[논문리뷰] RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yanzuo Lu, Ronglai Zuo, Jiankang Deng
1. Key Terms & Definitions (핵심 용어 및 정의)
- RAVEN (Real-time Autoregressive Video Extrapolation Network): 셀프 롤아웃(Self-rollout)을 학습 중 인터리브(Interleaved) 시퀀스로 재구성하여, 생성된 히스토리 상태가 최종 예측에 end-to-end로 감독(Supervision)받도록 설계된 학습 프레임워크입니다.
- CM-GRPO (Consistency-model Group Relative Policy Optimization): consistency sampler의 샘플링 단계를 조건부 가우시안 전이로 재정의하여, Euler-Maruyama와 같은 추가적인 확률적 프로세스 없이 policy optimization을 수행하는 강화학습 기법입니다.
- Training-time Test: 추론 시 모델이 생성하는 미래의 문맥(context)과 동일한 분포를 학습 과정에서 시뮬레이션함으로써, 추론과 학습 간의 불일치를 최소화하는 학습 전략입니다.
- Future Participation Score: 자동 회귀적(Autoregressive) 생성 과정에서 위치에 따른 정보 의존성 차이를 보정하기 위해, 각 chunk가 이후 생성되는 전체 시퀀스에 기여하는 정도를 수치화한 가중치 산출 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 고성능 양방향(Bidirectional) 비디오 확산 모델이 실시간 스트리밍 생성에는 부적합하다는 점을 해결하고자 합니다. 기존의 인과적(Causal) 자동 회귀 모델들은 학습 단계에서 사용하는 히스토리 분포와 실제 추론 시의 분포가 달라 품질이 저하되는 문제가 있습니다. 특히, 기존의 Self Forcing 방식은 롤아웃 히스토리를 분리된(detached) 컨텍스트로 취급하여, 미래 생성된 chunk의 손실(loss)이 이전 히스토리 표현에 영향을 주지 못하는 한계가 존재합니다 [Figure 1]. 이러한 학습과 추론 사이의 괴리는 모델이 장기적인 시간 지평에서 일관성을 유지하는 것을 어렵게 만듭니다.
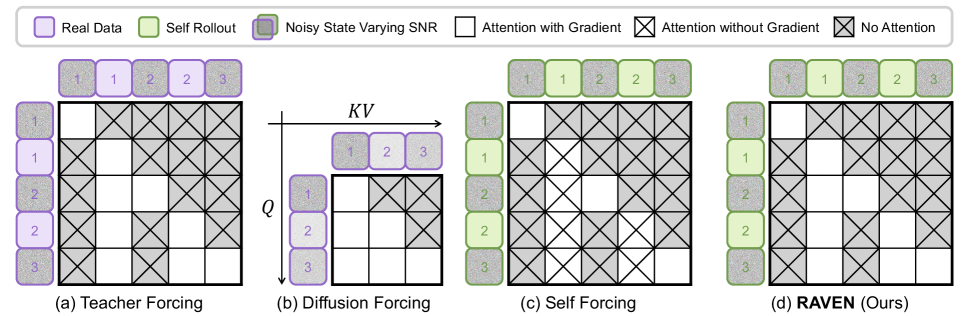
Figure 1 — 인과적 주의 집중 마스크 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 self-rollout의 출력을 깨끗한(clean) 히스토리 엔드포인트와 노이즈가 섞인(noisy) 디노이징 상태로 인터리브 배치하는 RAVEN을 제안합니다 [Figure 2]. 이를 통해 미래 chunk의 손실이 과거의 히스토리 표현(KV cache)으로 역전파(Backpropagation)되어, 추론 시점과 유사한 조건에서 모델이 학습되도록 합니다. 또한 CM-GRPO를 도입하여 consistency 샘플링 커널에 직접 정책 최적화를 적용함으로써, 추론 과정과 학습 과정의 정합성을 높였습니다. 실험 결과, RAVEN은 기존의 CausVid나 Causal Forcing과 같은 베이스라인 대비 Total Score 및 Dynamic Degree에서 우수한 성능을 입증했습니다 [Table 1]. 특히, RAVEN과 CM-GRPO를 결합했을 때 모든 평가 지표에서 가장 높은 정량적 수치를 기록하며 구조적 일관성과 동적 품질을 동시에 확보했습니다 [Table 1].
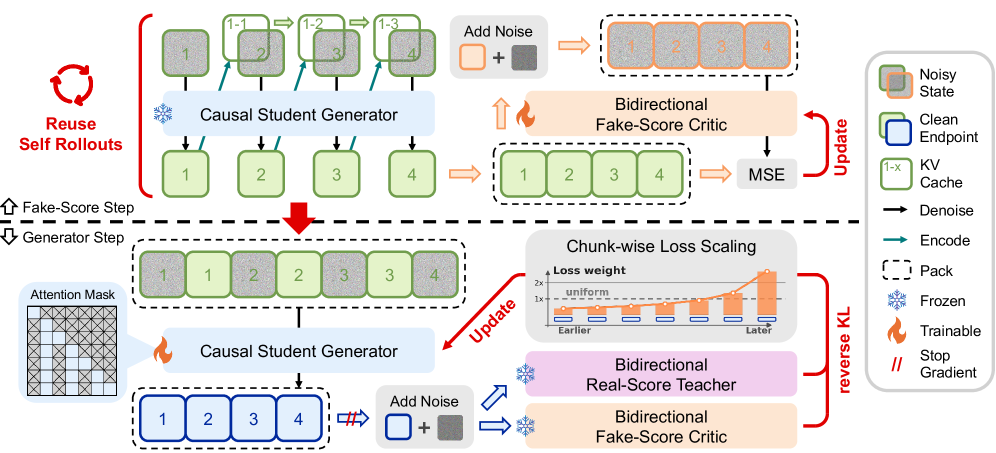
Figure 2 — RAVEN의 학습 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 자동 회귀적 비디오 생성에서 학습-추론 분포 불일치 문제와 히스토리 감독 결여 문제를 성공적으로 해결하였습니다. 제안된 RAVEN과 CM-GRPO는 실시간 스트리밍 생성 환경에서도 고품질의 일관성 있는 비디오를 생성할 수 있음을 보여주었습니다. 이 연구는 비디오 생성 모델의 효율적인 훈련 방식을 제시함과 동시에, 강화학습을 결합한 consistency 모델의 최적화 표준을 확립함으로써 향후 인터랙티브한 비디오 world model 연구에 중요한 기반을 마련할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
- [논문리뷰] Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
- [논문리뷰] TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
- [논문리뷰] Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
Review 의 다른글
- 이전글 [논문리뷰] Quantitative Video World Model Evaluation for Geometric-Consistency
- 현재글 : [논문리뷰] RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
- 다음글 [논문리뷰] Realiz3D: 3D Generation Made Photorealistic via Domain-Aware Learning
댓글