[논문리뷰] Learning Agentic Policy from Action Guidance
링크: 논문 PDF로 바로 열기
저자: Yuxiang Ji, Zengbin Wang, Yong Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic RL: LLM 기반 정책이 환경과의 상호작용을 통해 보상을 최대화하도록 최적화되는 강화학습 프레임워크입니다.
- Reachability Barrier: 정책의 탐색 능력이 부족하여 보상 상태(Reward State)에 도달하지 못하고 학습 신호가 소실되는 구조적 한계 구역입니다.
- Minimal Intervention Principle: 오프라인 데이터(action data)를 활용할 때, 보상을 복구할 수 있는 최소한의 가이드라인만 선택적으로 적용하여 distribution shift와 off-policy risk를 최소화하는 설계 원칙입니다.
- Mixed-Policy Optimization: 가이드가 포함된 Rollout과 포함되지 않은 Rollout을 혼합하여 학습함으로써, 탐색 과정에서 얻은 지식을 기본 정책으로 내재화(Internalize)하는 학습 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Agentic RL에서 기반 모델의 탐색 능력이 부족할 때 발생하는 학습 정체 문제를 해결하고자 합니다. 기존의 Agentic RL은 보상 상태가 모델의 'In-capability region'을 벗어난 경우, 유효한 학습 신호를 얻지 못해 훈련이 중단되는 구조적 한계를 가집니다 [Figure 1]. 이러한 문제를 극복하기 위해 기존 연구들은 주로 Supervised Fine-Tuning(SFT)을 통한 Cold-start나 복잡한 커리큘럼 학습에 의존해왔으나, 이는 데이터 준비 비용이 높고 확장에 한계가 있습니다. 따라서 본 연구는 대규모로 존재하는 일상적인 Action 데이터를 활용하여 이러한 탐색 장벽을 효율적으로 극복하는 새로운 프레임워크를 제안합니다.
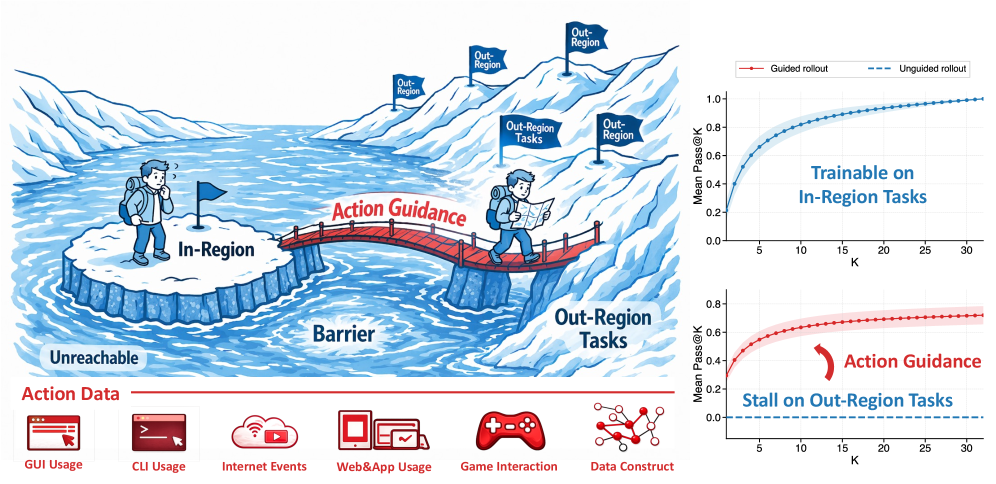
Figure 1 — 탐색 장벽과 가이드 효과
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Action 데이터를 Plan-style Reference Guidance로 주입하여 정책이 탐색 장벽을 넘도록 돕는 ActGuide-RL 프레임워크를 제안합니다 [Figure 2]. 저자들은 Action 데이터가 실제로 탐색 장벽을 복구할 수 있음을 입증하고 [Figure 3], 가이드 수준이 높을수록 Off-policy risk가 증가한다는 점을 분석하여 [Figure 4], 보상 복구를 위한 '최소 개입' 수준을 동적으로 찾는 메커니즘을 설계하였습니다. 학습 시에는 가이드가 적용된 Rollout과 그렇지 않은 Rollout을 혼합하여 Mixed-policy optimization을 수행함으로써, 최종적으로 가이드 없이도 복잡한 작업을 수행할 수 있도록 내재화합니다. 실험 결과, Qwen3-4B-Instruct 모델 기준 GAIA 벤치마크에서 기존 RL 대비 +10.68 pp, XBench에서 +19.00 pp의 성능 향상을 달성하였습니다 [Table 1]. 또한, ActGuide-RL은 별도의 SFT Cold-start 없이도 기존 SFT+RL 파이프라인과 동등한 성능을 보이며, SFT 데이터에 대한 높은 의존성을 성공적으로 완화하였습니다 [Table 2].
