획기적으로 개선하였다. 학습 단계에서 Balanced SP는 Clean 및 Noisy latent 스트림을 시간적 청크 단위로 정렬하여 각 GPU의 연산 부하를 균일하게 분배하고, NVFP4를 통해 GEMM 연산의 메모리 비용을 감소시켰다 [Figure 2]. 또한, 기존의 복잡한 다단계 학습 대신 장편 비디오 데이터를 활용한 직접적인 Fine-tuning 파이프라인을 도입하여 효율성을 높였다 [Figure 3]. 실험 결과, LongLive-2.0은 기존 BF16+SP 대비 학습에서 최대 2.1배의 속도 향상을 달성하였다. 추론 측면에서는 W4A4 NVFP4 양자화, KV Cache 양자화 및 비동기 VAE 디코딩을 통해 5B 모델 기준 45.7 FPS의 실시간 생성 성능을 구현하였으며, 이는 기존 방법론 대비 약 1.84배 개선된 수치이다 [Table 3].
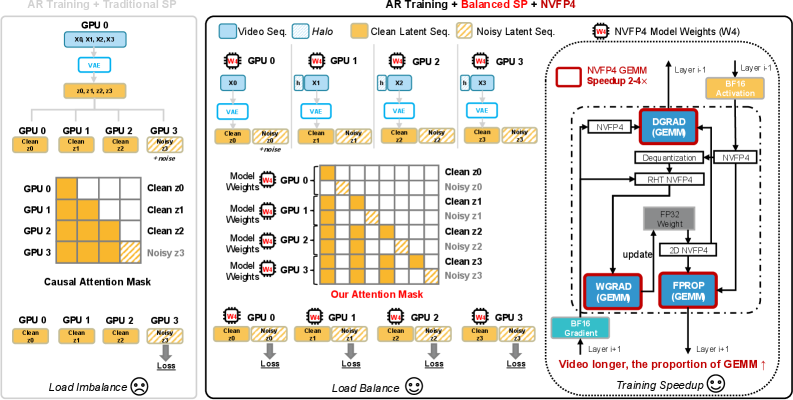
Figure 2 — Balanced SP 및 NVFP4 학습 인프라
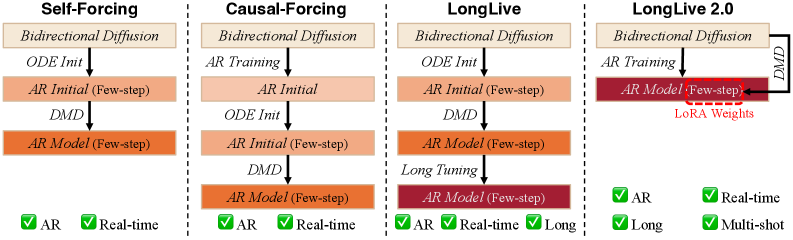
Figure 3 — AR 비디오 생성의 단순화된 학습 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 NVFP4 기반의 통합 인프라를 통해 장편 비디오 생성의 학습 및 추론 병목을 효율적으로 해결하였다. LongLive-2.0은 복잡한 학습 과정을 단순화하면서도 성능은 유지하는 청정한 파이프라인을 제시하였으며, 다양한 실시간 상호작용 애플리케이션에 적용 가능한 범용성을 입증하였다. 이 연구는 고성능 하드웨어 가속기와 알고리즘 최적화의 긴밀한 결합이 대규모 생성 모델의 실제 배포를 어떻게 가속할 수 있는지 보여주는 중요한 사례이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
- [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
- [논문리뷰] NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
- [논문리뷰] LongLive-RAG: A General Retrieval-Augmented Framework for Long Video Generation
- [논문리뷰] LVSA: Training-Free Sparse Attention for Long Video Diffusion
Review 의 다른글
- 이전글 [논문리뷰] LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs
- 현재글 : [논문리뷰] LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
- 다음글 [논문리뷰] Measuring Maximum Activations in Open Large Language Models
댓글