[논문리뷰] E-PMQ: Expert-Guided Post-Merge Quantization with Merged-Weight Anchoring
링크: 논문 PDF로 바로 열기
저자: Wenjun Wang, Yanggan Gu, Shuo Cai, Yuanyi Wang, Pengkai Wang, Jianmin Wu, Hongxia Yang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- PMQ (Post-Merge Quantization): 여러 전문가 모델을 하나로 합친(Merged) 모델을 대상으로 수행하는 Post-Training Quantization 기법입니다.
- Expert-relative Merging Deviation: 모델 병합 과정에서 발생하는 파라미터 구성상의 오차로, 병합된 모델이 원본 전문가 모델들의 고유 동작에서 벗어나는 현상을 의미합니다.
- Merged-Weight Anchoring: 양자화 과정 중 모델의 파라미터가 원본 병합 모델의 가중치로부터 지나치게 멀어지지 않도록 제약을 가하여, 모델의 통합된 동작을 보존하는 기법입니다.
- Quantization Deviation: 저비트 양자화로 인한 재구성 오차로, 기존 PTQ 연구에서 주로 다루는 주요 최적화 대상입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 모델 병합(Model Merging) 후 저비트 양자화(Low-bit Quantization)를 적용할 때 발생하는 성능 저하 문제를 해결하고자 합니다. 기존의 PTQ 기법들은 단일 전문가 모델을 대상으로 개발되었기에, 이미 전문가 모델들과의 괴리를 포함하고 있는 병합 모델(Merged Model)을 양자화할 경우 병합 오차와 양자화 오차가 결합하여 결과 모델의 성능이 급격히 저하되는 문제가 있습니다. 특히 naive PMQ 방식은 병합 모델만을 유일한 복원 대상으로 삼아 이러한 오차를 증폭시키므로, 이를 극복할 수 있는 새로운 접근 방식이 필수적입니다 [Figure 1].
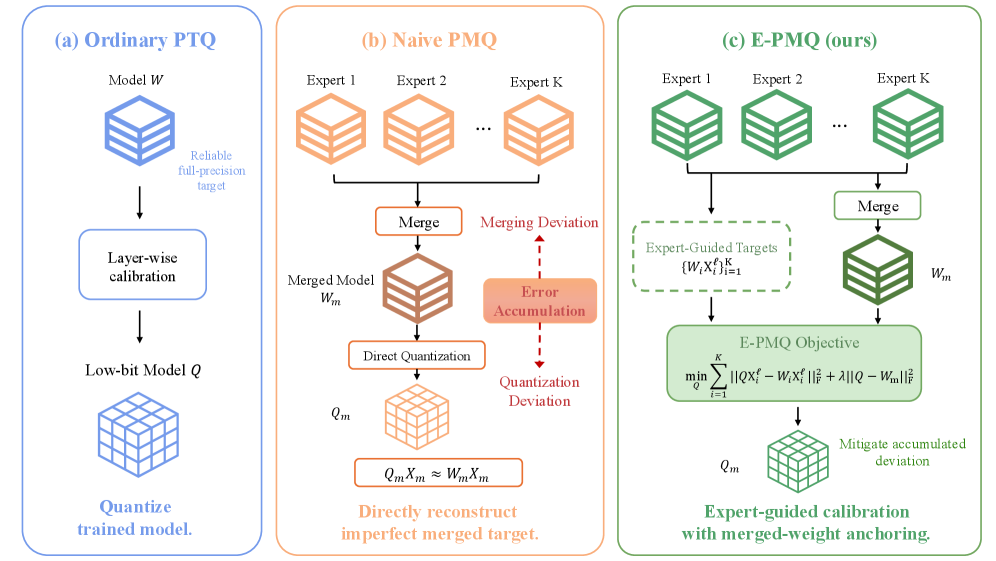
Figure 1 — PTQ, Naive PMQ, E-PMQ 비교
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 전문가 가중치를 활용해 양자화를 가이드하고 앵커링(Anchoring)을 통해 안정성을 확보하는 E-PMQ 프레임워크를 제안합니다. E-PMQ는 레이어별 보정(Calibration) 과정에서 소스 전문가들의 가중치를 활용하여 expert-guided output targets을 생성함으로써 오차를 보정합니다 [Figure 1]. 또한, 학습된 모델의 통합된 기능을 유지하기 위해 merged-weight anchoring을 도입하여 양자화된 가중치가 병합 모델 가중치에 수렴하도록 유도합니다. 실험 결과, E-PMQ는 CLIP-ViT-B/32 모델의 8개 작업 병합 설정에서 4-bit GPTQ 대비 Task Arithmetic 환경에서 65.0%에서 73.6%로, TIES-Merging에서 69.1%에서 74.8%로 정확도를 개선하였습니다 [Table 1]. 또한, 더욱 복잡한 20개 작업의 CLIP-ViT-L/14 설정에서는 GPTQ 대비 34.8%에서 76.7%로, FLAN-T5-base에서는 78.26%에서 83.34%로 우수한 성능을 입증하였습니다 [Table 3, Table 11]. 이러한 결과는 다양한 작업 규모, 모달리티(Modality), 양자화 비트 폭에서도 일관되게 나타납니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 병합된 모델을 효율적으로 저비트 배포하기 위한 PMQ 설정을 정립하고, 이에 최적화된 E-PMQ 프레임워크를 통해 모델 병합과 양자화 간의 상호작용 문제를 성공적으로 해결하였습니다. 이 연구는 리소스 제약이 있는 환경에서 다중 전문가 능력을 단일 저비트 모델로 통합하려는 학계 및 산업계의 실용적인 요구를 충족합니다. 향후 더욱 대규모의 LLM이나 다양한 모델 병합 시나리오에서도 본 프레임워크는 강력한 압축 및 배포 솔루션으로서 중요한 가치를 지닐 것으로 기대됩니다.
