[논문리뷰] Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning
링크: 논문 PDF로 바로 열기
The browsing was successful. I have the content of the paper.
Now I will proceed with the summarization, following all the constraints.
Part 1: Markdown Summary
Authors: Zihao Han, Tiangang Zhang, Huaibin Wang, Yilun Sun, et al.
1. Key Terms & Definitions
- On-Policy Self-Distillation (OPSD): 단일 LLM이 teacher와 student 역할을 모두 수행하며, student는 자체 rollouts으로부터 학습하고 teacher는 privileged reference solution에 기반하여 token-level supervision을 제공하는 방법론입니다.
- Teacher-side Exposure Mismatch: Teacher가 student의 현재 능력치를 훨씬 초과하는 privileged reasoning에 conditioning할 때, resulting token targets가 student가 absorb하기에는 너무 difficult해져 학습 효율이 저하되는 문제점입니다.
- Exposure Fraction ($\alpha$): Teacher가 reference reasoning의 어느 정도를 볼 수 있는지 control하는 연속적인 변수로, $\alpha=1$은 full exposure를 의미하고 $\alpha=0$은 final answer만 보는 것을 의미합니다.
- Beta Exposure Controller: Compact training-state statistics에 conditioning되어 exposure fraction $\alpha$를 결정하는 lightweight Beta-policy controller로, training-time에 adaptive exposure를 학습합니다.
- Discounted Learning-Progress Reward: Exposure decision의 immediate loss change가 아닌 student의 future improvement에 미치는 영향으로 각 held decision의 score를 매기는 reward function으로, on-policy distillation으로 인해 발생하는 delayed credit assignment 문제를 해결합니다.
2. Motivation & Problem Statement
본 논문은 LLM reasoning을 위한 On-Policy Self-Distillation (OPSD)에서 teacher-side exposure mismatch라는 간과된 bottleneck을 식별하고 해결하고자 합니다. 기존 OPSD 및 후속 연구들은 student-side distribution mismatch를 해결하는 데 초점을 맞추었으나, teacher가 privileged reasoning을 얼마나 보아야 하는지에 대한 질문은 다루지 않았으며, 모든 상황에서 teacher가 full reference reasoning을 보는 것을 기본값으로 설정했습니다. 저자들은 이러한 default 설정이 문제의 일부라고 주장하며, teacher가 student의 현재 competence를 훨씬 초과하는 reasoning에 conditioning할 때, student가 absorb하기에는 너무 difficult한 token targets가 생성된다는 teacher-side exposure mismatch를 지적합니다 [Figure 1]. Controlled fixed-exposure sweep을 통해 full exposure가 항상 최적의 선택이 아니며, teacher-student mismatch가 teacher가 더 많은 privileged reasoning을 볼수록 단조롭게 증가함을 확인했습니다 [Figure 2]. 이는 teacher exposure를 고정된 hyperparameter가 아닌 learnable training-time control variable로 다루어야 할 필요성을 strong하게 시사합니다.
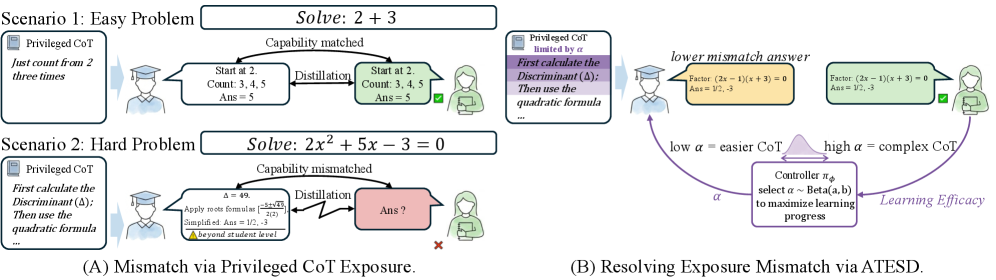
Figure 1 — ATESD 개요 및 teacher-side exposure mismatch
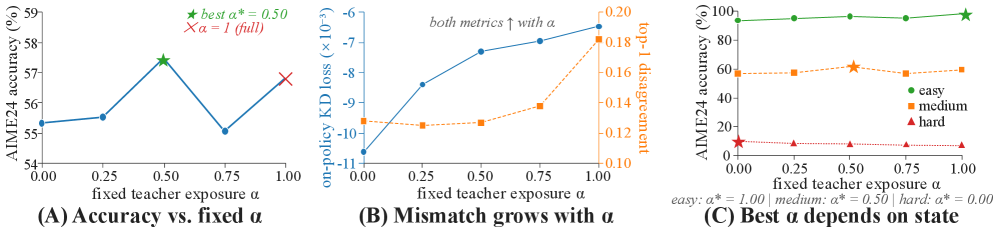
Figure 2 — Teacher exposure의 empirical 분석
3. Method & Key Results
저자들은 teacher-side exposure mismatch를 해결하기 위해 Adaptive Teacher Exposure for Self-Distillation (ATESD)를 제안합니다. ATESD는 OPSD의 full-reference teacher를 exposure-modulated teacher로 대체하며, training-state에 conditioning되는 lightweight Beta-policy controller를 사용하여 hold window당 하나의 global exposure ($\alpha_t$)를 샘플링합니다 [Figure 3]. 이 controller는 immediate loss change가 아닌 student의 future learning progress에 대한 discounted learning-progress reward를 통해 REINFORCE로 train됩니다. 이를 통해 on-policy distillation에서 발생하는 delayed credit assignment 문제를 address합니다. Exposure $\alpha_t$는 연속적인 변수로, privileged reasoning prefix의 fraction을 control하며, final boxed answer는 항상 보존됩니다.
