[논문리뷰] BEAM: Binary Expert Activation Masking for Dynamic Routing in MoE
링크: 논문 PDF로 바로 열기
메타데이터
저자: Juntong Wu, Jialiang Cheng, Qishen Yin, Yue Dai, Yuliang Yan, Fuyu Lv, Ou Dan, Li Yuan
1. Key Terms & Definitions (핵심 용어 및 정의)
- BEAM (Binary Expert Activation Masking): MoE 모델에서 토큰별로 필요 없는 Expert를 동적으로 비활성화하기 위해 Learnable Binary Mask를 도입한 라우팅 프레임워크입니다.
- Top-K Routing: MoE에서 매 토큰마다 로짓(Logit)이 가장 높은 K개의 Expert만을 선택하여 연산하는 전통적인 기법입니다.
- Straight-Through Estimator (STE): 이진 마스크(Binary Mask) 생성 과정의 비미분 가능(Non-differentiable)한 Thresholding 문제를 해결하기 위해 역전파(Backpropagation) 시 경사도를 근사하는 기법입니다.
- vLLM Integration: BEAM의 추론 속도 향상을 위해 설계된 Custom CUDA Kernel을 통해 vLLM 프레임워크 내에서 원활하게 통합되어 실시간 가속을 지원하는 배포 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 표준 MoE 모델의 고정된 Top-K 라우팅 방식이 초래하는 연산 중복 문제를 해결하기 위해 BEAM을 제안한다. 기존의 Top-K 메커니즘은 토큰별 복잡도를 고려하지 않고 모든 토큰에 동일한 수의 Expert를 할당하여 불필요한 연산을 발생시킨다. 이를 개선하려는 기존의 연구들은 모델 재학습(Retraining) 비용이 크거나, 학습과 추론 간의 불일치(Train-Inference Mismatch)로 인해 고도의 Sparsity 조건에서 성능이 급격히 저하되는 한계가 있다. 저자들은 이러한 한계를 극복하고 모델의 정교한 Sparsity 제어를 위해 End-to-End 학습 가능한 동적 라우팅 기법이 필요하다고 강조한다 [Figure 2].

Figure 2 — Top-K vs BEAM 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Primary Router와 독립적으로 동작하는 경량화된 Mask Router를 도입하여 Top-K 후보군 중 중복된 Expert를 선택적으로 제거하는 BEAM을 제안한다 [Figure 3]. BEAM은 Sigmoid 활성화를 통해 생성된 로짓에 0.5의 임계값을 적용하여 이진 마스크를 생성하며, STE를 사용하여 End-to-End 학습을 수행한다. 특히 Auxiliary Sparsity Regularization Loss를 통해 학습 과정에서 능동적으로 Expert를 최소화한다. 실험 결과, BEAM은 다양한 MoE 모델(Qwen1.5-MoE-A2.7B, DeepSeekV2-Lite, Qwen3-30B-A3B)에서 원본 모델 성능의 98% 이상을 유지하면서도 MoE 레이어의 FLOPs를 최대 85%까지 감소시키는 성과를 보였다 [Figure 1]. 또한, vLLM 통합을 통해 TPOT(Time per Output Token) 기준 최대 2.5배의 가속과 1.4배 높은 처리량(Throughput)을 달성하였다 [Figure 4].
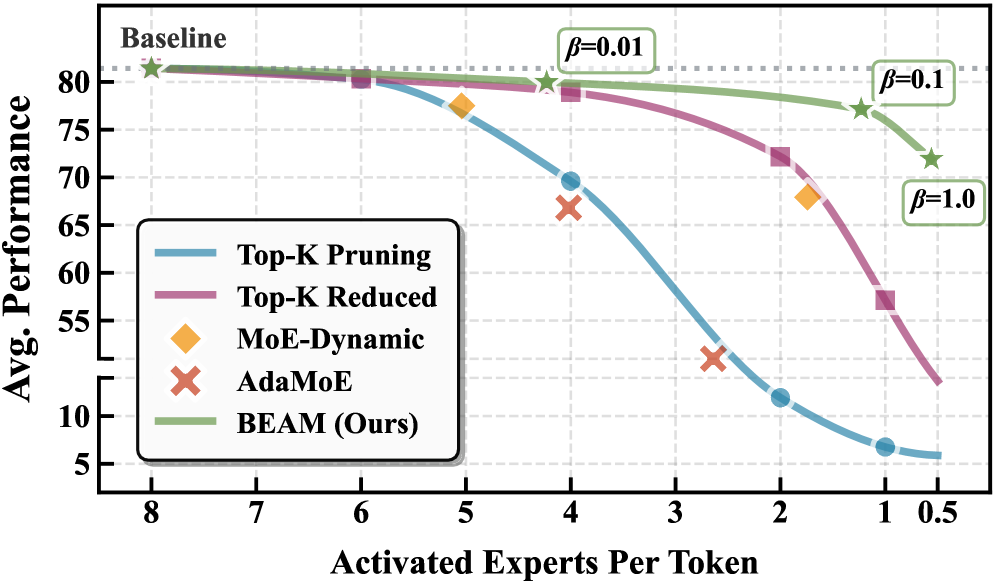
Figure 1 — 모델 성능-희소성 트레이드오프
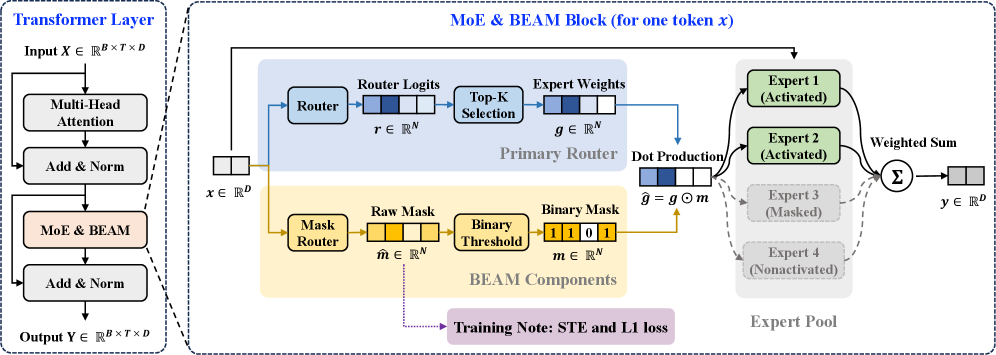
Figure 3 — BEAM 아키텍처 다이어그램
4. Conclusion & Impact (결론 및 시사점)
본 논문은 라우팅과 Sparsity 제어를 분리하는 혁신적인 BEAM 프레임워크를 통해 효율적이고 실용적인 MoE 추론을 가능하게 했다. 이 연구는 복잡한 구조 변경 없이도 기존 MoE 모델에 Plug-and-Play 방식으로 적용 가능하다는 점에서 학계와 산업계의 큰 주목을 받을 것으로 기대된다. 결론적으로, BEAM은 토큰별 동적 Expert 할당의 성능과 효율성 간의 균형을 극대화하여 대규모 언어 모델 서빙의 비용 절감에 중대한 기여를 한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] HunyuanOCR-1.5: Making Lightweight OCR VLMs Faster and Better
- [논문리뷰] Gemma 4 Technical Report
- [논문리뷰] ELDR: Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving
- [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
Review 의 다른글
- 이전글 [논문리뷰] Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning
- 현재글 : [논문리뷰] BEAM: Binary Expert Activation Masking for Dynamic Routing in MoE
- 다음글 [논문리뷰] BOOKMARKS: Efficient Active Storyline Memory for Role-playing
댓글