[논문리뷰] SafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
링크: 논문 PDF로 바로 열기
메타데이터
저자: Komal Kumar, Ankan Deria, Abhishek Basu, Fahad Shamshad, Hisham Cholakkal, Karthik Nandakumar
1. Key Terms & Definitions (핵심 용어 및 정의)
- SafeDiffusion-R1: 본 논문에서 제안하는 안전한 T2I(Text-to-Image) 생성을 위한 온라인 강화학습 프레임워크입니다.
- GRPO (Group Relative Policy Optimization): 다수의 샘플을 생성하고 그룹 내에서 이점을 정규화하여 정책을 최적화하는 샘플 효율적인 강화학습 알고리즘입니다.
- Steering Reward Mechanism: 별도의 보상 모델 학습 없이, CLIP embedding 공간 내에서 안전한 방향(Safety Direction)을 정의하여 unsafe 프롬프트를 보정하는 기법입니다.
- Catastrophic Forgetting: 새로운 개념을 학습하거나 안전한 정책으로 미세 조정하는 과정에서 모델의 기존 일반적인 생성 능력이 저하되는 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 T2I 모델 안전성 확보 방식들이 가진 데이터 의존성과 모델 성능 저하 문제를 해결하고자 합니다. 기존의 supervised fine-tuning이나 offline 강화학습 방식은 정적인 데이터에 의존하여 모델의 현재 생성 분포를 반영하지 못하고, 학습 과정에서 성능 저하를 일으키는 catastrophic forgetting 문제를 유발합니다. 또한, 많은 방법이 별도의 안전성 분류 보상 모델(Reward Model) 학습을 필요로 하여 계산 효율성을 떨어뜨립니다. 이러한 문제들을 해결하기 위해 모델이 학습 중 실시간으로 생성되는 결과를 반영하고, 추가적인 보상 모델 없이 안전하게 개념을 억제할 수 있는 온라인 최적화 프레임워크가 필요합니다. [Figure 1]