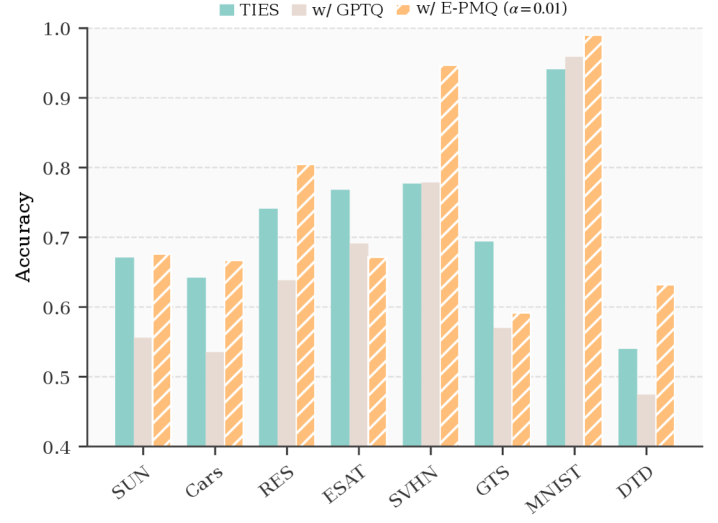
Figure 2 — E-PMQ 앵커링 가중치 절삭 분석
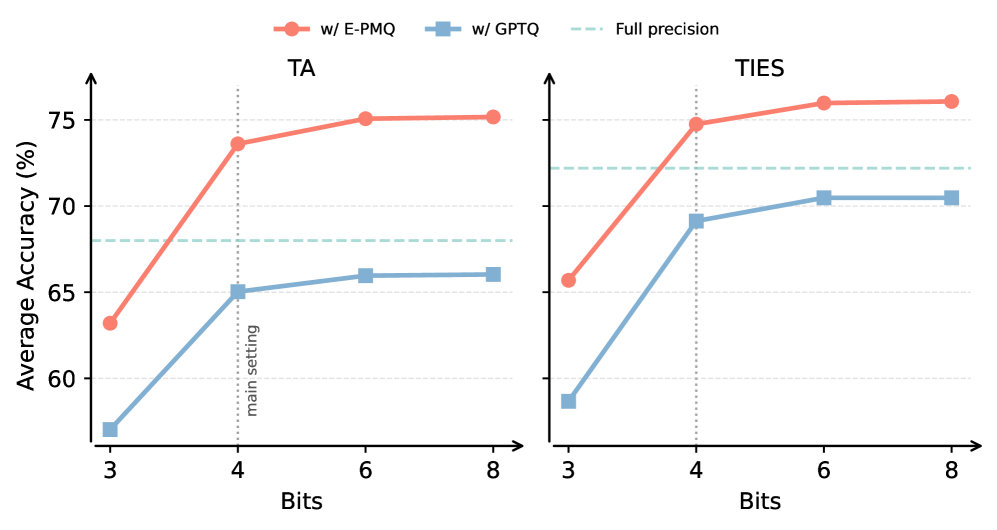
Figure 3 — 다양한 비트 폭에서의 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Optimizing Visual Generative Models via Distribution-wise Rewards
- [논문리뷰] Towards Truly Multilingual ASR: Generalizing Code-Switching ASR to Unseen Language Pairs
- [논문리뷰] Access Sets Matter: Budgeting Expert Reads for Scalable Weight-Space Model Merging
- [논문리뷰] Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
- [논문리뷰] Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning
Review 의 다른글
- 이전글 [논문리뷰] CompactAttention: Accelerating Chunked Prefill with Block-Union KV Selection
- 현재글 : [논문리뷰] E-PMQ: Expert-Guided Post-Merge Quantization with Merged-Weight Anchoring
- 다음글 [논문리뷰] EndPrompt: Efficient Long-Context Extension via Terminal Anchoring
댓글