[논문리뷰] Look Before You Leap: Autonomous Exploration for LLM Agents
링크: 논문 PDF로 바로 열기
저자: Ziang Ye, Wentao Shi, Yuxin Liu, Yu Wang, Zhengzhou Cai, Yaorui Shi, Qi Gu, Xunliang Cai, Fuli Feng
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 환경과의 상호작용을 통해 얻은 검증 가능한 보상 신호를 기반으로 에이전트의 정책을 최적화하는 학습 프레임워크입니다.
- ECC (Exploration Checkpoint Coverage): 에이전트가 환경 내에서 얼마나 넓은 범위의 핵심 상태(States), 객체(Objects), 및 행동 편의성(Affordances)을 발견했는지를 정량적으로 측정하는 검증 가능한 지표입니다.
- GRPO (Group Relative Policy Optimization): 환경 내에서 여러 개의 Rollout을 생성하고, 보상을 그룹 내에서 정규화하여 상대적 이점(Advantage)을 계산함으로써 정책을 업데이트하는 최적화 기법입니다.
- Explore-then-Act: 사전에 지정된 환경 상호작용 예산(Interaction Budget)을 활용해 정보를 수집한 뒤, 이를 지식 요약(Knowledge Summary) 형태로 변환하여 최종 태스크 수행에 활용하는 추론 패러다임입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 LLM 기반 에이전트가 새로운 환경에서 적응하지 못하고 조기 착취(Premature Exploitation) 문제에 빠지는 현상을 해결하고자 합니다. 기존의 RLVR 기반 학습 방식은 오직 태스크 완료 보상만을 최적화하기 때문에, 에이전트가 미지의 환경을 체계적으로 탐색하는 능력보다는 훈련 데이터의 Prior에 의존하게 됩니다 [Figure 1]. 이러한 경직된 행동 패턴은 에이전트가 새로운 도구 사용이나 미지의 환경 제약 조건을 파악하지 못하게 만들어 성능 저하를 초래합니다. 결과적으로, 에이전트가 환경에 대한 이해 없이 태스크를 수행하려 시도하는 비효율적인 상황이 빈번하게 발생합니다.
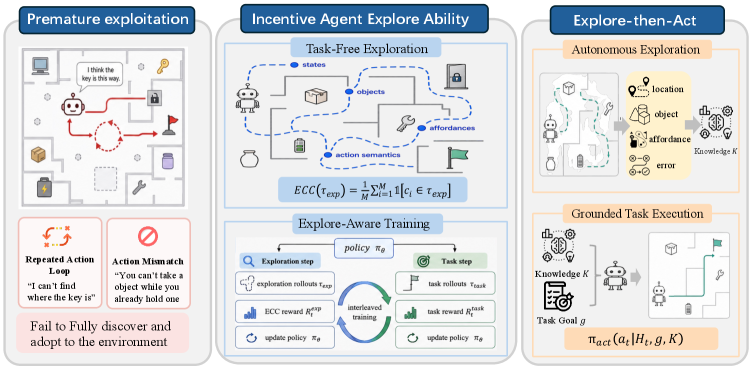
Figure 1 — 제안 모델의 전체 아키텍처 및 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 ECC를 활용하여 에이전트의 탐색 능력을 독립적인 학습 목표로 정의하고, Interleaved Training Schedule을 통해 탐색(Exploration)과 태스크 수행(Task Execution)을 통합하는 최적화 전략을 제안합니다 [Figure 2]. 저자들은 GRPO를 활용하여 에이전트가 환경 내의 다양한 상태를 발견할 때 ECC 보상을 제공함으로써, 탐색 성능과 태스크 수행 성능을 동시에 향상시킵니다 [Table 2]. 실험 결과, 탐색 지향적 학습을 거친 에이전트는 일반적인 태스크 지향 모델 대비 정보 탐색 능력이 강화되었으며, 환경이 변경되거나 미지의 객체가 등장하는 환경 변형 환경(Perturbed Variants)에서도 더 높은 강건함(Robustness)을 보입니다 [Figure 3]. ECC 기반의 탐색은 에이전트가 예산(Budget)을 효율적으로 사용하여 더 높은 ΔTask 수치를 달성하게 하며, 이는 Explore-then-Act 패러다임의 유효성을 정량적으로 입증합니다 [Figure 4].
