[논문리뷰] M2Retinexformer: Multi-Modal Retinexformer for Low-Light Image Enhancement
링크: 논문 PDF로 바로 열기
메타데이터
저자: Youssef Aboelwafa, Hicham G. Elmongui, Marwan Torki
1. Key Terms & Definitions (핵심 용어 및 정의)
- M2Retinexformer: 본 논문에서 제안하는 Multi-modal Retinexformer로, RGB 기반의 기존 Retinexformer에 depth, luminance, semantic features를 통합한 프레임워크입니다.
- MMCAB (Multi-Modal Cross-Attention Block): RGB 피처와 auxiliary modality 피처 간의 상호작용을 통해 정보를 융합하는 핵심 모듈입니다.
- Adaptive Gating: RGB 기반의 illumination-guided self-attention과 auxiliary modality 기반의 cross-attention 사이의 기여도를 modality의 신뢰도에 따라 동적으로 조절하는 기법입니다.
- Retinex Theory: 이미지를 조명(illumination)과 반사(reflectance) 성분으로 분해하여 저조도 이미지를 복원하는 물리적 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Retinex 기반 딥러닝 기법들이 RGB 정보에만 의존하여 장면의 기하학적 구조나 조명 분포를 효과적으로 해석하지 못한다는 한계를 해결하고자 합니다. 기존의 Retinexformer는 단일 단계의 Illumination-Guided Transformer를 통해 우수한 성능을 보였으나, 암부 영역에서 조명 변화에 따른 복잡한 열화(degradation)를 구분하는 데 어려움을 겪습니다 [Figure 1]. 저자들은 depth, luminance, semantic cues가 저조도 환경에서도 안정적인 지각 정보를 제공한다는 점에 착안하여, 이러한 auxiliary modalities를 통합한 더 고도화된 프레임워크가 필요하다고 주장합니다.
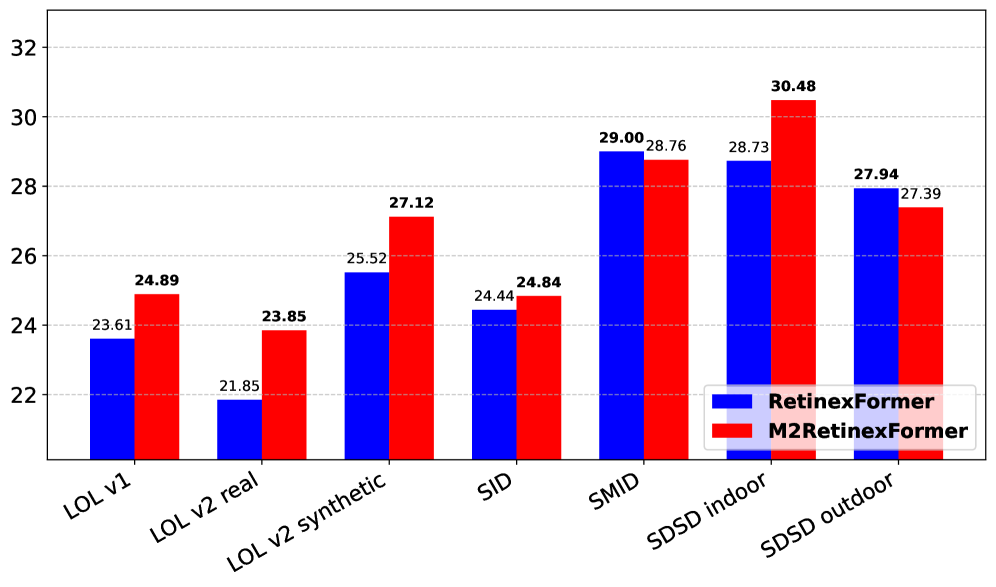
Figure 1 — PSNR 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 제안하는 M2Retinexformer를 통해 auxiliary modalities를 추출하고, MMCAB를 활용하여 이를 체계적으로 융합하는 Multi-modal restoration 파이프라인을 구축합니다 [Figure 3]. Modality Extractor는 Depth-Anything-V2를 통해 기하학적 구조를, DINOv3를 통해 semantic 정보를 추출하며, 이를 NTSC 기반의 luminance prior와 결합하여 네트워크에 주입합니다. 각 모듈은 Adaptive Gating을 통해 modality의 신뢰도를 실시간으로 평가하고, 이를 바탕으로 RGB self-attention과 cross-attention의 비중을 유연하게 조정합니다. 또한, 학습 시 기존 L1 loss에 VGG-19 기반의 Perceptual Loss를 추가하여 시각적 질감과 구조적 무결성을 보존합니다 [Figure 4]. 실험 결과, LOL-v1/v2, SID, SMID, SDSD 벤치마크에서 기존 Retinexformer 대비 높은 PSNR 및 SSIM 수치를 기록하며 state-of-the-art 성능을 달성하였습니다 [Table 1]. 특히, ablation study를 통해 depth 및 luminance 정보가 성능 향상에 가장 크게 기여함을 수치적으로 입증하였습니다 [Table 2].
