[논문리뷰] STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ying Shen, Tianrong Chen, Yuan Gao, Yizhe Zhang, Yuyang Wang, Miguel Angel Bautista, Shuangfei Zhai, Josh Susskind, Jiatao Gu
1. Key Terms & Definitions (핵심 용어 및 정의)
- TARFlow (Transformer-based Autoregressive Flow): 인과적 Transformer를 기반으로 파라미터화되어, LLM과 동일한 구조적 특성을 공유하며 연속적인 시각 데이터(visual latents)를 생성하는 모델입니다.
- Pretzel Architecture: pretrained VLM 스트림과 TARFlow 스트림을 잔차 연결(residual skip connections)로 수직적으로 interleaving하여, 두 스트림이 공유된 인과적 마스크 내에서 상호작용하도록 설계된 STARFlow2의 핵심 프레임워크입니다.
- FAE (Feature Auto-Encoder): DINOv2 특징을 기반으로 학습되어, multimodal 이해와 생성 모두에 사용되는 공유된 연속적 잠재 공간(continuous latent space)을 제공하는 컴포넌트입니다.
- KV-cache: 텍스트와 시각 데이터가 동일한 인과적 구조를 가짐으로써, 중간 재인코딩(re-encoding) 과정 없이 시각적 출력을 재사용 가능한 컨텍스트로 생성할 수 있게 하는 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 통합 멀티모달 모델들이 겪는 생성 메커니즘의 구조적 파편화 문제를 해결하고자 합니다. 기존 모델들은 이산적 토큰화(discrete tokenization)로 인한 시각적 정보 손실, 혹은 텍스트의 인과적 생성과 이미지의 반복적 확산(diffusion-based denoising) 결합으로 인한 구조적 불균형이라는 한계에 직면해 있습니다. 특히, 확산 모델 기반의 하이브리드 방식은 텍스트와 이미지가 서로 다른 생성 원리를 가져 캐시 효율적인 interleaved generation을 저해합니다. 저자들은 이러한 한계를 극복하기 위해 VLM의 강력한 이해 능력을 보존하면서도 고충실도의 연속적 이미지 생성이 가능한 진정한 의미의 단일 causal 생성 프레임워크가 필요함을 역설합니다 [Figure 1].
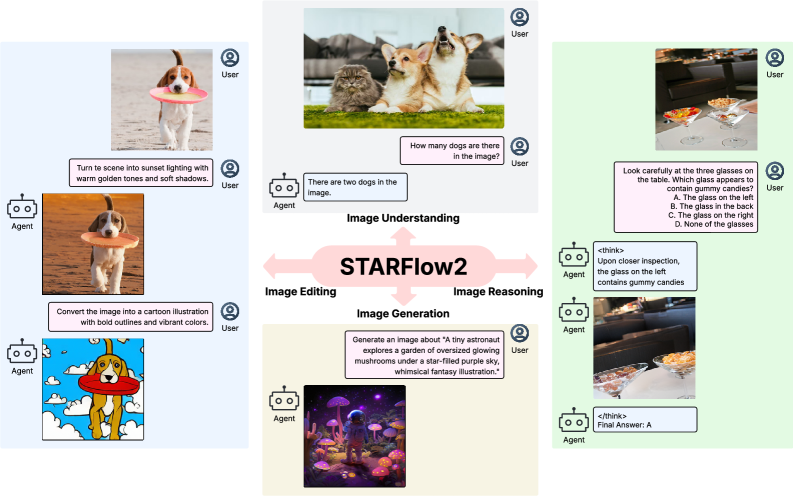
Figure 1 — STARFlow2의 전체 아키텍처 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 pretrained VLM과 TARFlow 스트림을 수직으로 결합한 Pretzel 아키텍처를 통해 이 문제를 해결합니다 [Figure 2]. 이 구조에서 frozen VLM은 의미론적 이해를 담당하고, TARFlow는 연속적인 시각적 잠재 분포를 예측하며, 두 스트림은 잔차 연결을 통해 전 위치에서 정보를 교환합니다. 저자들은 3단계 학습 파이프라인을 도입하여 1단계에서 TARFlow의 생성 성능을 확보하고, 2단계에서 VLM과의 정렬을 수행하며, 3단계에서 전체 구조를 통합 학습합니다 [Figure 3]. 실험 결과, STARFlow2는 GenEval에서 0.82, DPG-Bench에서 84.14의 점수를 기록하며 고품질 이미지 생성 성능을 입증했습니다 [Table 2, Table 3]. 특히, 3단계의 통합 학습을 통해 생성 전용 스테이지 대비 GenEval에서 60.8%의 상대적 성능 향상을 달성하며, 구조적 통합이 생성 품질에 긍정적인 영향을 미침을 증명했습니다 [Table 4].
