[논문리뷰] Self-Distilled Agentic Reinforcement Learning
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Zhengxi Lu, Zhiyuan Yao, Zhuowen Han, Zi-Han Wang, Jinyang Wu, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
1. Key Terms & Definitions (핵심 용어 및 정의)
- OPSD (On-Policy Self-Distillation): 학생 에이전트가 학습 시에만 접근 가능한 privileged context(기술 등)를 가진 교사 브랜치로부터 토큰 단위의 지도를 받아 스스로를 개선하는 학습 기법입니다.
- SDAR (Self-Distilled Agentic Reinforcement Learning): RL을 기본 최적화 백본으로 유지하면서, OPSD를 게이팅 메커니즘을 통해 제어되는 보조 객체로 활용하여 다중 턴 에이전트의 안정적인 학습을 도모하는 제안 방법론입니다.
- Token-Level Gating: 학습 과정에서 토큰별로 교사 모델의 지도 강도를 동적으로 조절하는 기술로, 긍정적인 신호는 수용하고 불안정한 부정 신호는 억제합니다.
- GRPO (Group-in-group Policy Optimization): 환경 보상에 기반하여 시퀀스 단위의 Advantage를 계산하는 RL 최적화 기법으로, 본 연구의 메인 백본으로 사용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 다중 턴 에이전트 환경에서 기존 OPSD가 겪는 불안정성과 성능 저하 문제를 해결하고자 합니다. 기존 방식은 에이전트가 교사 지원 궤적에서 벗어날 때 토큰 단위의 지도가 신뢰성을 잃고, 교사의 privileged context에 대한 의존이 비대칭적인 결과를 초래하여 학습을 방해한다는 점을 지적합니다 [Figure 2]. 특히, 교사 모델이 생성한 부정적인 신호가 스킬 활용의 불안정성이나 에이전트의 다중 턴 이동(drift)으로 인해 발생하는 경우가 많아 이를 무비판적으로 수용할 경우 catastrophic degradation이 발생합니다 [Figure 3]. 이에 따라 저자들은 RL 최적화의 무결성을 유지하면서도 신뢰할 수 있는 교사 신호만을 선별적으로 추출하는 새로운 보조 최적화 방식의 필요성을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SDAR를 제안하여 OPSD 손실을 게이팅된 보조 목표로 다루고, verifier 기반의 GRPO 손실을 기본 최적화 백본으로 유지합니다 [Figure 4]. 이 프레임워크는 학습 중 각 토큰의 중요성을 결정하는 동적 Sigmoid Gate를 도입하여, 교사 모델이 긍정적으로 평가한(positive-gap) 토큰에 대해 distillation을 강화하고, 부정적인 신호는 소프트하게 감쇄시킵니다. 실험 결과, SDAR는 Qwen2.5 및 Qwen3 모델 시리즈에서 GRPO 대비 ALFWorld에서 +9.4%, Search-QA에서 +7.0%, WebShop-Acc에서 +10.2%의 성능 향상을 기록했습니다 [Table 1]. 특히, SDAR는 기술이 전혀 없는 환경에서도 스킬을 활용하는 baselines를 능가하는 우수한 일반화 성능을 보였으며, naïve GRPO+OPSD 방식이 겪는 불안정성을 완벽하게 방지했습니다. 또한, 학습 과정에서 게이트 활성화 비율이 훈련 초기에는 낮게 유지되다가 점진적으로 상승하는 것을 통해 동적 필터링의 효과를 입증했습니다 [Figure 5].
