[논문리뷰] Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
링크: 논문 PDF로 바로 열기
저자: Yuchen Cai, Ding Cao, Liang Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- On-Policy Distillation (OPD): 학생 모델이 스스로 생성한 trajectory를 바탕으로 교사 모델의 출력을 모방하여 학습하는 효율적인 post-training 패러다임입니다.
- Functional Redundancy Avoidance: 학습 과정에서 marginal utility가 낮은 모듈의 파라미터 업데이트를 억제하고, 추론 성능에 중요한 중간 레이어에 집중하는 OPD의 모듈 레벨 특성입니다.
- Early Low-Rank Lock-in: OPD가 학습 초기 단계에서부터 최종 모델의 업데이트 subspace와 일치하는 안정적인 업데이트 방향을 형성하는 기하학적 특성입니다.
- EffOPD: OPD의 초기 업데이트 방향 안정성을 활용하여, 가용한 현재 업데이트 방향을 따라 선형 extrapolation을 수행함으로써 학습 속도를 가속화하는 plug-and-play 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 언어 모델(LLM)의 post-training에서 OPD가 RL보다 높은 효율성을 보이는 근본적인 파라미터 업데이트 메커니즘을 규명하고자 합니다. 기존 연구들은 OPD의 이점을 단순히 더 밀도 높고 안정적인 supervision 덕분으로 설명하지만, 이는 거시적인 관점일 뿐 내부의 구체적인 파라미터 dynamics를 설명하지 못합니다. 저자들은 OPD가 학습 초기부터 최종 모델을 향한 안정적인 업데이트 궤적을 형성하는 일종의 'foresight(선견지명)'를 갖추고 있음을 주장하며, 이를 통해 효율적이고 콤팩트한 업데이트가 가능함을 입증합니다 [Figure 1].
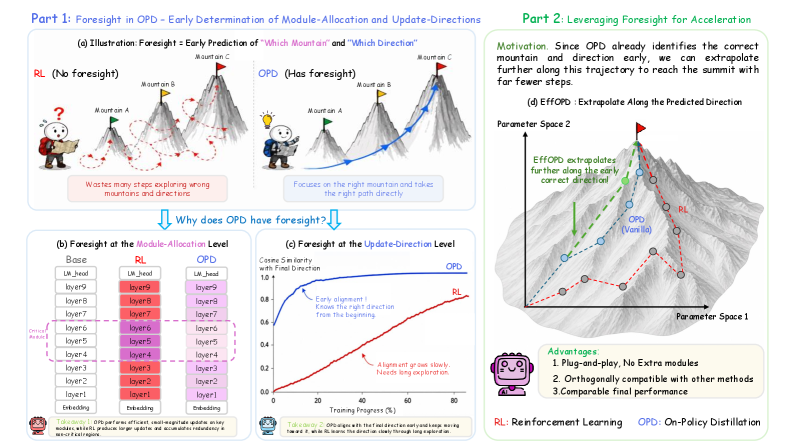
Figure 1 — OPD의 foresight 메커니즘과 EffOPD 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 OPD의 효율성을 설명하는 두 가지 핵심 속성을 정의하고, 이를 기반으로 EffOPD를 제안합니다. 첫째, Functional Redundancy Avoidance를 통해 OPD는 전체 레이어에 걸쳐 업데이트를 분산하는 RL과 달리, 추론에 기여도가 높은 중간 레이어의 MLP 모듈에 업데이트를 집중시킵니다 [Figure 3]. 둘째, Early Low-Rank Lock-in을 통해 OPD는 학습 초기부터 dominant 업데이트 subspace를 결정하고 이를 고정하여 유지하며, 이후 학습은 이 방향으로의 magnitude를 증대시키는 방향으로 진행됩니다 [Figure 5]. 이러한 분석을 바탕으로, 학습 과정 중 exponentially spaced checkpoint에서 업데이트 방향을 근사하고 검증을 통해 extrapolation step size를 적응적으로 선택하는 EffOPD를 설계하였습니다. 실험 결과, EffOPD는 1.5B부터 32B 파라미터 모델까지 다양한 규모에서 별도의 추가 모듈 없이도 평균 3x 학습 가속을 달성하면서도 vanilla OPD와 대등한 최종 성능을 유지함을 입증하였습니다 [Figure 6].
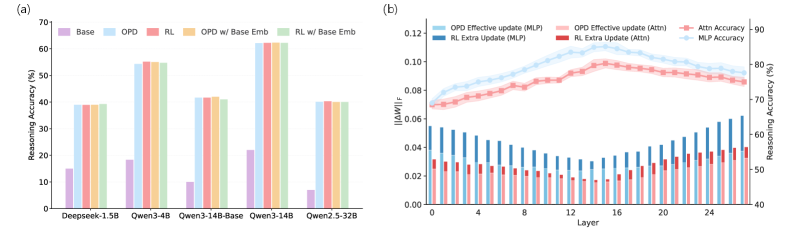
Figure 3 — 아키텍처 구성 요소별 업데이트 분포 분석
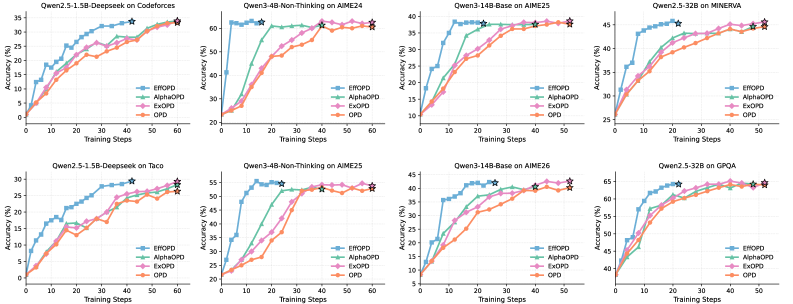
Figure 6 — 다양한 데이터셋에서의 성능 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 OPD의 훈련 효율성이 모듈 레벨의 redundancy 억제와 업데이트 방향의 조기 안정화(foresight)에서 기인함을 파라미터 dynamics 측면에서 최초로 규명하였습니다. 제안된 EffOPD는 복잡한 하이퍼파라미터 튜닝 없이도 OPD의 학습 과정을 효과적으로 가속화하는 실용적인 솔루션을 제공합니다. 이 연구는 LLM post-training 패러다임의 이해를 심화하고, 향후 더욱 효율적이고 해석 가능한 모델 최적화 기법을 설계하는 데 중요한 이론적 토대를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Holistic Data Scheduler for LLM Pre-training via Multi-Objective Reinforcement Learning
- [논문리뷰] OPRD: On-Policy Representation Distillation
- [논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
- [논문리뷰] A Survey of On-Policy Distillation for Large Language Models
- [논문리뷰] On Predictability of Reinforcement Learning Dynamics for Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Learning from Failures: Correction-Oriented Policy Optimization with Verifiable Rewards
- 현재글 : [논문리뷰] Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
- 다음글 [논문리뷰] Look Before You Leap: Autonomous Exploration for LLM Agents
댓글