[논문리뷰] Learning from Failures: Correction-Oriented Policy Optimization with Verifiable Rewards
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mengjie Ren, Jie Lou, Boxi Cao, Xueru Wen, Hongyu Lin, Xianpei Han, Le Sun, Xing Yu, Yaojie Lu
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 자동 검증 가능한 환경 피드백을 통해 LLM의 추론 능력을 향상시키는 강화학습 패러다임입니다.
- GRPO (Group Relative Policy Optimization): 환경 피드백의 불확실성을 완화하기 위해 그룹 내 상대적 이점을 사용하여 정책을 최적화하는 효율적인 RLVR 알고리즘입니다.
- CIPO (Correction-Oriented Policy Optimization): 실패한 trajectories를 단순한 penalty 대상으로 보지 않고, 모델의 오류를 스스로 교정하도록 유도하여 학습 신호로 전환하는 본 연구의 핵심 프레임워크입니다.
- Adaptive Replay: 실패 및 성공한 trajectories의 비율을 학습 상황에 맞춰 동적으로 조절하여 정책의 안정적인 수렴을 유도하는 메커니즘입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존 RLVR 패러다임이 가진 sparse binary reward와 weak credit assignment 문제를 해결하여 모델의 추론 능력을 극대화하는 것을 목적으로 합니다. 기존의 reinforce–suppress 방식은 실패한 trajectories를 단순히 일괄적으로 페널티를 부여함으로써, 그 안에 내재된 부분적인 추론 정보나 오류의 원인을 활용하지 못하는 한계가 있습니다 [Figure 1]. 이러한 방식은 복잡한 다단계 추론 과정에서 모델에게 모호한 최적화 신호를 제공하며, 결과적으로 모델의 내재적 reasoning capacity 향상을 저해합니다. 따라서 외부의 추가적인 레이블링 없이도 실패한 경험으로부터 명확한 방향성(directional guidance)을 추출할 수 있는 효율적인 학습 전략이 필요합니다.

Figure 1 — 기존 RLVR과 CIPO 비교
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구가 제안하는 CIPO는 실패한 trajectories를 활용해 모델이 스스로 오류를 교정하도록 하는 Correction Stream을 기존의 Base Stream과 결합하여 공동 최적화합니다 [Figure 2]. 저자들은 실패한 rollouts을 활용한 리플레이 데이터 생성 시 Adaptive Replay와 risk-averse reward shaping을 도입하여 capability regression을 방지하고 안정적인 학습을 보장합니다. 