[논문리뷰] ECoLAD: Deployment-Oriented Evaluation for Automotive Time-Series Anomaly Detection
링크: 논문 PDF로 바로 열기
저자: Kadir-Kaan Özer, René Ebeling, Markus Enzweiler
1. Key Terms & Definitions (핵심 용어 및 정의)
- ECOLAD (Efficiency Compute Ladder for Anomaly Detection) : Time-series anomaly detection(TSAD)을 위한 deployment-oriented evaluation protocol로, compute reduction, CPU parallelism caps 및 throughput feasibility를 명시적으로 다룹니다.
- CPU-1T tier : 단일 스레드(single-thread) CPU 실행을 의미하며, reduced parallelism에 대한 conservative stress test로, primary deployment-stress tier로 간주됩니다.
- Throughput (wps) : Windows per second를 나타내는 지표로,
N/t_inf(scored units N / inference-only time t_inf)으로 계산되어 scoring rate를 측정합니다. - Coverage : 특정 target throughput을 초과하는 throughput을 달성한 entities의 비율을 나타냅니다.
- AUC-PR : Area Under the Precision-Recall Curve로, 클래스 불균형이 있는 시나리오에서 anomaly detection 성능을 평가하는 데 사용되는 주요 detection quality metric입니다.
- Compute-reduction ladder : 계층별(tiered) scaling rules를 사용하여 모델 및 training workload를 단조롭게(monotonically) 감소시키는 ECOLAD 프로토콜의 핵심 요소입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Time-Series Anomaly Detection(TSAD) 연구들은 주로 workstation-class hardware에서 unconstrained execution 환경 하에 detection quality(주로 accuracy)만을 비교하고 최적화했습니다. 그러나 in-vehicle monitoring과 같은 실제 deployment 환경에서는 predictable latency 와 제한된 CPU parallelism 이 필수적입니다. 이러한 환경에서 compute budget 과 CPU parallelism 이 감소하는 embedded deployment는 기존 accuracy-only leaderboard가 실제 배포 가능한 method를 오인하게 만들 수 있습니다. 특히, runtime overheads (data movement, preprocessing, framework setup)가 가속화된 백엔드에서는 잘 드러나지 않아 method ranking이 크게 바뀔 수 있습니다. 이러한 한계점을 해결하기 위해, 본 연구는 deployment-relevant constraints 하에서 TSAD method의 feasibility와 성능 변화를 체계적으로 평가할 수 있는 새로운 evaluation protocol인 ECOLAD 를 제안합니다
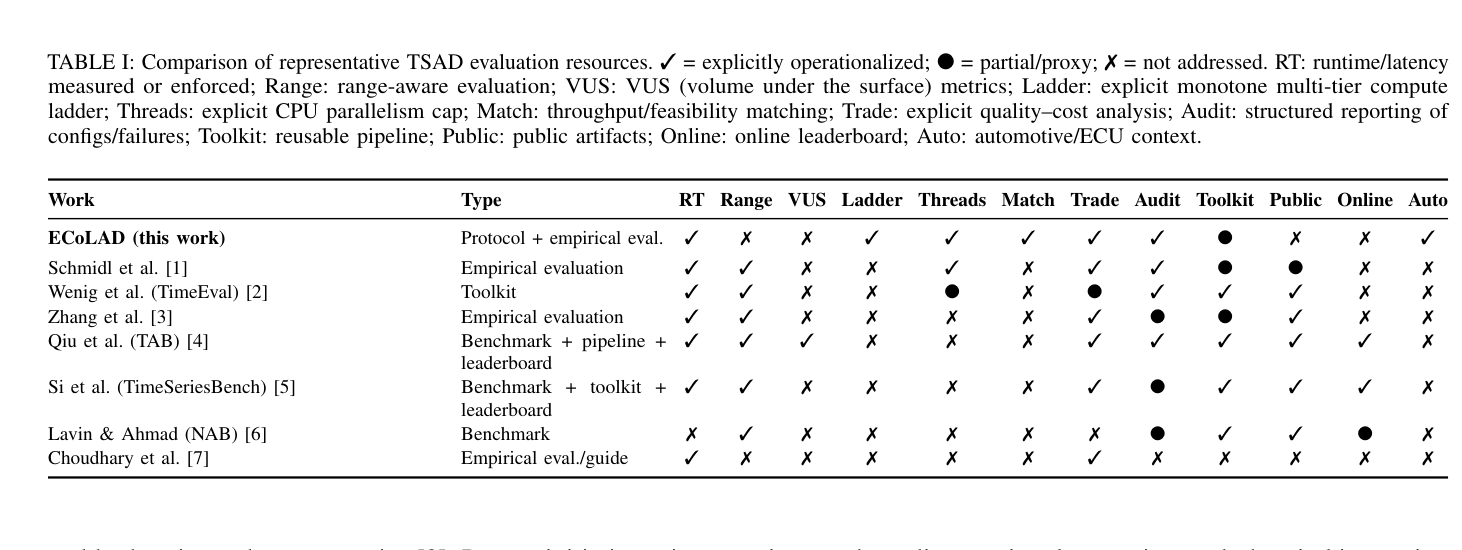 Table I: Comparison of representative TSAD evaluation resources.
