[논문리뷰] EndPrompt: Efficient Long-Context Extension via Terminal Anchoring
링크: 논문 PDF로 바로 열기
메타데이터
저자: Han Tian, Luxuan Chen, Xinran Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- EndPrompt: 원본의 짧은 컨텍스트를 유지하면서 시퀀스 끝에 터미널 프롬프트를 추가하여 장거리 상대 위치 정보를 모델에 학습시키는 효율적인 방법론입니다.
- Positional Index Manipulation: 물리적 시퀀스 길이를 늘리지 않고도 할당된 positional index를 조작하여 모델이 장거리 컨텍스트의 상대 위치 관계를 학습하도록 하는 기법입니다.
- Terminal Anchoring: 컨텍스트 윈도우 끝단에 학습 가능한 혹은 고정된 터미널 프롬프트를 배치하여, 모델이 장거리 주의(Attention)를 안정적으로 생성하도록 유도하는 구조적 기법입니다.
- PI (Positional Interpolation): RoPE의 angular frequency를 축소하여 모델이 학습하지 않은 긴 컨텍스트 윈도우를 처리할 수 있도록 위치 값을 보간하는 기술입니다.
- RoPE (Rotary Position Embedding): 위치 정보를 복소수 평면에서의 회전 행렬로 인코딩하여 상대적 거리 정보를 효율적으로 포착하는 위치 임베딩 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 컨텍스트 윈도우 확장이 요구하는 막대한 계산 자원과 데이터 수집의 어려움을 해결하기 위해 EndPrompt를 제안합니다. 기존의 전체 길이(Full-length) 파인튜닝 방식은 quadratic memory 및 계산 복잡도로 인해 비용이 매우 높으며, 일부 chunk 기반 시뮬레이션 방식은 텍스트의 의미적 연속성을 파괴하여 성능을 저하시키는 문제가 있습니다. 저자들은 긴 시퀀스 전체를 학습하지 않고도 구조화된 sparse positional supervision만으로 장거리 컨텍스트 일반화가 가능한지 의문을 제기합니다 [Figure 1].
