[논문리뷰] SNLP: Layer-Parallel Inference via Structured Newton Corrections
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ligong Han, Kai Xu, Hao Wang, Akash Srivastava, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- SNLP (Structured Newton Layer Parallelism): Transformer의 계층 간 순차적 의존성을 해결하기 위해, 정밀한 Jacobian 대신 저비용의 구조화된 대리(Surrogate) 모델을 사용하여 계층별 상태를 병렬로 업데이트하는 학습 및 추론 프레임워크입니다.
- IDN (Identity Newton): 잔차 연결(Residual connections)이 존재하는 Transformer 블록에서, Jacobian의 대리 연산자로 Identity 행렬을 사용하는 기법입니다. 이는 Newton 수정을 계층 간 가산적 전파(Additive propagation)로 단순화합니다.
- HCN (HC Newton): Hyper-connection 및 mHC 아키텍처에서 학습된 잔차 혼합 행렬을 사용하여 신경망의 깊이별 민감도를 구조적으로 근사하는 방식입니다.
- SNLP-aware Regularization: 학습 과정에서 구조화된 Newton 반복 연산이 원래의 순차적 추론 결과와 일치하도록 유도하여, 추론 시 병렬 처리 효율과 모델의 품질을 동시에 최적화하는 학습 기법입니다.
- Chunkwise Layer Fusion: 여러 개의 Transformer 계층을 하나의 더 넓은 실행 단위(Chunk)로 결합하여, 하드웨어(GPU) 가속을 극대화하고 계층 간 병렬성을 확보하는 최적화 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Transformer 모델의 고질적인 문제인 Layer-wise Dependency로 인한 추론 지연(Latency) 문제를 해결하고자 합니다. 기존의 Tensor Parallelism이나 Pipeline Parallelism은 계층 내 병렬화나 배치를 최적화할 뿐, 깊이 방향의 순차적인 의존성 체인은 제거하지 못하는 한계가 있습니다. 이를 해결하기 위해 전체 계층의 hidden state trace를 비선형 잔차 방정식의 해로 간주하여 병렬적으로 풀이하려는 시도가 존재했으나, 정밀한 Jacobian 계산이 불가능하거나 비용이 너무 높다는 문제가 있었습니다. 본 논문은 구조화된 대리 연산자를 도입하여 이 문제를 실용적으로 해결하고자 합니다 [Figure 1].
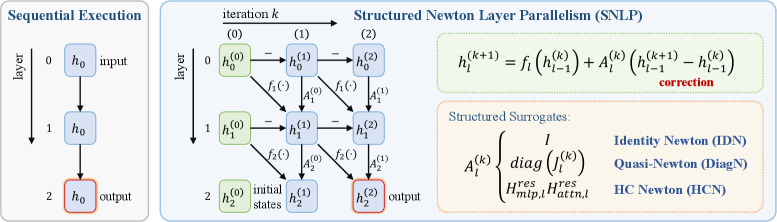
Figure 1 — SNLP 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 SNLP를 통해 Transformer 계층의 Jacobian을 아키텍처 내재적 대리 연산자(IDN, DiagN, HCN)로 교체하여 고비용의 순차적 계산을 경량의 구조화된 반복 연산으로 변환합니다. SNLP-aware Regularization은 학습 단계에서부터 이러한 병렬 추론 방식에 적응하도록 모델을 설계하며, Chunkwise Layer Fusion을 통해 연산 강도를 조절하여 하드웨어 가속을 실현합니다. 주요 실험 결과로 Nanochat-0.5B 모델에서 최대 **2.3×**의 Wall-clock 속도 향상을 기록하면서도, 기존 순차적 모델 대비 Perplexity(PPL)를 오히려 6.1% 개선하는 성과를 보였습니다. 또한, 전반적인 Nanochat 모델 실험에서 SNLP-aware regularization을 통해 baseline PPL을 4.7%–23.4%까지 낮추는 정량적 성능 향상을 입증했습니다 [Table 1].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 계층 병렬 추론이 단순한 수치적 근사를 넘어, 'Solver-induced inference bias'로서 모델의 성능을 향상시킬 수 있는 유용한 도구가 될 수 있음을 입증했습니다. 이 연구는 대형 언어 모델의 깊이 방향 병렬화에 대한 새로운 패러다임을 제시하며, 특히 모델 아키텍처와 추론 방식의 공동 설계(Co-design)가 효율적이고 고품질인 LLM 서비스에 필수적임을 시사합니다. 향후 더 큰 규모의 모델에서도 실질적인 속도 향상을 끌어내기 위한 최적화 커널 개발이 학계 및 산업계에 중요한 도전 과제가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding
- [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
- [논문리뷰] GEAR: Guided End-to-End AutoRegression for Image Synthesis
- [논문리뷰] BrainJanus: A Unified Model for Understanding and Generation across Brain, Vision, and Language
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
Review 의 다른글
- 이전글 [논문리뷰] Post-Trained MoE Can Skip Half Experts via Self-Distillation
- 현재글 : [논문리뷰] SNLP: Layer-Parallel Inference via Structured Newton Corrections
- 다음글 [논문리뷰] SafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
댓글