[논문리뷰] Images in Sentences: Scaling Interleaved Instructions for Unified Visual Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yabo Zhang, Kunchang Li, Dewei Zhou, Xinyu Huang, Xun Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Inset (Images iN SEnTences): 이미지를 텍스트와 분리된 외부 참조가 아닌, 문장 내의 네이티브(native) 토큰으로 직접 삽입하여 처리하는 통합 비주얼 생성 모델입니다.
- Interleaved Instructions: 텍스트와 이미지가 혼합된 다중 참조 입력 형식을 의미하며, 모델이 여러 이미지의 시각적 컨텍스트를 이해하고 결합하여 출력물을 생성하게 합니다.
- Semantic ViT Tokenizer: 픽셀 단위의 VAE 잠재 공간이 아닌, 의미론적(semantic) 수준의 시각적 토큰을 추출하여 객체 간의 관계를 명확히 이해하도록 돕는 인코더입니다.
- InterleaveBench: 복잡한 다중 이미지 구성과 정밀한 공간적 추론을 평가하기 위해 제안된 벤치마크 데이터셋입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 멀티모달 생성 모델들이 복잡한 다중 이미지 명령을 처리할 때 발생하는 성능 저하 문제를 해결하기 위해 제안되었습니다. 기존의 방법론들은 이미지를 텍스트와 구조적으로 분리하여 별도의 인덱스(예: "Image 1")를 통해 간접적으로 참조하는 방식을 사용하기 때문에, 긴 입력 시퀀스에서 멀리 떨어진 시각적 정보와 텍스트를 매칭하는 데 어려움을 겪습니다 [Figure 2]. 또한, 대규모의 복잡한 인터리브드 데이터를 학습할 자원이 부족하여 모델의 추론 및 합성 능력이 제한적이라는 한계가 있습니다. 이러한 이유로 시각적 정보를 텍스트 문장 내에 직접 배치하여 모델의 이해도를 높이는 새로운 접근 방식이 요구됩니다 [Figure 1].

Figure 1 — INSET의 모델 개념도
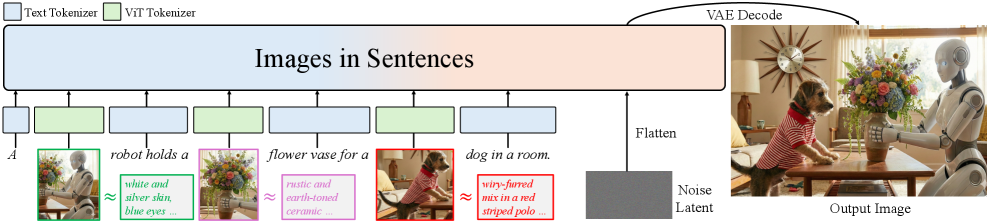
Figure 2 — INSET 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 이미지를 네이티브 어휘로 문장에 임베딩하는 Inset 프레임워크와 이를 학습시키기 위한 확장 가능한 데이터 엔진을 제안합니다. Inset은 Semantic ViT Tokenizer를 통해 이미지를 언어의 일부로 처리하며, 트랜스포머의 contextual locality를 활용하여 텍스트와 이미지 사이의 precise object binding을 수행합니다 [Figure 2]. 저자들은 VLM과 LLM을 조합하여 이미지 및 비디오 데이터셋으로부터 15M 규모의 고품질 인터리브드 샘플을 합성하는 데이터 엔진을 개발하였습니다 [Figure 3]. InterleaveBench를 통한 정량적 평가 결과, Inset은 5개의 입력 객체를 사용하는 난이도 높은 상황에서 기존 오픈소스 모델 대비 Image Consistency에서 0.29, Text Consistency에서 0.24 높은 수치를 기록하며 압도적인 성능 우위를 증명했습니다 [Table 1]. 또한, 별도의 추가 학습 없이도 인터리브드 명령을 활용한 고도로 정밀한 multimodal image editing이 가능함을 입증하였습니다 [Figure 6].
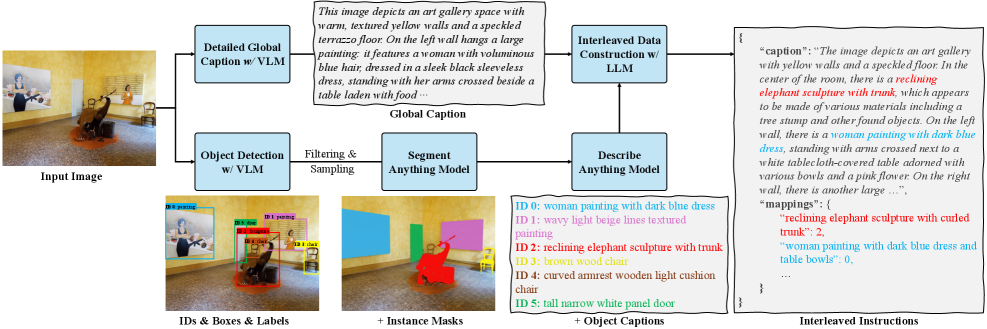
Figure 3 — 인터리브드 데이터 합성 과정
4. Conclusion & Impact (결론 및 시사점)
본 연구는 시각적 정보를 텍스트 토큰과 동일한 위치에 배치하는 통합 모델 Inset을 통해 복잡한 멀티모달 생성의 패러다임을 전환하였습니다. 이 모델은 기존의 indirect referencing이 가진 long-range dependency 문제를 효과적으로 해결하며, 확장성 있는 데이터 엔진을 통해 생성 성능을 극대화했습니다. 연구 결과는 향후 다중 이미지 환경에서 더욱 직관적이고 일관성 있는 생성 시스템을 구축하는 데 중요한 토대를 마련할 것으로 기대됩니다. 이는 단순히 정적 이미지 생성을 넘어 동적 상태 조작과 같은 고급 편집 영역으로도 기술적 확장성을 확보했다는 점에서 큰 의의를 갖습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unified Audio Intelligence Without Regressing on Text Intelligence
- [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
- [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
- [논문리뷰] Variable-Width Transformers
- [논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
Review 의 다른글
- 이전글 [논문리뷰] From Web to Pixels: Bringing Agentic Search into Visual Perception
- 현재글 : [논문리뷰] Images in Sentences: Scaling Interleaved Instructions for Unified Visual Generation
- 다음글 [논문리뷰] Lite3R: A Model-Agnostic Framework for Efficient Feed-Forward 3D Reconstruction
댓글