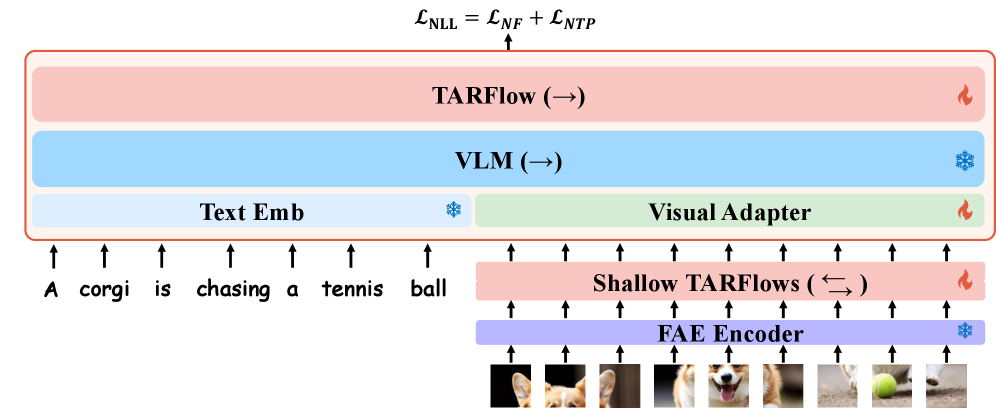
Figure 2 — Pretzel 아키텍처 상세 구조
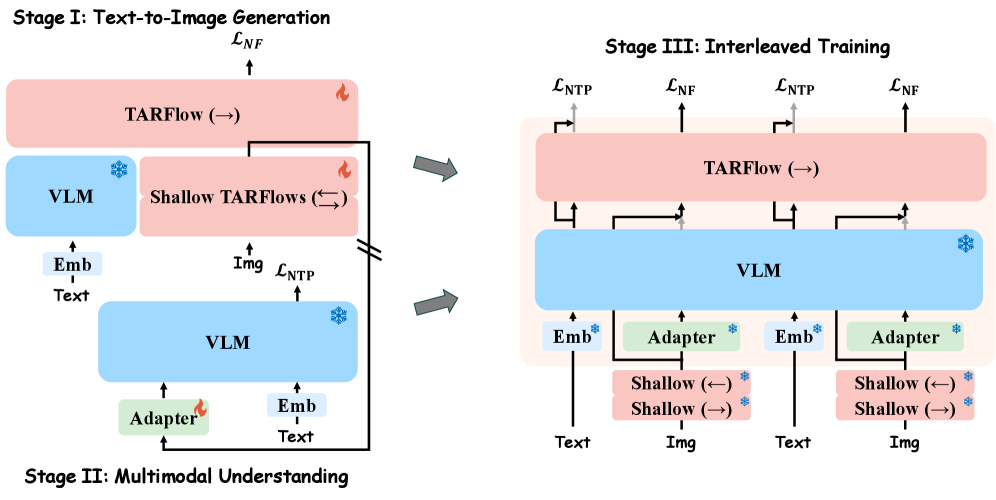
Figure 3 — 3단계 학습 파이프라인 구성
4. Conclusion & Impact (결론 및 시사점)
본 연구는 autoregressive normalizing flow를 통합 멀티모달 모델의 기초로 제안함으로써 생성과 이해의 진정한 통합 가능성을 제시했습니다. Pretzel 아키텍처는 frozen VLM의 사전 학습된 능력을 보존함과 동시에 고충실도의 연속적 이미지 생성을 지원하며, 이는 멀티모달 생성 분야에 cache-friendly하고 단일 패스(single-pass)인 새로운 파라다임을 제공합니다. 본 모델은 향후 효율적이고 유연한 멀티모달 시스템 발전에 크게 기여할 것으로 기대되며, 연구자들에게는 확산 모델을 넘어선 새로운 생성 프레임워크의 가능성을 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unified Audio Intelligence Without Regressing on Text Intelligence
- [논문리뷰] MIMFlow: Integrating Masked Image Modeling with Normalizing Flows for End-to-End Image Generation
- [논문리뷰] Data Journalist Agent: Transforming Data into Verifiable Multimodal Stories
- [논문리뷰] Latent Reasoning with Normalizing Flows
- [논문리뷰] Images in Sentences: Scaling Interleaved Instructions for Unified Visual Generation
Review 의 다른글
- 이전글 [논문리뷰] SCOPE: Structured Decomposition and Conditional Skill Orchestration for Complex Image Generation
- 현재글 : [논문리뷰] STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal Generation
- 다음글 [논문리뷰] Scaling Continual Learning to 300+ Tasks with Bi-Level Routing Mixture-of-Experts
댓글