[논문리뷰] MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
링크: 논문 PDF로 바로 열기
메타데이터
저자: Alan Arazi, Eilam Shapira, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MMTL (Multimodal Tabular Learning): 수치 및 범주형 데이터와 같은 구조화된 데이터와 텍스트, 이미지와 같은 비정형 데이터를 결합하여 학습하는 예측 태스크.
- TAR (Target-Aware Representations): 사전 학습된 범용 임베딩 모델을 downstream 태스크의 타겟(Label)에 맞춰 파인튜닝하여, 태스크 수행에 필수적인 세밀한 정보를 보존하도록 개선된 임베딩.
- TFM (Tabular Foundation Model): 대규모 데이터로 사전 학습되어 범용적인 수치형 데이터 표현을 학습한 모델로, 최근 수치형 데이터 학습에서 SOTA 성능을 기록 중임.
- Joint Signal: 멀티모달 환경에서 각 모달리티가 상호 보완적인 정보를 제공하여, 단일 모달리티만을 사용했을 때보다 예측 성능이 향상되는 특성.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 멀티모달 학습에서 기존 연구들이 정형 데이터와 비정형 데이터의 결합을 단순한 '동시 발생'으로만 취급하여 최적의 예측 성능을 내지 못하고 있다는 문제에서 출발한다 [Figure 1]. 기존의 TFM은 수치형 데이터에 특화되어 있어 비정형 데이터(텍스트, 이미지)를 처리할 때 단순히 외부에서 추출한 '고정된(Frozen)' 임베딩을 사용하는데, 이는 범용적인 의미 정보만 담고 있어 태스크 특화된 세밀한 신호를 소실시킨다. 저자들은 이러한 제약이 실제 멀티모달 태스크에서 고성능을 저해하는 핵심 원인이라고 지적한다. 따라서 본 논문은 이러한 태스크 특화 정보를 보존할 수 있는 TAR의 필요성을 입증하고, 이를 평가하기 위한 체계적인 벤치마크 데이터셋 구축을 목표로 한다.
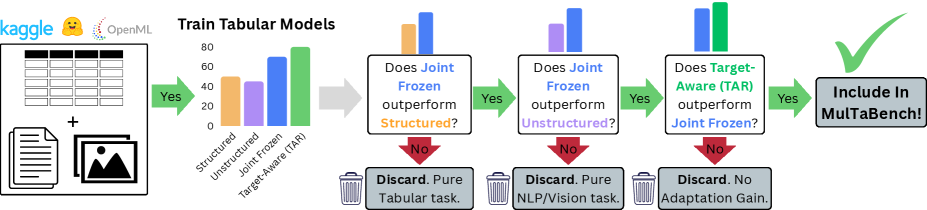
Figure 1 — MulTaBench 큐레이션 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 멀티모달 멀티태스크 환경을 분석하기 위해 MulTaBench라는 40개의 데이터셋으로 구성된 대규모 벤치마크를 구축하고, 이를 검증하는 알고리즘 파이프라인을 제안한다 [Figure 1]. 제안하는 평가 프로토콜은 데이터셋이 'Joint Signal'을 가지는지, 그리고 'Task-awareness'를 요구하는지(즉, TAR 적용 시 성능이 개선되는지)를 기준으로 데이터셋을 엄격히 필터링한다. 실험에서는 LightGBM, CatBoost, TabPFNv2 등 5종의 tabular learner를 활용하여 정량적 평가를 수행하였다. 주요 결과로, 모든 데이터셋에서 Frozen 임베딩 대비 TAR 적용 시 예측 성능(AUC 및 $R^2$)이 유의미하게 향상됨을 확인하였다 [Figure 3]. 또한, 이러한 성능 향상은 모델의 규모, 임베딩 차원, 인코더 크기 등 다양한 환경에서 강건하게 일반화됨을 입증하였다 [Figure 4, Figure 6]. 특히, 이미지 데이터셋의 경우 DINO-v3의 attention map을 시각화하여 TAR가 일반적인 글로벌 정보를 넘어 태스크와 밀접한 국소적 특징(예: 병변 위치)으로 인코더의 초점을 이동시키는 것을 정성적으로 확인하였다 [Figure 7].
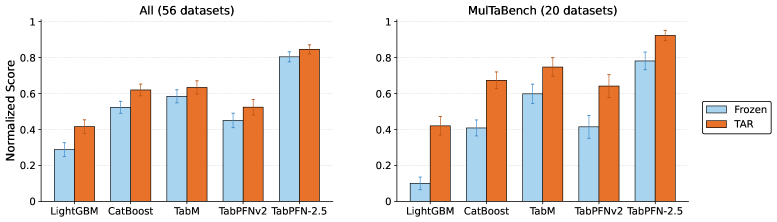
Figure 3 — Frozen 대비 TAR의 성능 향상
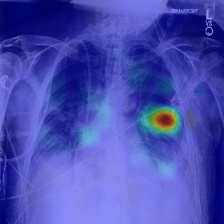
Figure 7 — TAR 적용 전후의 어텐션 맵 변화
4. Conclusion & Impact (결론 및 시사점)
본 논문은 멀티모달 정형 데이터 학습의 핵심이 '태스크 맞춤형 임베딩(TAR)'에 있음을 밝히고, 이를 연구하기 위한 표준 벤치마크인 MulTaBench를 제시하였다. 이는 기존의 범용 임베딩 방식이 가진 한계를 정량적으로 증명하였으며, 향후 멀티모달 TFM(Tabular Foundation Models)이 나아가야 할 방향성을 제시하였다. 본 연구는 의료, 이커머스 등 멀티모달 데이터 비중이 높은 고부가가치 산업 분야에서 예측 모델의 성능을 극대화하는 데 기여할 것으로 기대된다. 또한, 저자들이 제안한 데이터셋 필터링 및 벤치마킹 파이프라인은 향후 해당 분야의 연구가 단순한 모델링 기법 경쟁을 넘어 데이터의 본질적 특성을 이해하는 방향으로 진화하는 데 밑거름이 될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond IID: How General Are Tabular Foundation Models, Really?
- [논문리뷰] TabTune: A Unified Library for Inference and Fine-Tuning Tabular Foundation Models
- [논문리뷰] Estimating Time Series Foundation Model Transferability via In-Context Learning
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
Review 의 다른글
- 이전글 [논문리뷰] MemReread: Enhancing Agentic Long-Context Reasoning via Memory-Guided Rereading
- 현재글 : [논문리뷰] MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
- 다음글 [논문리뷰] PersonalAI 2.0: Enhancing knowledge graph traversal/retrieval with planning mechanism for Personalized LLM Agents
댓글