[논문리뷰] MemReread: Enhancing Agentic Long-Context Reasoning via Memory-Guided Rereading
링크: 논문 PDF로 바로 열기
메타데이터
저자: Baibei Ji, Xiaoyang Weng, Juntao Li, Zecheng Tang, Yihang Lou, Min Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Memorize-while-reading: 긴 문서를 여러 chunk로 분할하여 순차적으로 읽으면서 기억(Memory)을 동적으로 업데이트하는 패러다임입니다.
- Latent Evidence Loss: 초기 chunk에서 중요도가 낮다고 판단되어 폐기된 정보가, 추후 문맥에서 핵심적인 역할을 하게 될 때 이를 복구하지 못하는 현상입니다.
- Rereading-Adaptive GRPO: 작업의 난이도에 따라 rereading 횟수를 동적으로 조절하여 효율성을 최적화하는 보상 기반 강화학습 프레임워크입니다.
- Retrieval-Augmented Memory Agents (RA-MemAgents): 기존 memory agent의 한계를 극복하기 위해 기억을 검색(Retrieval)하는 모듈을 통합한 에이전트 구조입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 long-context reasoning 모델들이 겪는 '정보의 영구적 손실'과 '무분별한 검색으로 인한 노이즈 유입' 문제를 해결하기 위해 MemReread를 제안한다. 기존 retrieval 기반 에이전트는 검색 쿼리의 부정확성과 불필요한 검색으로 인해 핵심 신호가 희석되는 한계를 가진다 [Figure 1]. 또한, 단순히 기억(Memory)에만 의존하는 방식은 비선형적인 추론을 수행하거나 과거에 폐기된 정보를 다시 불러오는 데 구조적인 제약이 존재한다. 저자들은 이러한 한계를 극복하기 위해 검색 기반이 아닌, 필요한 경우에만 문맥을 다시 읽는(Rereading) 능동적인 전략이 필수적이라고 주장한다 [Figure 2].
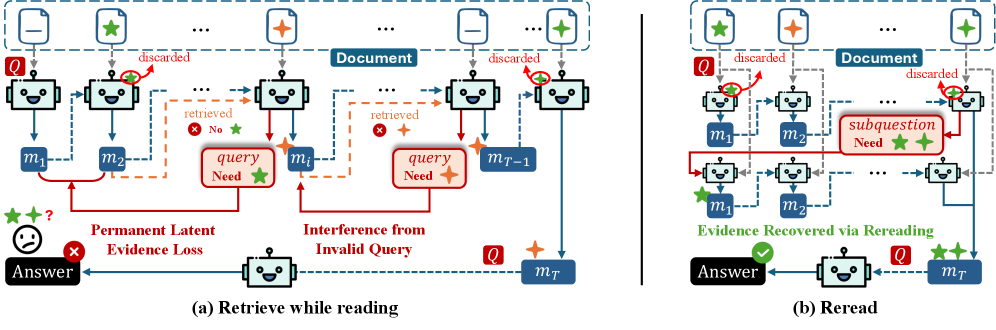
Figure 1 — 기존 검색 방식의 한계와 MemReread의 개선점
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Read, Decompose, Integrate, Answer로 이어지는 4단계의 워크플로우를 가진 MemReread 프레임워크를 제안한다 [Figure 4]. 이 모델은 초기 독해(Read) 단계 후 기억 상태가 불충분하다고 판단되면, 문제 해결을 위한 하위 질문(Sub-question)을 생성하고 대상 정보를 다시 읽는(Rereading) 과정을 반복한다. 특히 Rereading-Adaptive GRPO를 도입하여, 모델이 불필요한 rereading을 최소화하면서도 작업 난이도에 적합한 횟수를 스스로 결정하도록 학습시킨다 [Figure 5]. 실험 결과, MemReread는 2WikiMultiHopQA 벤치마크 등에서 기존 Baseline 대비 괄목할 만한 성능 향상을 보였으며, 4B 규모의 모델에서 기존 최고의 성능을 보였던 ReMemR1 대비 최대 12.1% 높은 정확도를 기록하였다 [Table 1]. 또한, 테스트 시간 오버헤드와 메모리 사용량 측면에서 선형적인 시간 복잡도 **O(pc*n)**을 유지하며 높은 실용성을 입증하였다 [Figure 6].