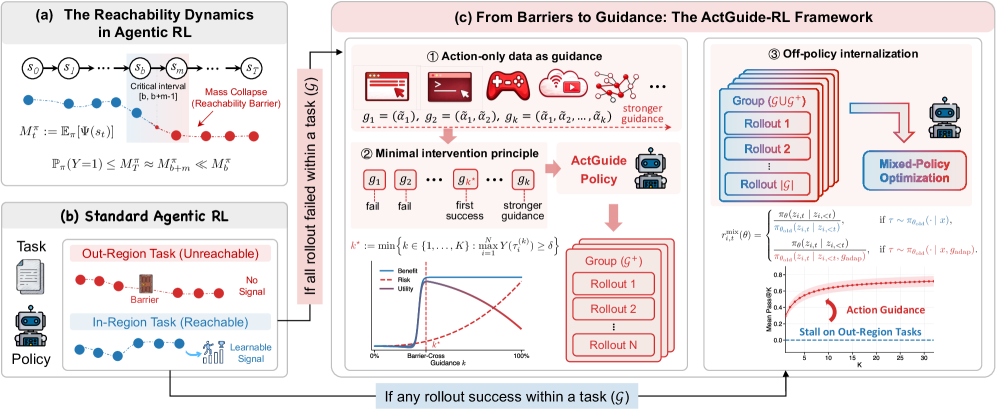
Figure 2 — ActGuide-RL 프레임워크
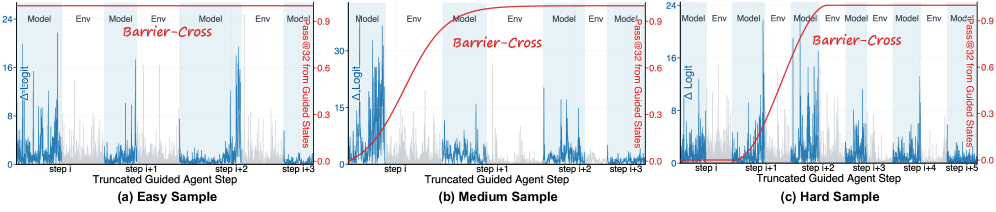
Figure 3 — 장벽 복구 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 대규모 Action 데이터를 활용한 ActGuide-RL 프레임워크를 통해 Agentic RL의 탐색 장벽 문제를 효과적으로 해결하였습니다. 최소 개입 원칙과 Mixed-policy optimization을 통해 가이드 지식을 모델에 효율적으로 내재화함으로써, SFT 없이도 고성능 에이전트 학습이 가능함을 입증했습니다. 이 연구는 고비용의 SFT 데이터 의존도를 낮추고, 일반적인 Action Trace만으로도 복잡한 에이전트 성능을 확장할 수 있는 새로운 post-training 패러다임을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
- [논문리뷰] APPO: Agentic Procedural Policy Optimization
- [논문리뷰] EvoDS: Self-Evolving Autonomous Data Science Agent with Skill Learning and Context Management
- [논문리뷰] Skill0.5: Joint Skill Internalization and Utilization for Out-of-Distribution Generalization in Agentic Reinforcement Learning
- [논문리뷰] EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL
Review 의 다른글
- 이전글 [논문리뷰] HAGE: Harnessing Agentic Memory via RL-Driven Weighted Graph Evolution
- 현재글 : [논문리뷰] Learning Agentic Policy from Action Guidance
- 다음글 [논문리뷰] M2Retinexformer: Multi-Modal Retinexformer for Low-Light Image Enhancement
댓글