[논문리뷰] Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
메타데이터
저자: Che Liu, Lichao Ma, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Xuerui Yang, Fei Tian
1. Key Terms & Definitions (핵심 용어 및 정의)
- Omni-modal LLM: Text, Image, Video, Audio를 단일 모델 인터페이스 내에서 통합적으로 이해하고 추론할 수 있는 거대 언어 모델입니다.
- Visual Leakage: 오디오-비주얼-텍스트 벤치마크 평가 시, 오디오 정보 없이 이미지나 비디오 입력만으로도 정답 추론이 가능한 현상을 지칭합니다.
- OmniClean: 본 논문에서 visual-only probing을 통해 visual shortcut이 가능한 쿼리를 제거하여 구축한 비주얼 편향이 제거된(visually debiased) 평가 데이터셋입니다.
- RLVR (Reinforcement Learning with Verifiable Rewards): 모델의 추론 과정에 대해 검증 가능한 보상을 부여하여 논리적 추론 및 모달리티 간 통합 능력을 향상시키는 학습 방법론입니다.
- Self-Distillation SFT: 더 강력한 모델로부터 지식을 전이받는 대신, 모델 자신이 생성한 reasoning trace를 필터링하여 다시 모델 학습에 사용하는 자기 증류 방식의 supervised fine-tuning입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Omni-modal LLM들이 기록하는 벤치마크 성능 향상이 진정한 모달리티 통합(integration)보다는 visual shortcut을 활용한 결과일 수 있다는 문제를 제기합니다. 많은 오디오-비주얼-텍스트 태스크에서 비주얼 정보만으로도 정답을 유추할 수 있어, 모델의 실제 omni-modal 이해 능력이 과대평가되고 있습니다. 기존 연구들은 비주얼 편향이 포함된 상태로 성능을 측정하므로, 저자들은 이를 해결하기 위해 visual leakage를 엄격히 통제하는 새로운 평가 뷰를 구축하고자 합니다. 이 문제를 해결하지 못하면 진정한 의미의 멀티모달 추론 능력을 측정하기 어렵기 때문에 체계적인 auditing과 필터링 프레임워크가 필요합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 OmniBoost라는 3단계 post-training 기법을 제안하며, 이를 OmniClean 평가 환경에서 검증합니다. 제안된 OmniBoost는 (1) Mixed Bi-modal SFT, (2) Mixed-Modality RLVR, (3) Self-Distillation SFT 단계로 구성됩니다. 실험 결과, 단순한 bi-modal SFT만으로는 제한적인 성능 향상만을 보였으며, RLVR 단계가 처음으로 광범위한 성능 개선을 이끌어냈습니다. OmniClean 기반 평가에서 제안 기법을 적용한 3B 모델은 기존의 더 큰 규모의 오픈 소스 모델과 대등한 성능을 기록하였으며, 특정 조건에서는 Qwen3-Omni-30B-A3B-Instruct를 소폭 능가하는 결과를 보였습니다. 본 연구의 정량적 지표인 macro average 기준, RLVR 단계에서 가장 두드러진 성능 향상을 나타내었습니다 [Table 2]. 또한, self-distillation filtering passes(F1-F3)를 거치면서 모델의 추론 패턴이 안정화되고 성능 프로파일이 최적화됨을 확인하였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 오디오-비주얼-언어 벤치마크에서 visual leakage가 성능 평가에 미치는 영향을 규명하고, 이를 완화한 OmniClean을 통해 모델의 omni-modal 능력을 더 정확하게 측정할 수 있음을 입증했습니다. 제안된 OmniBoost staged post-training 레시피는 대규모 모델이 아니더라도 효율적인 데이터 구성과 정교한 학습 단계를 통해 성능을 극대화할 수 있음을 시사합니다. 이러한 접근 방식은 향후 멀티모달 평가의 투명성을 높이고, 더 작은 파라미터 크기에서도 강력한 omni-modal 통합 능력을 구현하려는 학계 및 산업계 연구에 중요한 방법론적 기준을 제공합니다.