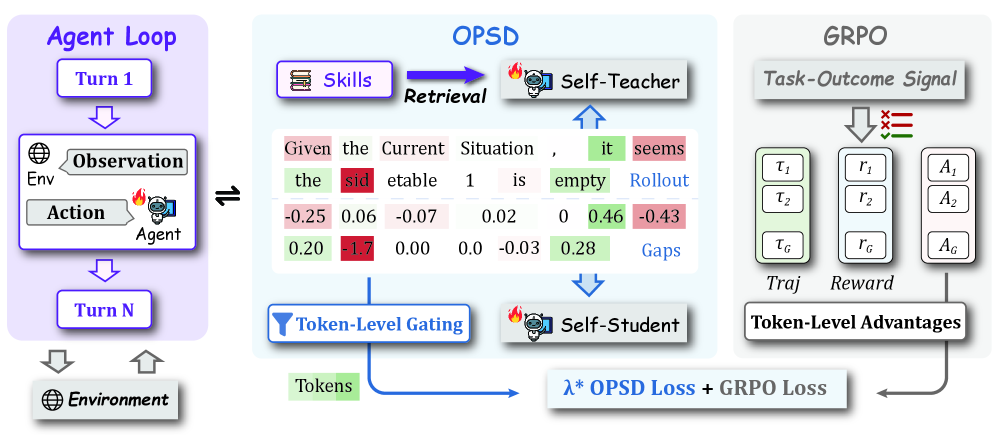
Figure 4 — SDAR 아키텍처
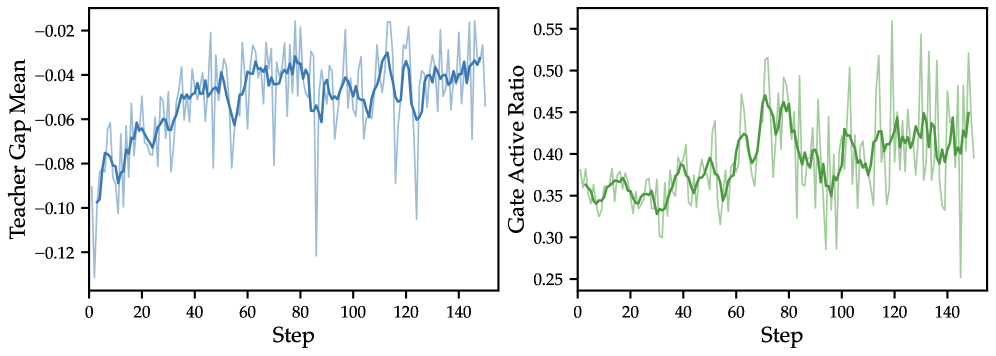
Figure 5 — 학습 역학 및 게이트 활성화
4. Conclusion & Impact (결론 및 시사점)
본 논문은 SDAR를 통해 강화학습과 자기 증류(self-distillation)를 다중 턴 에이전트 학습 과정에서 조화롭게 통합하는 강력한 프레임워크를 제시하였습니다. 각 토큰이 스스로의 지도 강도를 조절하도록 설계된 게이팅 메커니즘은 교사 모델의 불완전한 privileged guidance로부터 발생하는 노이즈를 효과적으로 차단합니다. 이 연구는 대규모 언어 모델 기반 에이전트의 포스트 트레이닝 과정에서 RL의 무결성을 훼손하지 않고도 densified token-level guidance를 안정적으로 이식할 수 있는 실용적인 해결책을 제공합니다. 이는 향후 복잡한 상호작용 환경에서 에이전트의 효율적인 스킬 내재화 및 일반화 성능 개선에 중요한 기술적 토대가 될 것으로 기대됩니다.
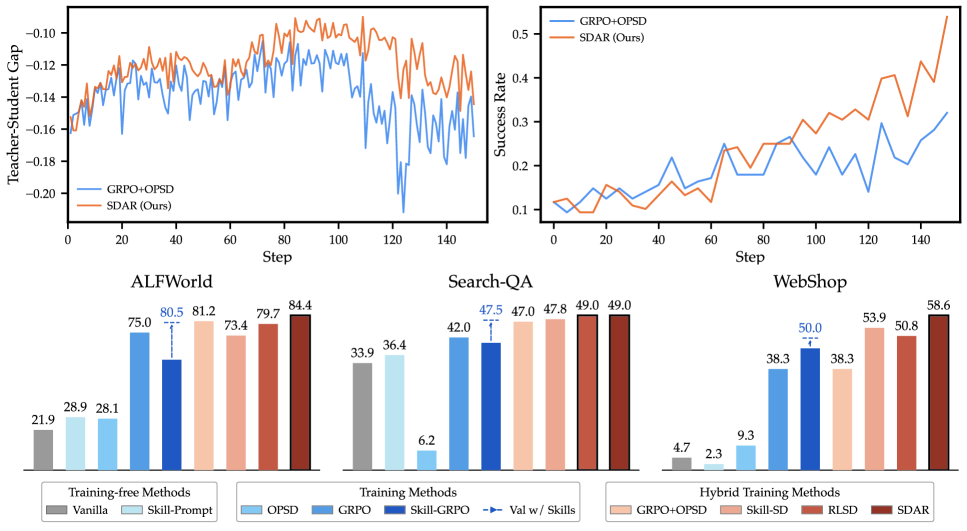
Figure 1 — GRPO+OPSD와 SDAR 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] dOPSD: On-Policy Self-Distillation for Diffusion Language Models
- [논문리뷰] Mastermind: Strategy-grounded Learning for Repository-Scale Vulnerability Reproduction
- [논문리뷰] Graph-Native Reinforcement Learning Enables Traceable Scientific Hypothesis Generation through Conceptual Recombination
Review 의 다른글
- 이전글 [논문리뷰] Sat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
- 현재글 : [논문리뷰] Self-Distilled Agentic Reinforcement Learning
- 다음글 [논문리뷰] Topology-Preserving Neural Operator Learning via Hodge Decomposition
댓글