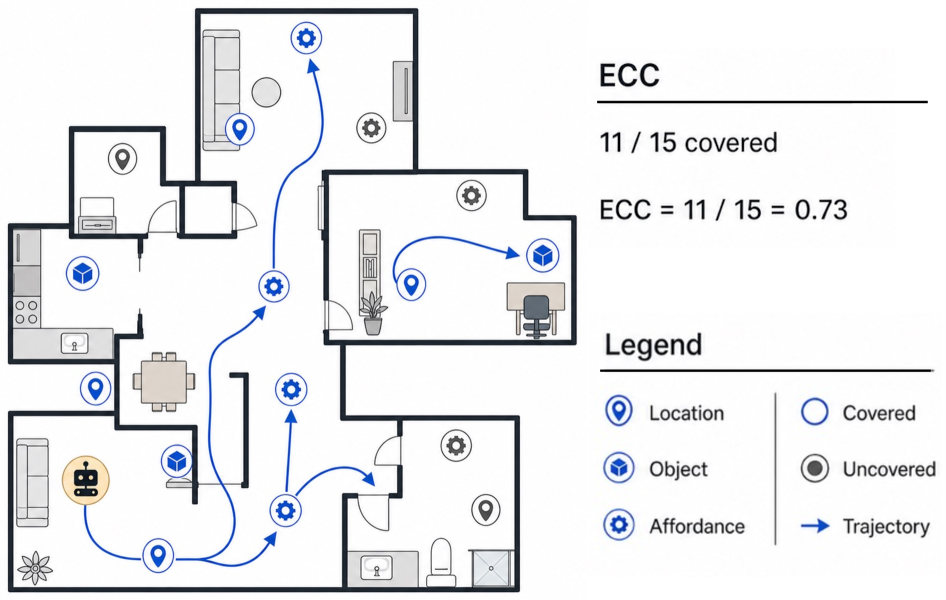
Figure 2 — ECC 계산 개념도
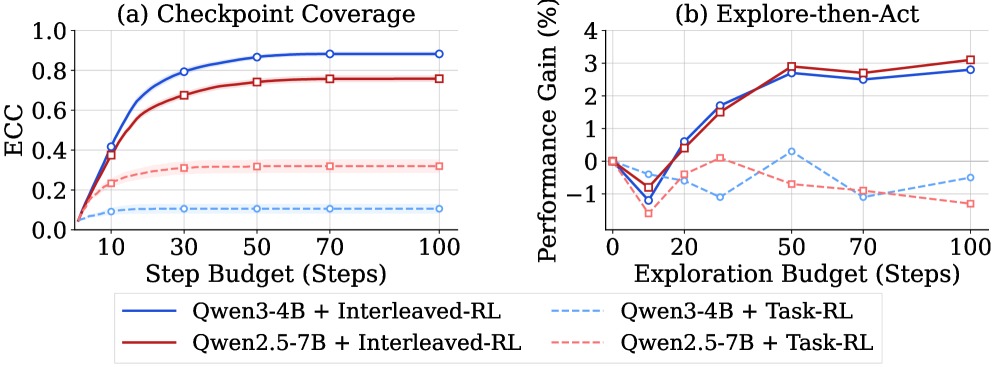
Figure 4 — 탐색 효율과 태스크 성능 간의 관계
4. Conclusion & Impact (결론 및 시사점)
본 논문은 autonomous exploration이 LLM 에이전트의 적응성과 일반화 성능을 결정짓는 핵심적인 메타 능력임을 밝혀냈습니다. 제안된 ECC 지표와 Interleaved GRPO 학습 전략은 에이전트가 환경의 제약 조건을 능동적으로 학습하게 함으로써, 고정된 환경을 넘어 실세계의 동적이고 복잡한 시나리오에 대응할 수 있는 기초를 마련했습니다. 이 연구는 단순히 더 나은 태스크 수행을 넘어, 자율 에이전트가 스스로 환경을 파악하고 적응하는 능력을 배양함으로써 범용적 AI 에이전트 개발의 새로운 이정표를 제시할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Mastermind: Strategy-grounded Learning for Repository-Scale Vulnerability Reproduction
- [논문리뷰] MemTrain: Self-Supervised Context Memory Training
- [논문리뷰] Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing
- [논문리뷰] Agentic Critical Training
- [논문리뷰] Reinforcement Learning for Self-Improving Agent with Skill Library
Review 의 다른글
- 이전글 [논문리뷰] Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
- 현재글 : [논문리뷰] Look Before You Leap: Autonomous Exploration for LLM Agents
- 다음글 [논문리뷰] MMSkills: Towards Multimodal Skills for General Visual Agents
댓글