[논문리뷰] Learning to Communicate Locally for Large-Scale Multi-Agent Pathfinding
링크: 논문 PDF로 바로 열기
저자: Valeriy Vyaltsev, Alsu Sagirova, Anton Andreychuk, Oleg Bulichev, Yuri Kuratov, Konstantin Yakovlev, Aleksandr Panov, Alexey Skrynnik
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- LC-MAPF (Local Communication for Multi-agent Pathfinding): 근거리 이웃과의 반복적인 메시지 교환을 통해 에이전트 간 조정을 강화하는 탈중앙화(decentralized) 학습 프레임워크입니다.
- Dec-POMDP (Decentralized Partially Observable Markov Decision Process): 각 에이전트가 부분적인 관측 정보만을 가지고 독자적으로 의사결정을 내리는 MAPF의 문제 정의 모델입니다.
- Transformer Encoder-Decoder: 에이전트의 관측값을 잠재 표현(latent representation)으로 변환하고, 이웃 메시지를 융합하여 최종 행동을 결정하는 LC-MAPF의 핵심 신경망 구조입니다.
- Collision Shielding: 학습된 정책이 생성한 행동에서 충돌이 예상될 때, 안전을 위해 우선순위 기반의 PIBT(Priority-Inheritance with Backtracking) 절차로 행동을 수정하는 사후 처리 메커니즘입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 대규모 다중 에이전트 시스템에서 충돌 없는 경로 탐색을 효율적으로 수행하기 위한 탈중앙화 MAPF 솔루션의 한계를 극복하고자 합니다. 기존의 학습 기반 방식(예: MAPF-GPT)은 에이전트 간의 명시적인 통신이 결여되어 있어 복잡한 환경에서의 협동 성능이 제한적이거나, 통신 메커니즘을 갖춘 모델들은 단일 라운드 통신에 그쳐 정교한 조정을 수행하기 어렵다는 문제가 있습니다. 또한, 기존 솔루션들은 에이전트 수가 증가함에 따라 계산 복잡도가 급격히 상승하는 확장성(scalability) 문제를 겪고 있습니다. 저자들은 이러한 제약을 해결하기 위해 데이터 기반의 탈중앙화 모델에 반복적 통신 기능을 통합한 새로운 프레임워크를 제안합니다 [Figure 1].
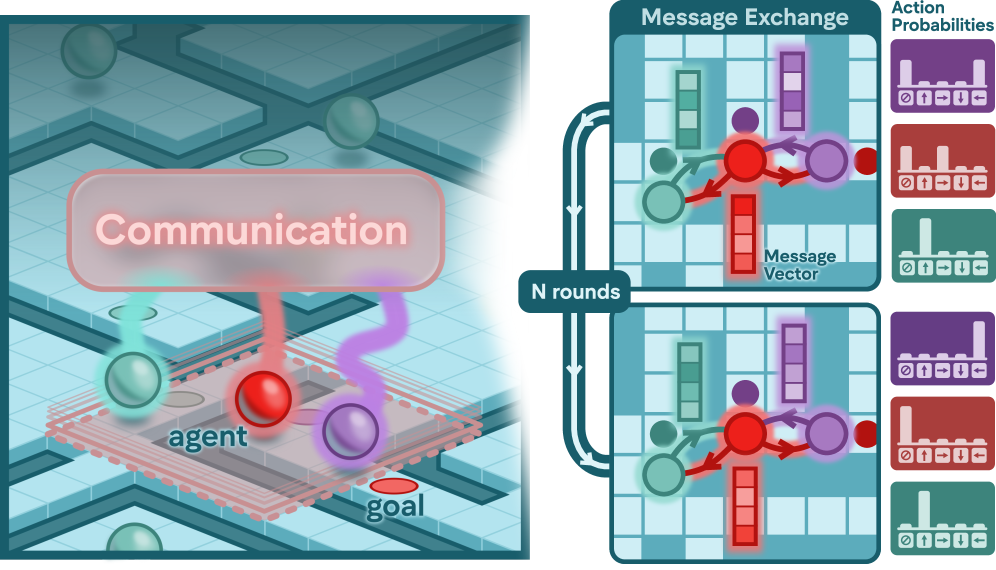
Figure 1 — 반복적 메시지 교환 개념
## 3. Method & Key Results (제안 방법론 및 핵심 결과) LC-MAPF는 Transformer 기반의 인코더와 디코더 구조를 사용하여, 에이전트가 로컬 관측치를 임베딩하고 이를 이웃 에이전트들과 R=4 라운드에 걸쳐 반복적으로 교환함으로써 조정된 행동 분포를 산출하는 방식을 채택합니다 [Figure 2]. 학습 과정에서는 명시적인 통신 감독(communication supervision) 없이, 전문가 시연(expert demonstration)으로부터 유도된 행동 손실(action loss)을 사용하여 통신을 위한 latent 메시지를 end-to-end로 최적화합니다. 실험 결과, LC-MAPF는 POGEMA 벤치마크에서 기존의 최신 모델인 MAPF-GPT, MAGAT+, HMAGAT 대비 높은 성공률(Success Rate)을 기록했습니다 [Figure 3]. 정량적 성능 지표인 SoC (Solution Cost) 비율에서도 LaCAM*과 같은 중앙 집중식 플래너에 근접한 결과를 도출하며 우위를 입증했습니다 [Figure 4]. 특히, 1,000개에서 5,000개 에이전트에 이르는 대규모 환경에서도 선형적인 확장성을 유지하며 안정적으로 작동함을 보였습니다.