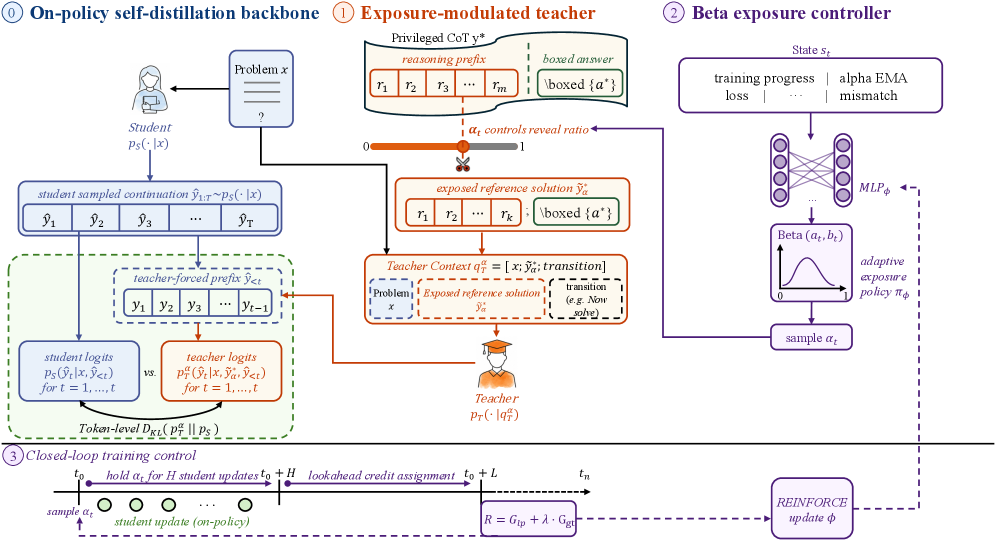
Figure 3 — ATESD 방법론의 전체 아키텍처
ATESD는 Qwen3-{1.7B, 4B, 8B} 모델을 사용하여 AIME 2024, AIME 2025, HMMT 2025 벤치마크에서 경쟁력 있는 self-distillation 및 RL baselines 대비 consistently 우수한 성능을 달성했습니다 [Table 1]. 특히 OPSD 대비 Qwen3-1.7B에서 +0.95, Qwen3-4B에서 +2.05, Qwen3-8B에서 +2.33 Average@12 point의 성능 향상을 보였습니다. 가장 강력한 4B 모델은 65.65 Average@12를 달성하여 OPSD보다 2.05 point, GRPO보다 2.95 point 높은 결과를 보였습니다. Ablation study 결과, exposure control이 positive-trajectory mismatch를 효과적으로 줄이며 [Figure 4A], delayed credit assignment가 exposure 학습에 필수적이고 [Table 2A], feedback-driven exposure selection이 fixed 또는 uncontrolled options보다 우수함이 입증되었습니다 [Table 2B]. 학습된 Beta policy는 training이 진행됨에 따라 no-reference와 full-exposure extremes에서 벗어나 usable middle regime에 concentration되는 경향을 보였습니다 [Figure 4B].
4. Conclusion & Impact
본 연구는 on-policy self-distillation에서 teacher-side exposure mismatch의 critical한 역할을 강조하며, full teacher exposure가 suboptimal하며 teacher-student distribution mismatch가 exposure level에 따라 단조롭게 증가함을 empirically 입증했습니다. 저자들은 이러한 문제를 해결하기 위해 training-state에 conditioning되는 Beta controller와 discounted learning-progress reward를 활용하는 ATESD를 제안하여, teacher exposure를 learnable control variable로 전환했습니다. ATESD는 다양한 LLM 규모와 수학적 추론 벤치마크에서 기존 OPSD baseline 대비 consistently superior performance를 보여주며, adaptive teacher exposure가 reasoning self-distillation을 위한 효과적인 새로운 axis임을 확립했습니다. 이 연구는 LLM reasoning 능력 향상에 기여할 뿐만 아니라, 지식 증류 과정에서 teacher의 정보 노출 수준을 동적으로 조절하는 새로운 패러다임을 제시하여 학계 및 산업계에서 LLM post-training 방법론의 효율성과 robustnes를 크게 향상시킬 potential을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
- [논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
- [논문리뷰] GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
- [논문리뷰] HINT-SD: Targeted Hindsight Self-Distillation for Long-Horizon Agents
- [논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Review 의 다른글
- 이전글 [논문리뷰] Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
- 현재글 : [논문리뷰] Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning
- 다음글 [논문리뷰] BEAM: Binary Expert Activation Masking for Dynamic Routing in MoE
댓글