Table I: Comparison of representative TSAD evaluation resources.
.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 ECOLAD 를 통해 deployment-oriented evaluation protocol을 제시합니다. 이 프로토콜은 (i) 고정된 scoring semantics, (ii) tiered scaling rules를 통한 monotone compute-reduction ladder , (iii) 명시적인 CPU thread caps , 그리고 (iv) configuration 변경 및 profiling output에 대한 auditable logging을 특징으로 합니다. 특히 compute-reduction factor s 를 사용하여 U_work = max(1, round(s*v))와 같은 기계적인 integer-only scaling rules를 적용하여 모델 capacity를 조절합니다. throughput-constrained behavior는 다양한 target scoring rate T를 sweep하여 coverage와 해당 제약 조건을 만족하는 구성 중 달성 가능한 최적의 AUC-PR을 보고함으로써 특성화됩니다
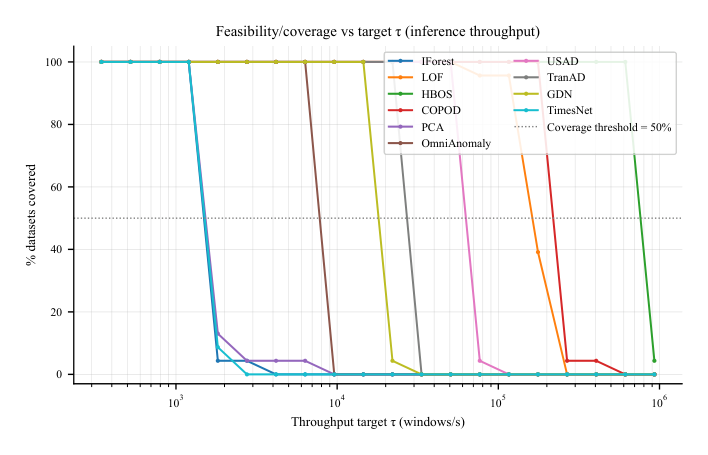 Figure 1: Throughput feasibility CDF under a fixed tier.
Figure 1: Throughput feasibility CDF under a fixed tier.
.
실험은 proprietary automotive Telemetry dataset (anomaly rate ≈ 0.022) 및 공개 벤치마크인 SMD, SMAP에서 수행되었습니다. 주요 결과는 다음과 같습니다:
- RQ1 (Cross-Tier Detection Quality): AUC-PR은 모든 tiers에서 strictly invariant하지 않으며, 변화의 크기는 method 및 domain에 따라 다릅니다
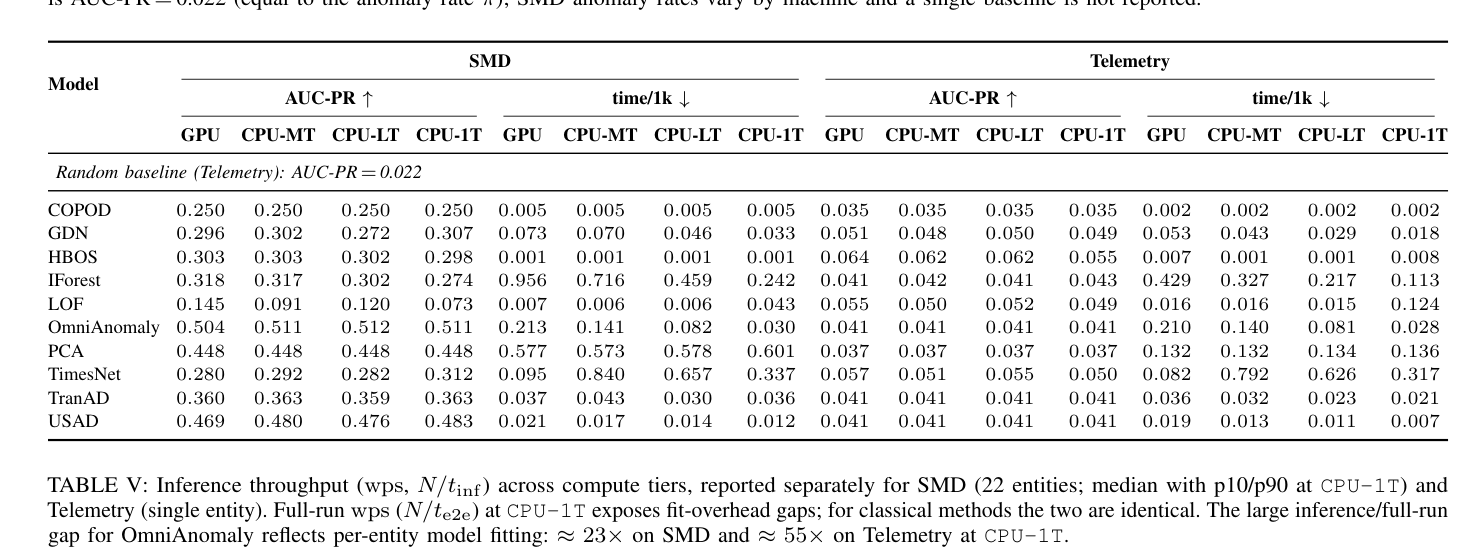 Table IV: SMD and Telemetry side-by-side AUC-PR and time/1k.