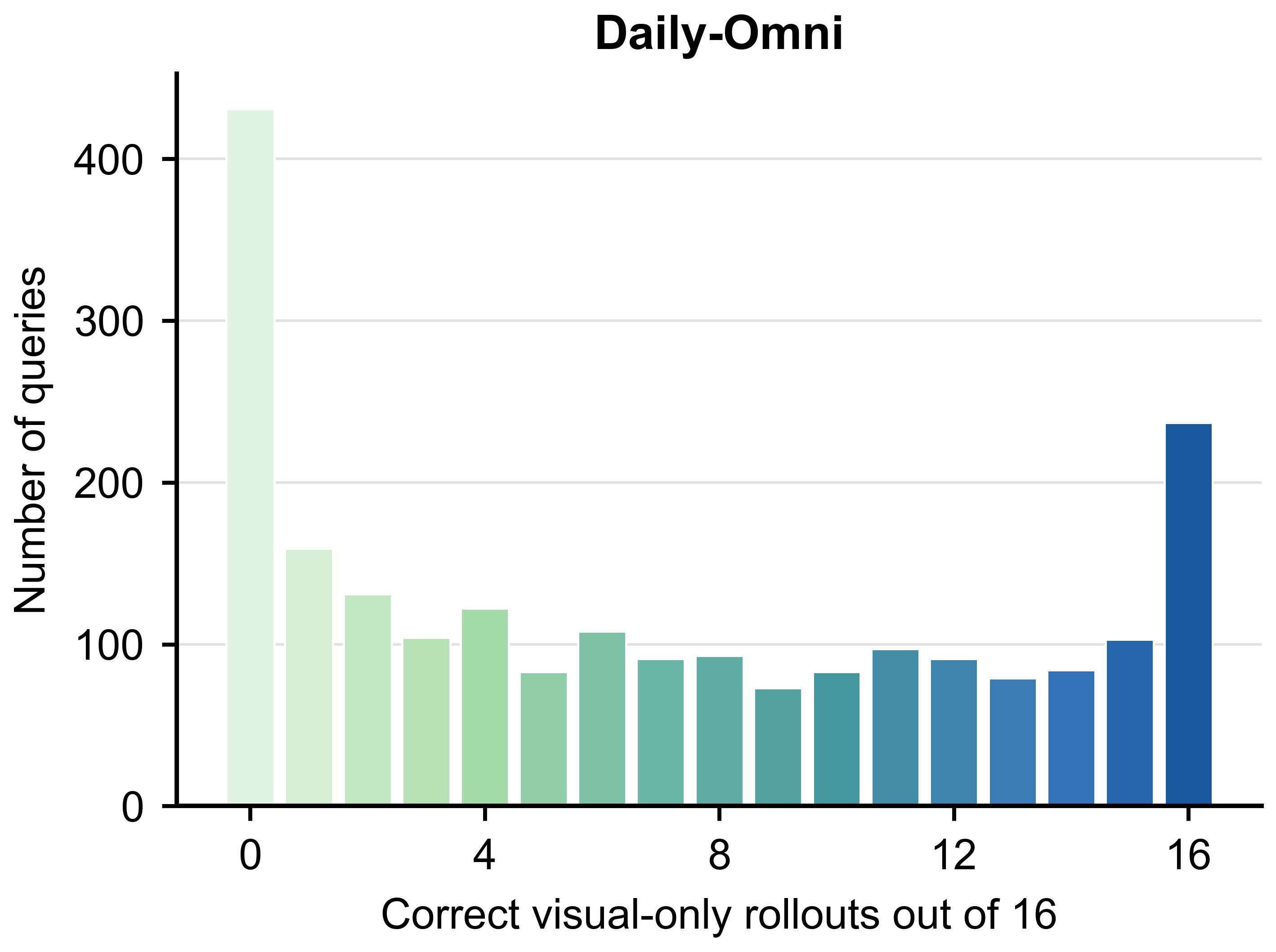
Figure 1 — Daily-Omni 벤치마크의 비주얼 솔빙 히스토그램
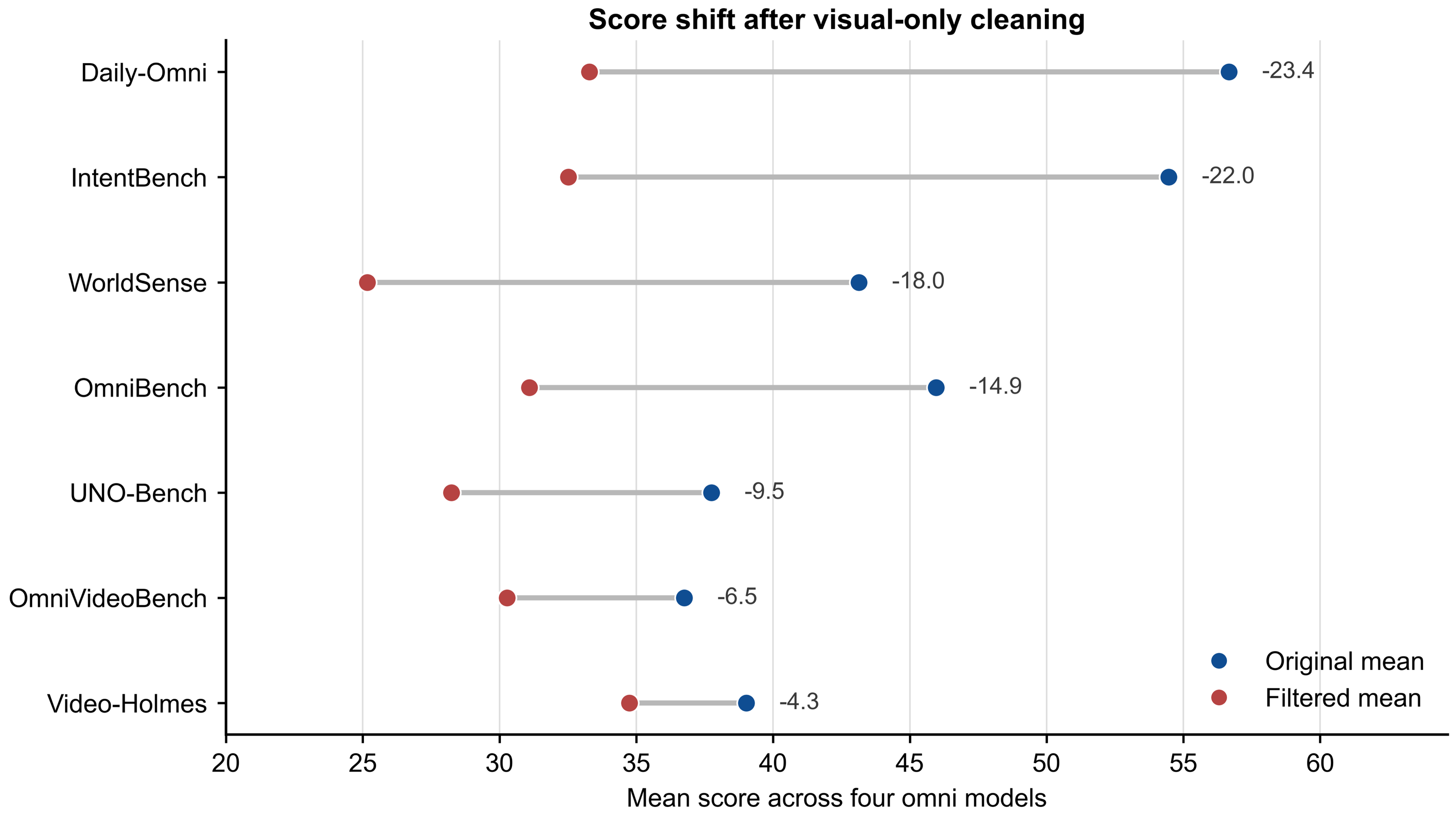
Figure 2 — 필터링 전후 성능 분포 비교

Figure 5 — 합성 쿼리 생성 파이프라인
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
- [논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
- [논문리뷰] GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
- [논문리뷰] HINT-SD: Targeted Hindsight Self-Distillation for Long-Horizon Agents
- [논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Review 의 다른글
- 이전글 [논문리뷰] Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems
- 현재글 : [논문리뷰] Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
- 다음글 [논문리뷰] Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
댓글