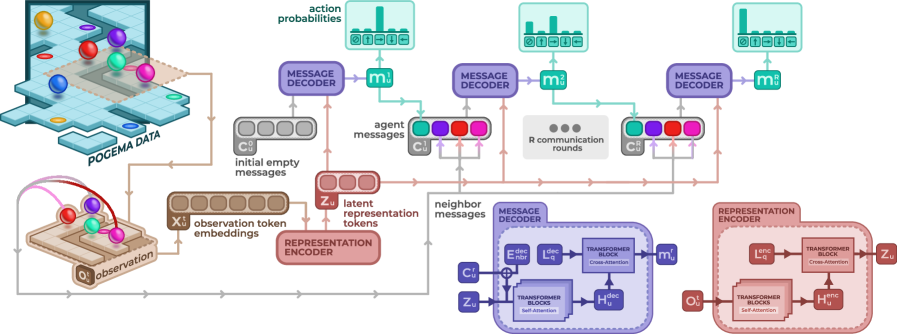
Figure 2 — LC-MAPF 아키텍처
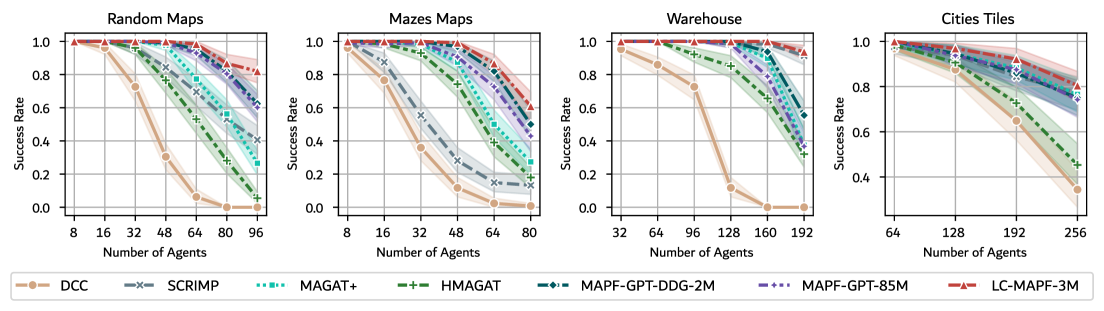
Figure 3 — 에이전트 수별 성공률 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 반복적인 로컬 통신을 통해 탈중앙화 MAPF의 협동성과 성능을 획기적으로 개선한 LC-MAPF 프레임워크를 제안하였습니다. 제안 모델은 통신 효율성과 확장성을 동시에 확보하였으며, 시뮬레이션뿐만 아니라 실제 다중 로봇 플랫폼에서도 성공적으로 배포되어 실용성을 입증했습니다. 이 연구는 대규모 다중 에이전트 시스템에서 학습 기반 솔루션이 어떻게 통신 효율성을 갖추며 고성능을 낼 수 있는지에 대한 중요한 가이드라인을 제시하며, 향후 자율 주행 및 물류 자동화 분야의 핵심 기술로 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ACG: Action Coherence Guidance for Flow-based VLA models
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] SIEVE: Structure-Aware Data Selection for Imitation Learning with VLA Models
- [논문리뷰] RynnWorld-Teleop: An Action-Conditioned World Model for Digital Teleoperation
- [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
Review 의 다른글
- 이전글 [논문리뷰] Learning to Build the Environment: Self-Evolving Reasoning RL via Verifiable Environment Synthesis
- 현재글 : [논문리뷰] Learning to Communicate Locally for Large-Scale Multi-Agent Pathfinding
- 다음글 [논문리뷰] LiSA: Lifelong Safety Adaptation via Conservative Policy Induction
댓글