[논문리뷰] Lite3R: A Model-Agnostic Framework for Efficient Feed-Forward 3D Reconstruction
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haoyu Zhang, Zeyu Zhang, Zedong Zhou, Yang Zhao, Hao Tang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Sparse Linear Attention (SLA): 3D reconstruction의 dense multi-view attention 비용을 줄이기 위해, 중요한 geometric correspondence는 sparse branch로 유지하고 전체적인 문맥은 linear branch로 처리하는 하이브리드 어텐션 모듈입니다.
- FP8-aware QAT: 저자들이 제안하는 저전력 배포를 위한 학습 기법으로, FP8(E4M3 포맷)의 양자화 노이즈를 학습 과정에 시뮬레이션하여 저정밀도 환경에서도 모델의 안정성을 보장합니다.
- Partial Attention Distillation: Structural modification(SLA 적용)과 quantization으로 인한 성능 저하를 방지하기 위해, 중간 어텐션 모듈의 출력을 dense teacher 모델과 일치시키는 지식 증류 방식입니다.
- Algorithm-System Co-design: 단순한 연산 최적화를 넘어 모델 구조(SLA), 학습 전략(FP8-aware QAT), 배포 파이프라인(weight-only inference)을 통합적으로 설계하여 end-to-end 효율성을 극대화하는 접근 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Transformer 기반 3D reconstruction 파이프라인이 겪는 연산 효율성 및 저정밀도 실행 시의 불안정성 문제를 해결하고자 합니다. 기존의 dense multi-view attention은 고해상도 입력 처리 시 막대한 token-mixing 오버헤드를 발생시키며, 이를 저정밀도로 단순히 변환할 경우 수치적 교란(numerical perturbation)이 깊이(depth) 및 자세(pose) 예측 성능을 크게 저하시킵니다 [Figure 1]. 이러한 한계점은 대규모 backbone 모델을 실시간 또는 모바일 기기에 배포하는 데 큰 걸림돌이 되며, 이를 극복하기 위해 구조적 경량화와 수치적 강건성을 동시에 확보하는 새로운 adaptation 프레임워크가 필수적입니다.

Figure 1 — Lite3R 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 dense pretrained 3D reconstruction backbone을 경량화된 학생 모델로 전환하는 Lite3R 프레임워크를 제안합니다 [Figure 2]. Lite3R은 dense attention을 Sparse Linear Attention(SLA)으로 교체하여 연산 효율을 높이고, FP8-aware QAT를 통해 저정밀도 환경에서의 학습을 수행하며, Partial Attention Distillation을 통해 teacher 모델의 내부 표현을 보존합니다. 특히, backbone의 대부분 파라미터를 freeze하고 lightweight linear-branch projection layer만을 업데이트하는 parameter-efficient 학습 전략을 채택합니다. 실험 결과, VGGT backbone 기준 BlendedMVS 데이터셋에서 **1.76×**의 Latency 개선과 **2.32×**의 메모리 절감을 달성하였습니다 [Table 1]. 또한, DA3-Large backbone에서도 **1.97×**의 Latency 단축과 **1.98×**의 메모리 절감을 기록하며 competitive한 reconstruction quality를 유지함을 입증하였습니다 [Table 1, Table 2]. 정성적 분석에서도 기존 teacher 모델 대비 주요 장면 기하 구조를 효과적으로 보존함을 확인했습니다 [Figure 3].
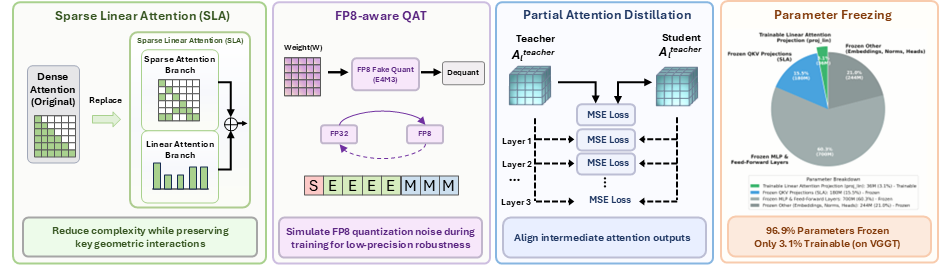
Figure 2 — Lite3R 전체 아키텍처

Figure 3 — 정성적 결과 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 3D reconstruction 분야에서 Transformer 기반 모델을 효율적으로 배포하기 위한 실용적인 algorithm-system co-design 방법론인 Lite3R을 제시합니다. SLA 기반의 구조적 경량화와 FP8-aware QAT를 결합함으로써, 연구진은 고성능 모델의 기하학적 사전 지식을 저전력 환경으로 성공적으로 이전하였습니다. 이 연구는 대규모 비전 모델의 실제 현장 배포 장벽을 낮추며, 실시간 구조 복원 및 3D SLAM 시스템 등 산업계와 학계의 차세대 효율적 비전 애플리케이션 개발에 중요한 기술적 토대를 마련할 것으로 평가됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
- [논문리뷰] Enhancing Object Detection with Privileged Information: A Model-Agnostic Teacher-Student Approach
- [논문리뷰] InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
- [논문리뷰] MV-Forcing: Long Multi-View Video Generation via 4D-Grounded Spatio-Temporal Self-Forcing
- [논문리뷰] From SRA to Self-Flow: Data Augmentation or Self-Supervision?
Review 의 다른글
- 이전글 [논문리뷰] Images in Sentences: Scaling Interleaved Instructions for Unified Visual Generation
- 현재글 : [논문리뷰] Lite3R: A Model-Agnostic Framework for Efficient Feed-Forward 3D Reconstruction
- 다음글 [논문리뷰] MoCam: Unified Novel View Synthesis via Structured Denoising Dynamics
댓글