[논문리뷰] Scaling Continual Learning to 300+ Tasks with Bi-Level Routing Mixture-of-Experts
링크: 논문 PDF로 바로 열기
메타데이터
저자: Meng Lou, Yunxiang Fu, Yizhou Yu
1. Key Terms & Definitions (핵심 용어 및 정의)
- CIL (Class-Incremental Learning): 새로운 태스크가 순차적으로 추가됨에 따라 이전에 학습한 지식을 유지하면서 새로운 클래스를 학습하는 CL의 도전적인 설정입니다.
- PTM (Pre-trained Model): 대규모 데이터셋으로 사전 학습된 모델을 의미하며, 이를 기반으로 CL을 수행하면 파라미터 효율성을 높이고 파멸적 망각을 완화할 수 있습니다.
- BR-MoE (Bi-Level Routing Mixture-of-Experts): 본 논문에서 제안하는 핵심 모듈로, 라우터 선택 단계와 전문가 라우팅 단계의 2단계 구조를 통해 지식을 효율적으로 검색하고 집계합니다.
- OmniBenchmark-1K: 본 논문에서 제안하는 1,000개 클래스를 포함하는 긴 태스크 시퀀스 평가용 벤치마크 데이터셋입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 CL 방법론들이 20개 내외의 제한된 태스크 수에서만 검증되어 왔다는 한계를 지적하며, 매우 긴 태스크 시퀀스에서 발생하는 성능 저하 문제를 해결하고자 합니다. 기존 방식들은 태스크가 늘어남에 따라 파멸적 망각(Catastrophic Forgetting)에 취약하거나, 단순히 이전 지식을 활용하는 방식이 조잡하여 정교한 지식 검색이 어렵다는 단점이 있습니다. 특히, 각기 다른 추상화 수준을 가진 네트워크 중간 계층에서 국소적인 의사결정(Local Decision)을 수행할 수 있는 메커니즘의 부재가 긴 시퀀스 학습의 걸림돌이 됩니다. 저자들은 이러한 한계를 극복하기 위해 더 확장 가능하고 지식의 차별성과 포괄성을 보장하는 새로운 구조가 필요하다고 판단했습니다 [Figure 1].
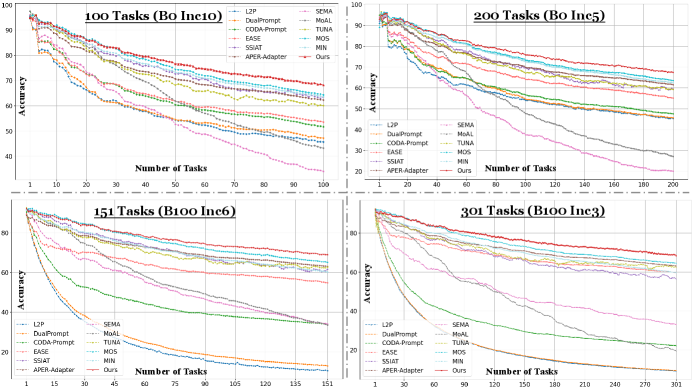
Figure 1 — CaRE의 성능 비교 결과
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 각 네트워크 레이어에 BR-MoE를 통합한 CaRE라는 모델을 제안합니다. BR-MoE는 두 단계의 라우팅을 수행하는데, 첫 번째로 클래스 퍼셉트론(Class Perceptron)의 엔트로피 기반 순위를 통해 가장 적합한 라우터 네트워크를 동적으로 선택하고, 두 번째로 선택된 라우터가 가중치를 생성하여 최상위 K개의 전문가(Adapter Experts)를 활성화합니다. 이를 통해 각 레이어에서 discriminative한 표현을 생성함과 동시에, 공유 전문가(Shared Expert)를 활용하여 지식을 점진적으로 축적합니다. 실험 결과, CaRE는 100개에서 301개에 이르는 긴 태스크 시퀀스에서 기존 SOTA 방법론들을 큰 폭으로 앞섰습니다. 100개 태스크 환경에서 CaRE는 마지막 정확도($\mathcal{A}_{B}$) 기준으로 MIN 대비 4.67%, MOS 대비 4%의 향상을 기록하였습니다 [Table 1]. 또한, 301개의 태스크 시퀀스에서도 다른 모든 베이스라인 대비 압도적인 성능 우위를 점하며, 짧은 태스크 시퀀스(5-20개) 환경에서도 일관된 성능 우위를 유지합니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 CaRE와 OmniBenchmark-1K를 통해 CL의 확장 가능성을 극대화하는 새로운 프레임워크를 제시하였습니다. 제안된 BR-MoE 메커니즘은 지식의 동적 검색 및 집계 능력을 통해 CL 모델이 수백 개의 태스크를 학습하면서도 안정성과 가소성(Stability and Plasticity)을 유지하게 합니다. 이 연구는 단순히 짧은 태스크 학습을 넘어, 실제 현실의 끊임없이 진화하는 환경에서 CL 시스템이 운영될 수 있는 발판을 마련했습니다. 향후 더 긴 태스크 시퀀스나 복잡한 Vision-Language 모델로의 확장 가능성을 시사합니다.
