[논문리뷰] From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
링크: 논문 PDF로 바로 열기
저자: Jiazi Bu, Pengyang Ling, Yujie Zhou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRPO (Group Relative Policy Optimization) : 주어진 조건(예: 텍스트 프롬프트)하에 생성된 샘플 그룹의 평균 대비 각 샘플의 상대적 Advantage를 효율적으로 추정하여 Policy를 최적화하는 Reinforcement Learning 프레임워크입니다.
- MV-GRPO (Multi-View Group Relative Policy Optimization) : 기존 GRPO의 Sparse Single-View Evaluation Scheme의 한계를 극복하기 위해 Condition Space를 확장하여 Dense Multi-View Reward Mapping을 가능하게 하는 새로운 Reinforcement Learning 프레임워크입니다.
- Condition Enhancer : Original Condition을 기반으로 Semantically Adjacent하지만 Diverse한 Augmented Conditions Cluster를 생성하여 Reward Evaluation을 다각화하는 MV-GRPO의 핵심 모듈입니다. 이는 Online VLM Enhancer 와 Offline LLM Enhancer 두 가지 구현 방식을 가집니다.
- Flow Models : Stochastic Diffusion Path를 시뮬레이션하는 대신, Noise 분포와 Data 분포 사이의 Straight Line을 따라 움직이는 Continuous-Time Velocity Field를 직접 학습하여 높은 충실도의 Visual Content를 생성하는 Generative Model입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Diffusion/Flow Models은 Visual Content 생성에서 혁신적인 능력을 보여주고 있지만, 생성된 Outputs이 Human Preference 및 Task-specific Constraint에 Align되도록 하는 것은 여전히 중요한 과제입니다. Reinforcement Learning 기반의 Post-training Paradigm, 특히 GRPO 는 이러한 Preference Alignment에 효과적임이 입증되었습니다. 그러나 기존 방법론들은 Reward Estimation 시 "Single-View" Paradigm에 의존하여, 단일 초기 Condition에 대해 생성된 Sample Group만을 평가합니다 [Figure 2a]. 이러한 Sparse Single-View Evaluation Scheme은 Inter-Sample Relationship에 대한 Exploration이 불충분하여 Alignment Efficacy와 Performance Ceilings에 제약을 가하며, Visual Semantics의 Multi-faceted Nature를 충분히 반영하지 못하는 문제가 있습니다. 결과적으로, 단일 프롬프트에만 의존한 Sample Ranking은 Nuanced Relationship을 포착하지 못하는 Sparse Reward Mapping으로 이어집니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 기존 Flow-based GRPO의 Sparse Single-View Reward Evaluation Scheme을 해결하기 위해 MV-GRPO 를 제안합니다. MV-GRPO 는 Flexible Condition Enhancer 모듈을 도입하여 Original Condition 주변에 Semantically Adjacent하지만 Diverse한 Augmented Conditions Cluster를 Sample함으로써 Condition Space를 확장합니다 [Figure 2b, Figure 4]. 이 Augmented Conditions는 기존 Generated Samples의 Probabilities를 새로운 Conditions 하에서 재평가하는 데 사용되며, Costly Sample Regeneration 없이 Dense Multi-View Reward Mapping을 통해 Multi-View Optimization을 가능하게 합니다. Online VLM Enhancer 는 생성된 샘플의 Visual Semantics를 동적으로 포착하고, Offline LLM Enhancer 는 Textual Semantics를 기반으로 Prior Descriptor를 샘플링합니다.
실험 결과, MV-GRPO 는 Single Reward 및 Multi-Reward 설정 모두에서 기존 Baseline 대비 일관된 우수성을 보였습니다
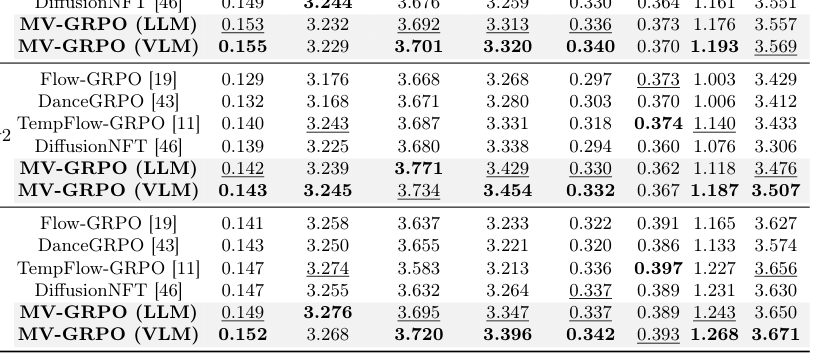 Table 1: Quantitative comparison of different methods.
Table 1: Quantitative comparison of different methods.
. 특히, Online VLM Enhancer 를 활용한 MV-GRPO (VLM) 는 HPS-v3 Score에서 0.155 를 기록하며 Baseline인 Flux.1-dev 의 0.133 보다 현저히 높은 성능을 보였고, ImageReward (IR) 에서도 1.193 로 가장 우수했습니다. 이는 MV-GRPO (VLM) 가 Sample-specific Posterior Captions를 생성하여 더 Discriminative한 Reward Signal을 제공하기 때문입니다. 또한, Training Latency 측면에서 MV-GRPO 는 동등한 양의 Data Augmentation을 적용하는 것보다 약 10배 적은 Overhead를 발생시키며 효율성을 입증했습니다 [Table 2]. Reward Curve [Figure 6]에서도 MV-GRPO 는 Baseline보다 Convergence Speed와 Performance Ceiling 모두에서 뛰어난 성능을 보였습니다. Ablation Study [Table 4]를 통해 Condition Number와 Diversity가 성능에 미치는 긍정적인 영향을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Flow-based GRPO의 Sparse Single-View Reward Evaluation Scheme이 Intra-Group Relationship Exploration 부족과 최적의 성능 달성 한계를 야기한다는 중요한 문제를 식별했습니다. 이를 해결하기 위해 MV-GRPO 는 Alignment 패러다임을 Dense Multi-View Supervision으로 전환하는 새로운 Reinforcement Learning 프레임워크를 제시합니다. Flexible Condition Enhancer 를 활용하여 Condition Space를 Semantically Diverse한 Descriptors로 확장함으로써, MV-GRPO 는 풍부한 Semantic Attribute를 포착하는 Dense Multi-View Reward Mapping을 가능하게 하고, Sample Regeneration Overhead 없이 포괄적인 Advantage Estimation을 제공합니다. MV-GRPO 는 다양한 Metrics에서 기존 최첨단 방법론 대비 뛰어난 성능을 입증함으로써 Generative Model의 Preference Alignment 연구에 새로운 방향을 제시하고, 더 높은 Visual Quality와 Generalization Capabilities를 가진 모델 개발에 중요한 기여를 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
- [논문리뷰] DenseGRPO: From Sparse to Dense Reward for Flow Matching Model Alignment
- [논문리뷰] Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
- [논문리뷰] TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
- [논문리뷰] Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
Review 의 다른글
- 이전글 [논문리뷰] ECoLAD: Deployment-Oriented Evaluation for Automotive Time-Series Anomaly Detection
- 현재글 : [논문리뷰] From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
- 다음글 [논문리뷰] HomeSafe-Bench: Evaluating Vision-Language Models on Unsafe Action Detection for Embodied Agents in Household Scenarios
댓글