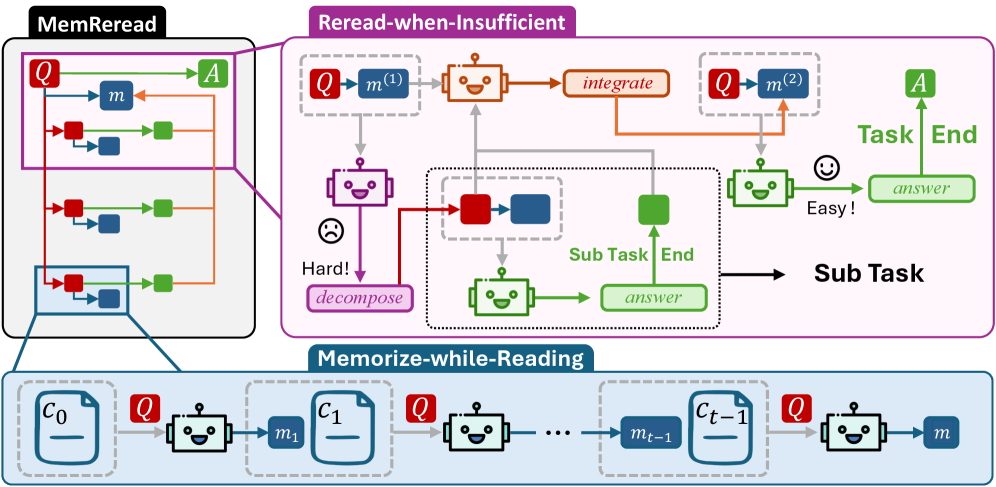
Figure 4 — MemReread 전체 워크플로우
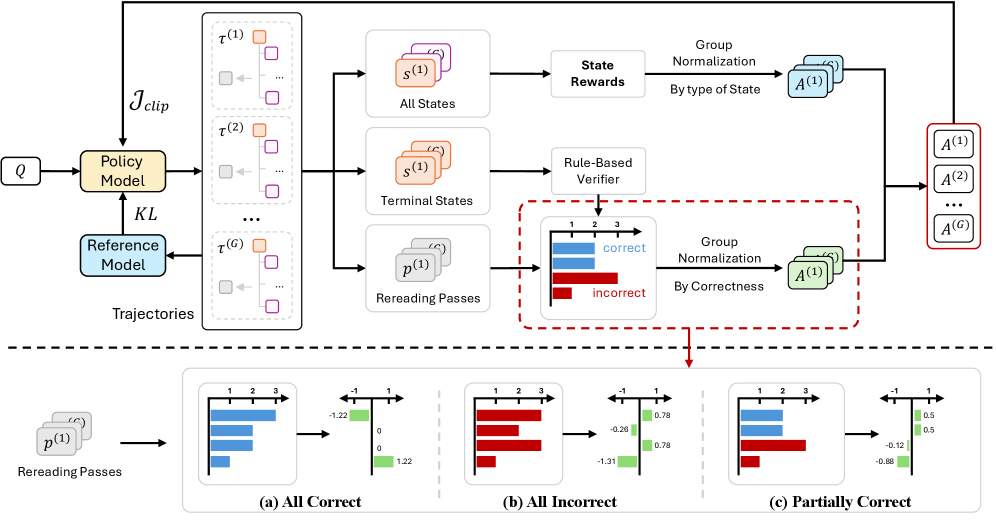
Figure 5 — Rereading-Adaptive 보상 설계
4. Conclusion & Impact (결론 및 시사점)
본 논문은 streaming reading 패러다임 내에서 지능적인 rereading 메커니즘을 통해 장문맥 추론 성능을 비약적으로 향상시킨 MemReread를 성공적으로 제시하였다. 이 연구는 기존 retrieval 방식의 의존도를 낮추고 에이전트의 내부적인 추론 및 복구 능력을 강화함으로써 long-context LLM의 효율성을 새로운 차원으로 끌어올렸다. 본 논문에서 제시한 Rereading-Adaptive 강화학습 프레임워크는 향후 에이전트의 컴퓨팅 리소스 관리와 추론 신뢰성을 높이는 학계 및 산업계 연구에 핵심적인 토대가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
- [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
- [논문리뷰] Learning User Simulators with Turing Rewards
Review 의 다른글
- 이전글 [논문리뷰] MAP: A Map-then-Act Paradigm for Long-Horizon Interactive Agent Reasoning
- 현재글 : [논문리뷰] MemReread: Enhancing Agentic Long-Context Reasoning via Memory-Guided Rereading
- 다음글 [논문리뷰] MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
댓글