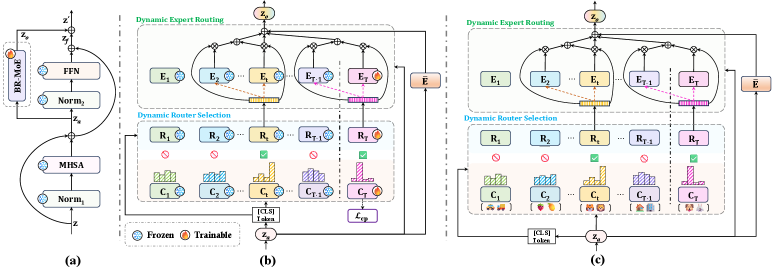
Figure 2 — BR-MoE 전체 워크플로우
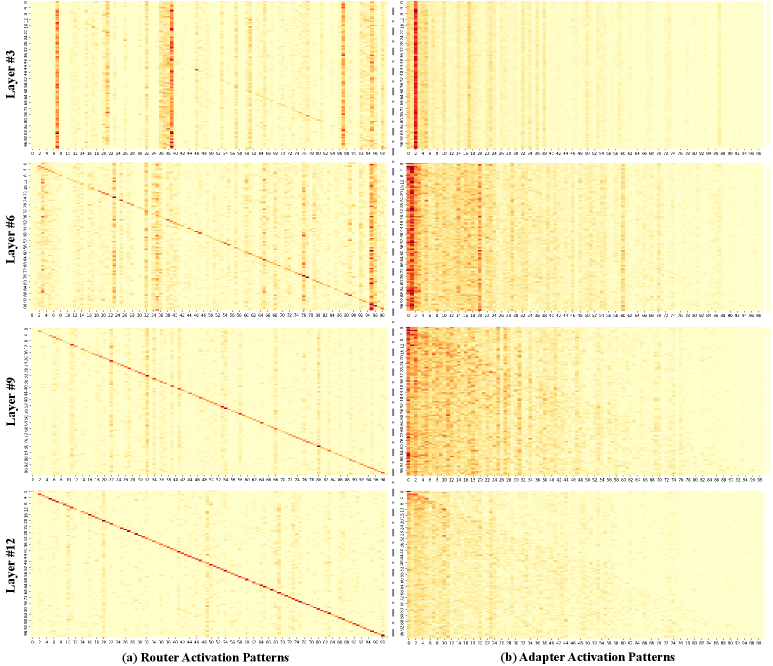
Figure 4 — 라우터 및 전문가 활성화 패턴
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PEAM: Parametric Embodied Agent Memory through Contrastive Internalization of Experience in Minecraft
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] Gemma 4 Technical Report
- [논문리뷰] UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning
- [논문리뷰] ELDR: Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving
Review 의 다른글
- 이전글 [논문리뷰] STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal Generation
- 현재글 : [논문리뷰] Scaling Continual Learning to 300+ Tasks with Bi-Level Routing Mixture-of-Experts
- 다음글 [논문리뷰] Shallow Prefill, Deep Decoding: Efficient Long-Context Inference via Layer-Asymmetric KV Visibility
댓글