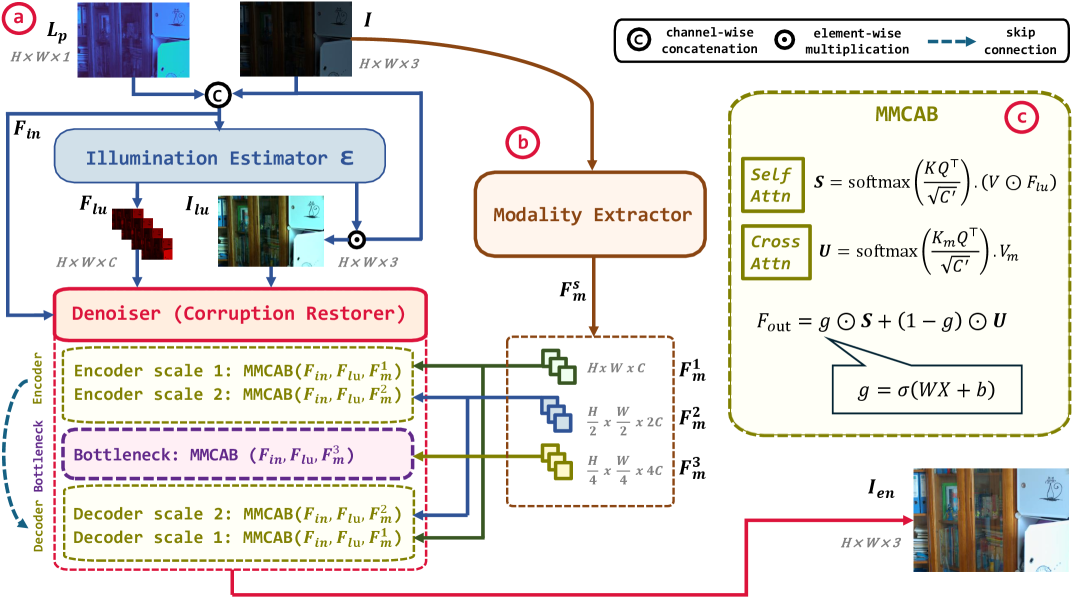
Figure 3 — 전체 아키텍처

Figure 4 — 시각적 복원 결과 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 다중 모달리티 융합을 통해 저조도 이미지 복원 성능을 비약적으로 개선한 M2Retinexformer를 성공적으로 제시하였습니다. 제안된 modular 디자인은 향후 추가적인 auxiliary priors를 쉽게 통합할 수 있는 확장성을 제공하며, 조명 변화에 강인한 복원 모델의 표준을 제시했다는 평가를 받습니다. 이 연구는 단순히 화질 개선을 넘어, 자율 주행이나 시각적 감지 작업 등 고수준의 이해가 필요한 하위 vision task의 신뢰도를 높이는 데 크게 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Cross-Attention is Half Explanation in Speech-to-Text Models
- [논문리뷰] Multi-View 3D Point Tracking
- [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
- [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
- [논문리뷰] Variable-Width Transformers
Review 의 다른글
- 이전글 [논문리뷰] Learning Agentic Policy from Action Guidance
- 현재글 : [논문리뷰] M2Retinexformer: Multi-Modal Retinexformer for Low-Light Image Enhancement
- 다음글 [논문리뷰] MAP: A Map-then-Act Paradigm for Long-Horizon Interactive Agent Reasoning
댓글