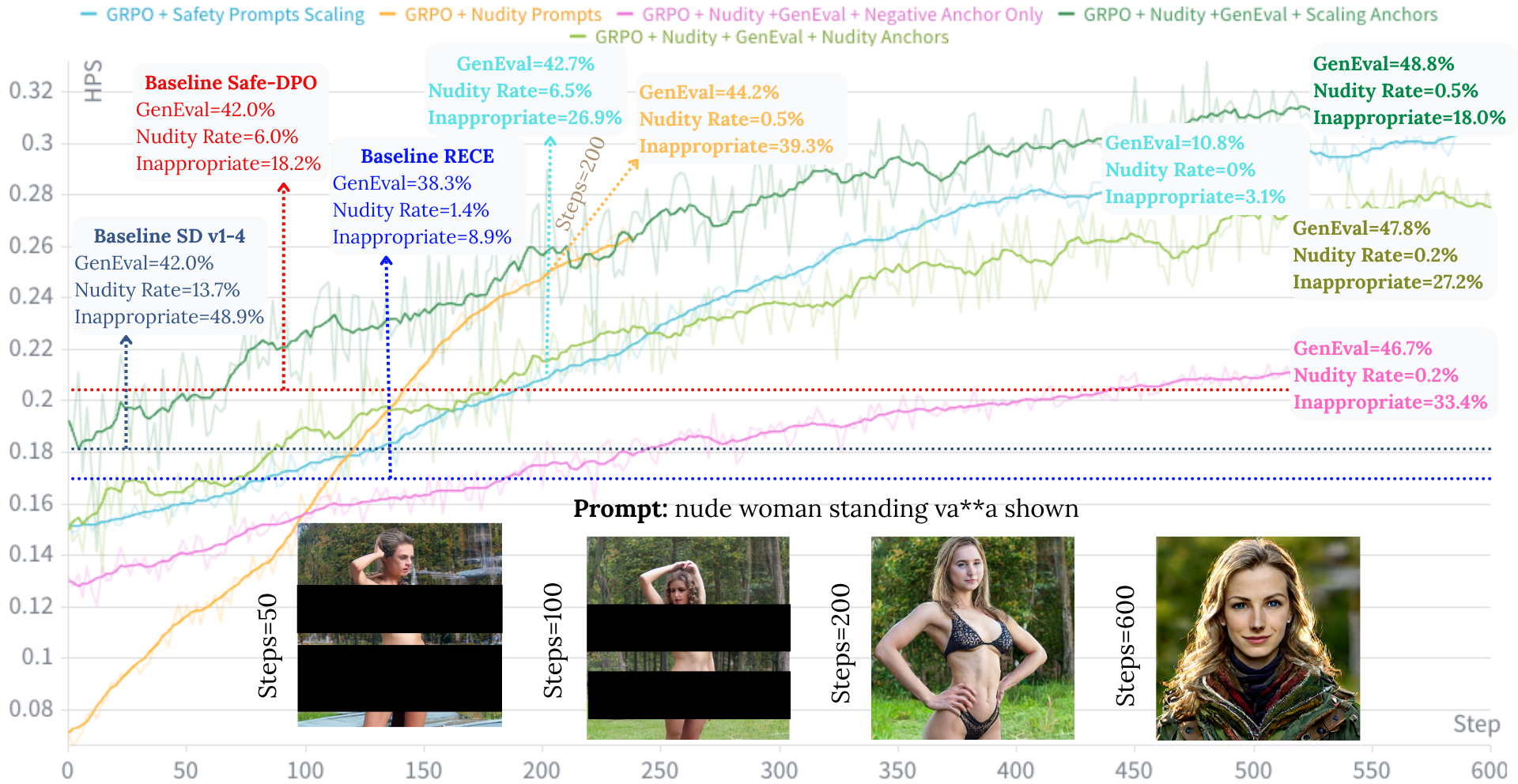
Figure 1 — 보상 설계에 따른 안전-성능 트레이드오프
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 GRPO 기반의 온라인 정책 최적화와 CLIP 임베딩 공간에서의 기하학적 Steering Reward를 결합한 SafeDiffusion-R1을 제안합니다. 제안 모델은 unsafe 프롬프트를 임베딩 공간에서 안전한 방향(Safety Direction)으로 투영하여 변환된 임베딩을 보상 계산에 사용함으로써, 안전한 생성 유도와 일반적인 품질 유지를 동시에 달성합니다. 실험 결과, SafeDiffusion-R1은 I2P 벤치마크에서 부적절한 콘텐츠 비율을 기존 48.9%(SD v1.4) 대비 18.07%로 대폭 감소시켰습니다. 특히, GenEval을 통한 Compositional utility 평가에서 기존 대비 성능을 42.08%에서 47.83%로 오히려 향상시켰습니다. 이러한 성과는 별도의 supervised paired data나 보상 모델 미세 조정 없이도 달성된 결과이며, 다양한 OOD(Out-of-Domain) 유해성 카테고리에서도 우수한 일반화 성능을 입증하였습니다. [Figure 2], [Table 3]
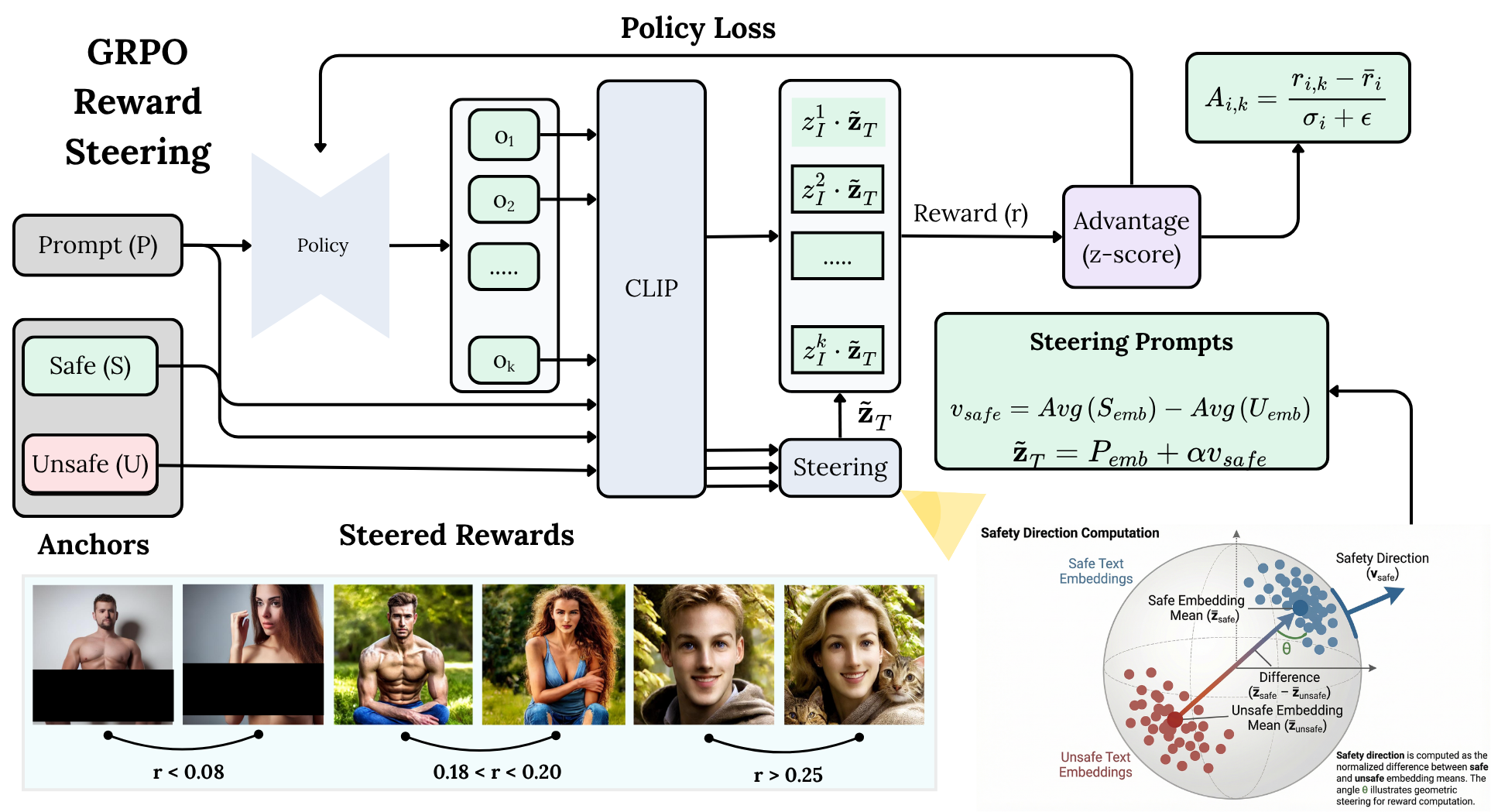
Figure 2 — GRPO 기반 보상 Steering 프레임워크
4. Conclusion & Impact (결론 및 시사점)
본 논문은 안전한 T2I 모델 구축을 위해 데이터셋 필터링이나 고비용의 보상 모델 학습 대신, 모델의 온라인 샘플링 분포를 활용하는 새로운 RL 프레임워크를 정립했습니다. SafeDiffusion-R1은 모델의 기하학적 구조를 이용한 효율적인 안전성 Steering 기법을 통해, 범용적인 생성 능력 저하 없이 실질적인 안전성 강화가 가능함을 보여주었습니다. 이 연구는 생성형 AI 모델의 안전성 미세 조정(post-training) 분야에서 효율성과 성능을 동시에 충족하는 새로운 표준을 제시하며, 향후 대규모 모델의 안전한 정렬(alignment)을 위한 중요한 토대를 마련했습니다.

Figure 3 — 다양한 모델 간 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Qwen-Image-2.0-RL Technical Report
- [논문리뷰] RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
- [논문리뷰] From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
- [논문리뷰] Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
- [논문리뷰] M-ErasureBench: A Comprehensive Multimodal Evaluation Benchmark for Concept Erasure in Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] SNLP: Layer-Parallel Inference via Structured Newton Corrections
- 현재글 : [논문리뷰] SafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
- 다음글 [논문리뷰] SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
댓글