특히, 모델의 최근 retention 성능을 바탕으로 successful/failed 샘플의 비율을 동적으로 조절함으로써 Exploration과 Exploitation 사이의 균형을 유지합니다. 실험 결과, Qwen3-4B 및 Seed-Coder-8B를 사용한 테스트에서 CIPO는 여러 수학 및 코딩 벤치마크에서 기존 GRPO 대비 높은 성능 향상을 보였습니다. 구체적으로, 수학적 추론 과제에서 평균 정확도가 17.56% 개선되었으며, GRPO와 비교해도 평균 4.55%의 추가적인 성능 우위를 점했습니다 [Table 1]. 또한, pass@K 지표에서의 높은 성취도는 단순 확률 재분배를 넘어 모델의 내재적 reasoning capacity가 실질적으로 확장되었음을 입증합니다 [Table 2].
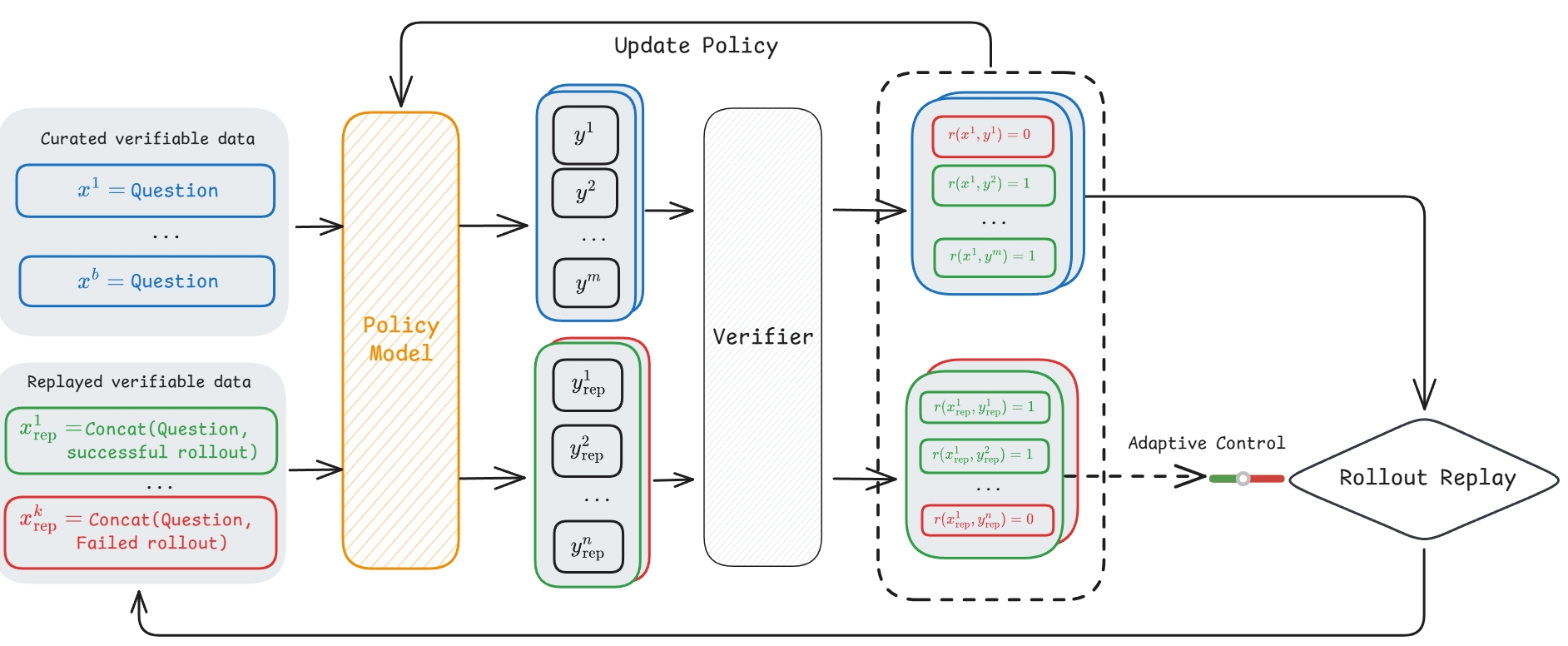
Figure 2 — CIPO 전체 프레임워크
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 실패 경험을 학습 신호로 변환하는 CIPO를 통해 RLVR의 효율성을 획기적으로 개선하였습니다. 이 연구는 모델이 스스로 오류 모드를 학습하고 교정할 수 있게 함으로써, 추가적인 인간 레이블링 없이도 고도화된 추론 및 디버깅 능력을 확보할 수 있음을 보여줍니다. 제시된 방법론은 다양한 LLM 기반 추론 시스템의 일반적인 확장성을 보장하며, 복잡한 reasoning 과제 수행 시 모델의 신뢰성을 크게 향상시킬 수 있는 실용적인 프레임워크로 기능할 것으로 기대됩니다.
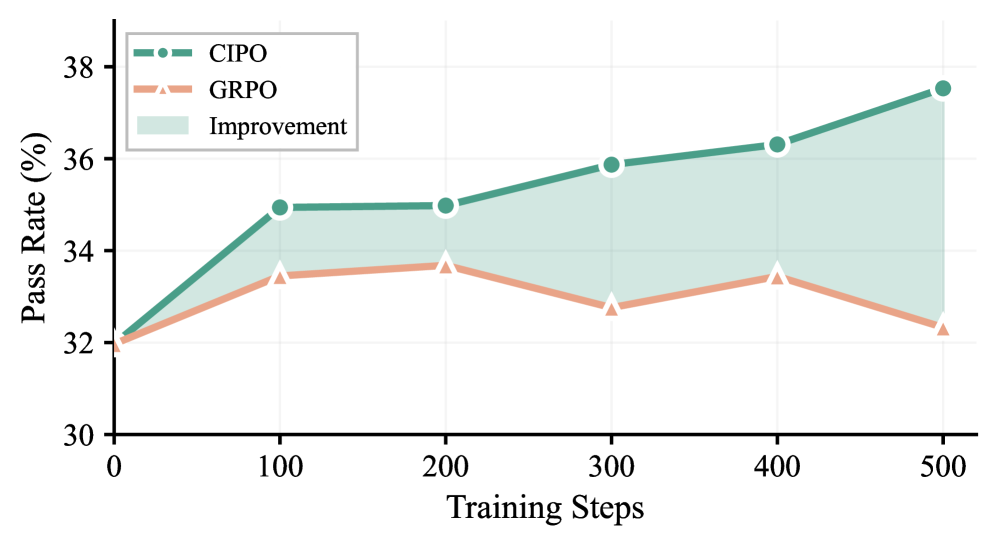
Figure 3 — LiveCodeBench 학습 동적 변화
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Cooper: Co-Optimizing Policy and Reward Models in Reinforcement Learning for Large Language Models
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] Decoupling Reasoning and Confidence: Resurrecting Calibration in Reinforcement Learning from Verifiable Rewards
Review 의 다른글
- 이전글 [논문리뷰] Learning POMDP World Models from Observations with Language-Model Priors
- 현재글 : [논문리뷰] Learning from Failures: Correction-Oriented Policy Optimization with Verifiable Rewards
- 다음글 [논문리뷰] Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
댓글