[논문리뷰] Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Min Zhao, Hongzhou Zhu, Kaiwen Zheng, Zihan Zhou, Bokai Yan, Xinyuan Li, Xiao Yang, Chongxuan Li, Jun Zhu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Autoregressive (AR) Diffusion Distillation: Bidirectional diffusion 모델의 높은 품질과 AR 모델의 낮은 지연 시간(low-latency) 및 상호작용성을 결합하기 위해, 큰 모델을 작은 step 수의 AR 학생 모델로 증류(distillation)하는 기법입니다.
- Causal Consistency Distillation (Causal CD): Causal ODE distillation을 대체하는 효율적인 초기화 기법으로, 인접한 타임스텝 간의 로컬 ODE step을 활용하여 AR-conditional flow map을 학습합니다.
- Asymmetric Diffusion Model Distillation (DMD): 초기화된 학생 모델을 실제 데이터로 세밀하게 조정(fine-tuning)하는 단계로, 학생은 AR 방식을 유지하며 교사와 평가 모델(critic)은 Bidirectional 방식을 사용하는 비대칭적 구조를 가집니다.
- Exposure Bias: 학습 시의 Teacher Forcing 환경과 추론 시의 Self-rollout 환경 간의 불일치로 인해, 생성된 프레임이 누적될수록 품질이 급격히 저하되는 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실시간 인터랙티브 비디오 생성을 위해 Frame-wise 수준의 초저지연 1–2 step 생성 체계로 확장이 필요함을 정의합니다 [Figure 1]. 기존의 연구들은 주로 Chunk-wise 4-step 방식을 채택하여 실시간성 확보에 한계가 있었으며, 적절한 Few-step AR 학생 모델 초기화가 병목 현상으로 작용합니다. 기존 초기화 방식들은 Bidirectional 교사 모델 사용으로 인한 구조적 불일치, 다단계 AR 모델의 비효율성, 혹은 과도한 학습 비용 등의 문제를 안고 있습니다 [Figure 2]. 따라서 본 연구는 AR 방식이면서 Few-step 생성이 가능하고, 동시에 확장성(Scalability)을 갖춘 초기화 파이프라인의 필요성을 강조합니다.
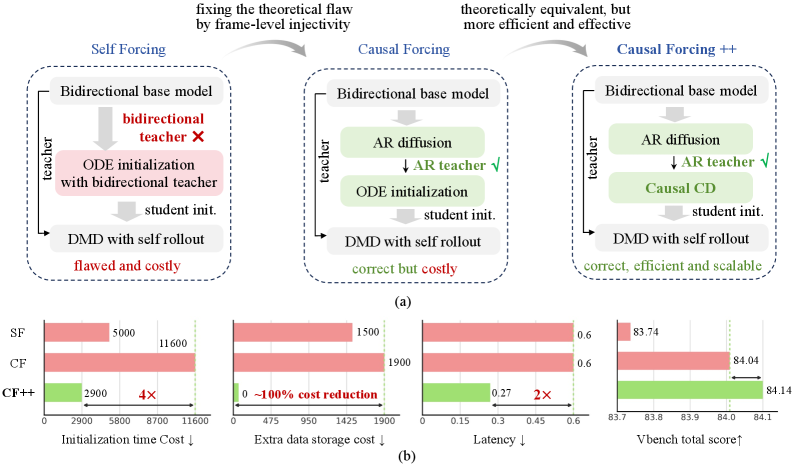
Figure 1 — 제안 모델의 전체 아키텍처

Figure 2 — 기존 초기화 방식들의 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Causal ODE distillation의 학습 목표를 공유하면서도 효율성을 극대화한 Causal Forcing++ 파이프라인을 제안합니다 [Figure 1]. 제안하는 Causal CD는 오프라인에서 전체 PF-ODE 궤적을 미리 생성할 필요 없이, 학습 중 실시간으로 인접한 두 타임스텝 간의 단일 ODE step을 사용하여 지도(supervision)를 획득합니다 [Figure 3]. 이 방식은 더 작은 per-step 최적화 오차를 제공하여 학습이 더 쉽고 성능이 우수합니다. Wan2.1-1.3B 모델을 기반으로 실험한 결과, 제안 기법은 기존 SOTA 방식 대비 Frame-wise 2-step 설정에서 VBench Total 및 Quality 점수를 개선하였습니다 [Table 2]. 특히 이전 방식 대비 첫 프레임 지연 시간을 50% 단축하였으며, Stage 2 학습 비용을 약 4배 절감하는 성과를 거두었습니다 [Figure 3]. 아울러, 제안된 기법은 액션 기반의 월드 모델 생성(Action-conditioned world model)에도 성공적으로 적용되어 범용성을 입증했습니다 [Figure 4].

Figure 3 — Causal CD와 Causal ODE 효율성 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 기존 AR diffusion distillation의 비효율적인 초기화 단계를 Causal CD로 혁신하여 실시간 인터랙티브 비디오 생성을 앞당겼습니다. **Causal Forcing++**는 학습 효율성과 생성 품질이라는 두 마리 토끼를 모두 잡으며, 특히 초저지연 프레임 단위 생성 regime에서 강력한 성능을 발휘합니다. 이 연구는 비디오 모델이 단순히 콘텐츠를 생성하는 수준을 넘어, 사용자와 실시간으로 상호작용하는 월드 모델로 진화하는 데 중요한 기술적 토대를 제공합니다. 향후 실시간 인터랙티브 환경에서의 더 정교한 제어 및 생성 속도 개선에 중대한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
- [논문리뷰] Infinite Worlds with Versatile Interactions
- [논문리뷰] Imagined Rollouts are Kinematic, Not Dynamic: A Diagnosis of Long-Horizon World-Model Failure
- [논문리뷰] PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation
- [논문리뷰] Hallucination in World Models is Predictable and Preventable
Review 의 다른글
- 이전글 [논문리뷰] Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
- 현재글 : [논문리뷰] Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
- 다음글 [논문리뷰] CurveBench: A Benchmark for Exact Topological Reasoning over Nested Jordan Curves
댓글