Table IV: SMD and Telemetry side-by-side AUC-PR and time/1k.
. 예를 들어, SMD에서 OmniAnomaly와 USAD는 minimal drift를 보였지만, LOF는 CPU-1T tier에서 0.145에서 0.073 AUC-PR로 현저히 저하되었습니다. Telemetry에서는 HBOS가 가장 높은 AUC-PR (0.064 on GPU, 0.055 on CPU-1T)을 달성하여 random baseline 대비 약 2.9배 높은 lift를 보였습니다. Runtime 측면에서 HBOS와 COPOD는 모든 tiers에서 ultra-low-cost (~0.001-0.005 s/1k)를 유지한 반면, TimesNet은 GPU에서 0.095 s/1k로 빨랐지만 CPU tier에서는 0.626-0.838 s/1k로 현저히 느려 backend sensitivity를 보였습니다.
- RQ2 (Degradation Modes and Bottlenecks): TimesNet은 AUC-PR 변화는 미미했으나 CPU tier에서 inference wps가 9,569 (GPU)에서 1,483 (CPU-1T)으로 급격히 감소하며 throughput-driven feasibility loss를 보였습니다. LOF는 높은 throughput을 유지하면서도 capacity reduction에 따라 AUC-PR이 크게 감소하는 quality-drift-limited degradation을 보였습니다 [Figure 2C]. HBOS와 COPOD는 높은 throughput과 일정한 AUC-PR을 유지하는 graceful degraders로 분류되었습니다. OmniAnomaly의 경우 CPU-1T tier에서 inference/full-run wps ratio가 SMD에서 약 23x, Telemetry에서 약 55x에 달하여 per-entity fitting overhead가 큼을 보여주었습니다.
- RQ3 (Throughput-Constrained Behavior on CPU-1T): Classical method들은 넓은 throughput target 범위에서 높은 coverage를 유지했지만, 일부 deep method는 높은 target에서 infeasible해졌습니다 [Figure 1]. HBOS는 가장 높은 feasible T에서도 0.042 AUC-PR을 유지했지만, 일찍 infeasible해지는 method들은 높은 throughput target에서 random baseline 이상의 operating point를 제공하지 못했습니다 [Figure 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 ECOLAD라는 새로운 evaluation protocol을 제안하여, compute reduction, CPU parallelism caps, throughput feasibility 및 auditability를 명시적으로 다루는 framework를 제공합니다. 실험 결과는 constrained execution 환경에서 accuracy ranking이 변동하며, 이는 종종 detection quality 저하보다는 architectural throughput bottlenecks에 의해 발생함을 시사합니다. 이러한 결과는 deployment 결정을 내릴 때 feasibility-first filtering approach의 중요성을 강조합니다. ECOLAD는 accuracy-only leaderboard의 한계를 보완하며, deployment-relevant 제약 조건 하에서 anomaly detector들을 비교하기 위한 표준화된 template를 제공함으로써 학계 및 산업계에 중요한 시사점을 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Fast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving
- [논문리뷰] Thinking While Speaking: Inference-Time Knowledge Transfer for Responsive and Intelligent Conversational Voice Agents
- [논문리뷰] Duration Aware Scheduling for ASR Serving Under Workload Drift
- [논문리뷰] AdaCodec: A Predictive Visual Code for Video MLLMs
- [논문리뷰] Speculative Pipeline Decoding: Higher-Accruacy and Zero-Bubble Speculation via Pipeline Parallelism
Review 의 다른글
- 이전글 [논문리뷰] Detecting Intrinsic and Instrumental Self-Preservation in Autonomous Agents: The Unified Continuation-Interest Protocol
- 현재글 : [논문리뷰] ECoLAD: Deployment-Oriented Evaluation for Automotive Time-Series Anomaly Detection
- 다음글 [논문리뷰] From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
댓글