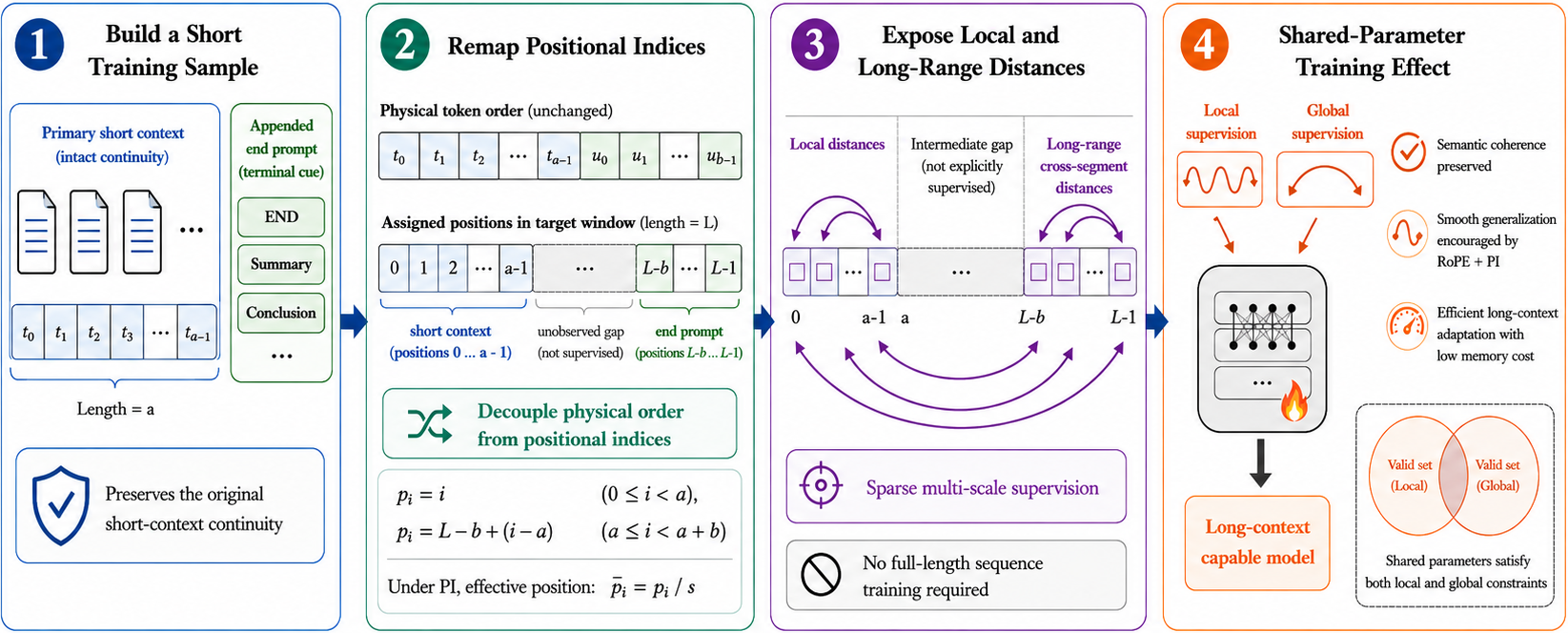
Figure 1 — EndPrompt 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 원본의 짧은 컨텍스트를 손상 없이 유지하고, 그 뒤에 터미널 프롬프트를 배치하여 타겟 컨텍스트 윈도우 끝단으로 위치 인덱스를 매핑하는 방식을 제안합니다 [Figure 1]. 이를 통해 모델은 물리적으로는 짧은 시퀀스를 처리하지만, 로컬 및 장거리 상대 위치 정보를 동시에 학습하게 됩니다. RoPE와 PI의 이론적 특성을 활용하여, 학습되지 않은 중간 거리의 위치 변화율을 제어함으로써 안정적인 extrapolation을 구현합니다. 실험 결과, LLaMA-3-8B 기반의 EndPrompt는 8K에서 64K로 컨텍스트를 확장했을 때, RULER 벤치마크에서 평균 76.03 점을 기록하며 LCEG (72.24), LongLoRA (72.95), Full-length fine-tuning (69.23)을 상회하는 성능을 보였습니다 [Table 1]. 또한, LongBench에서도 가장 높은 평균 성능을 기록하며, 메모리 사용량은 전체 파인튜닝 대비 52% 감소시키고 학습 속도는 유의미하게 개선했습니다 [Figure 4].
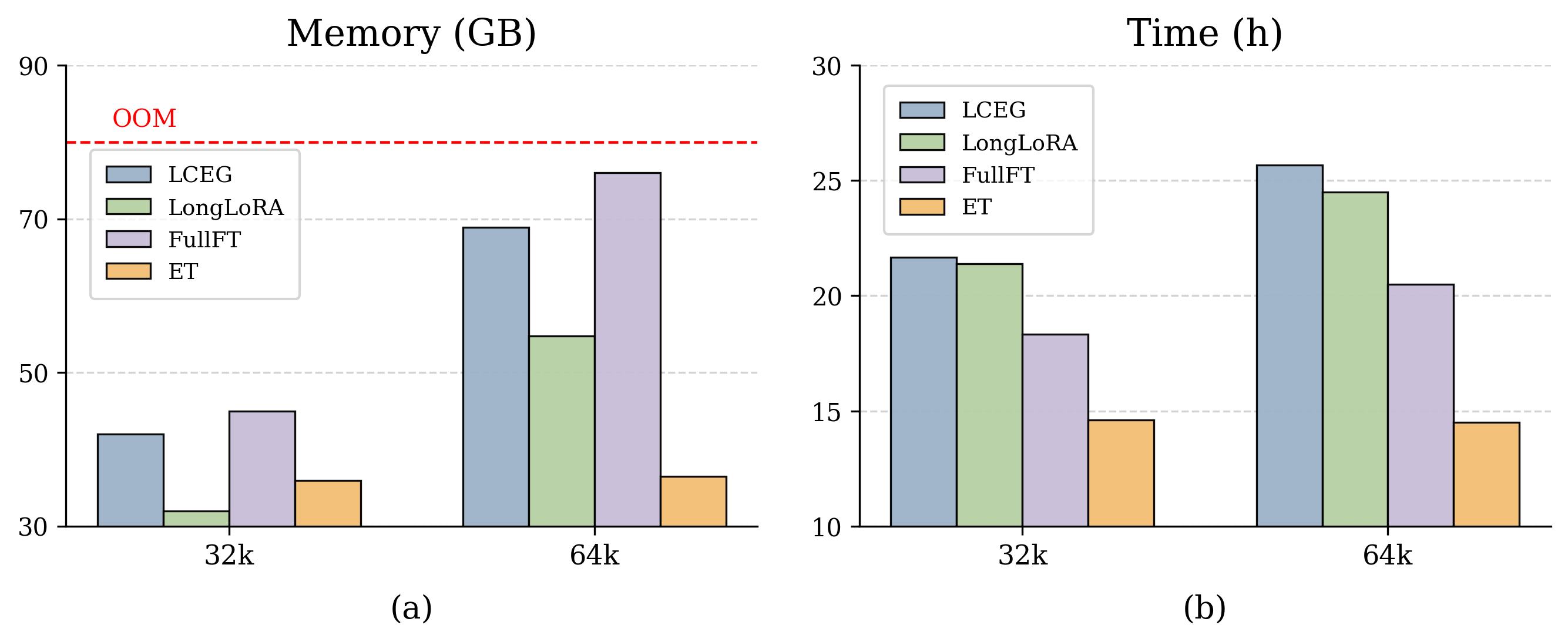
Figure 4 — 메모리 및 연산 효율성
4. Conclusion & Impact (결론 및 시사점)
본 논문은 조밀한 장문 학습 없이도 구조화된 sparse positional supervision을 통해 효율적인 long-context 확장이 가능함을 입증했습니다. EndPrompt는 텍스트의 의미적 연속성을 보존하면서도 안정적인 terminal anchoring을 제공함으로써 대규모 모델의 컨텍스트 윈도우 확장 방식을 재정립했습니다. 본 연구의 결과는 학계 및 산업계에서 컨텍스트 확장 시 소요되는 연산 비용을 획기적으로 절감할 수 있는 실용적인 가이드라인을 제시하며, 향후 스트리밍 및 멀티모달 아키텍처로의 확장 가능성을 열어두었습니다.
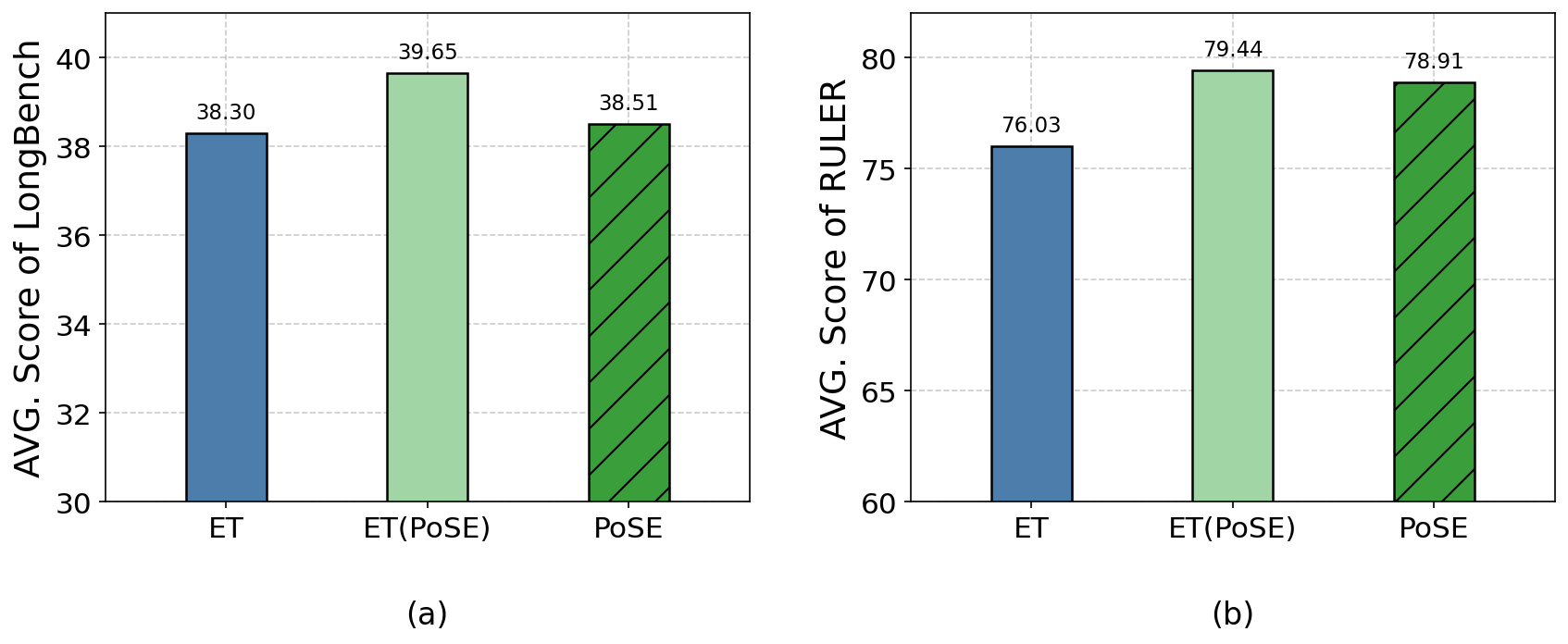
Figure 3 — 벤치마크 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Group Representational Position Encoding
- [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
- [논문리뷰] RoPE-Aware Bit Allocation for KV-Cache Quantization
- [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
- [논문리뷰] Variable-Width Transformers
Review 의 다른글
- 이전글 [논문리뷰] E-PMQ: Expert-Guided Post-Merge Quantization with Merged-Weight Anchoring
- 현재글 : [논문리뷰] EndPrompt: Efficient Long-Context Extension via Terminal Anchoring
- 다음글 [논문리뷰] Evaluating Cognitive Age Alignment in Interactive AI Agents
댓글